

In the previous post of the Gemma explained series, we discussed the Gemma architecture. In this post, you will explore the latest model, Gemma 2. Let’s get started!
Recently, we released Gemma 2, our groundbreaking new suite of open models, setting a new standard for performance and accessibility. Available in 2B, 9B, and 27B parameter sizes, Gemma 2 has quickly made its mark. Our 27B model rapidly ascended the LMSYS Chatbot Arena leaderboard, surpassing even popular models more than twice its size in engaging, real-world conversations, establishing itself as one of the highest-ranking and most useful open models. Meanwhile, the Gemma 2 2B model showcases its exceptional conversational AI prowess by outperforming all GPT-3.5 models on the Chatbot Arena at a size runnable on edge devices.
Developers can access robust tuning capabilities with Gemma 2 across platforms and tools. Fine-tuning Gemma 2 is simplified with cloud-based solutions like Google Cloud and community tools like Axolotl. Seamless integration with partners such as Hugging Face and NVIDIA TensorRT-LLM, as well as our JAX and Keras, enables optimization of performance and efficient deployment across diverse hardware configurations.
Here’s the core parameters of the new models:
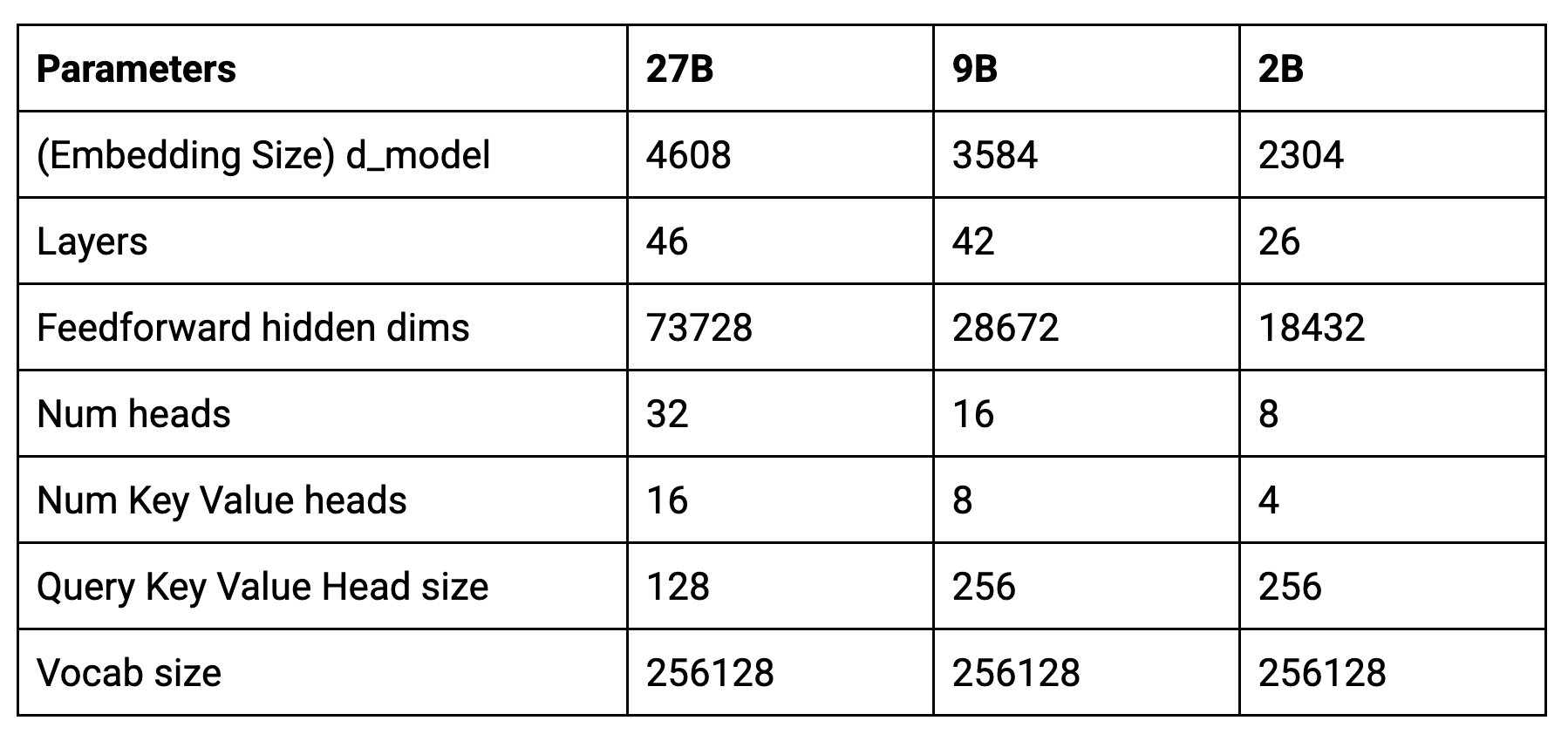
Gemma 2 shares a similar architectural foundation with the original Gemma models, including the implementation of Rotary Positioning Embeddings (RoPE) and the approximated GeGLU non-linearity. However, it introduces novel architectural innovations that set it apart from its predecessors.
Instead of considering all words in a text at once, it sometimes focuses on a small window of words (local attention) and sometimes considers all words (global attention). This combination helps the model understand both the immediate context and the overall meaning of the text efficiently.
Imagine you are training a model to predict the next word in a sentence. Sometimes, the model might be overly confident about a particular word, even if it’s not the best choice. Logit soft-capping prevents this by limiting how confident the model can be about its predictions, leading to better overall performance.
Think of this as a way to keep the model’s calculations from becoming too large or too small during training. Just like we might adjust the volume on a speaker to prevent distortion, RMSNorm ensures that the information flowing through the model stays within a reasonable range, leading to more stable and effective training.
This technique helps the model process information more efficiently, especially when dealing with large amounts of text. It improves upon traditional multi-head attention(MHA) by grouping queries together, enabling faster processing, especially for large models. It’s like dividing a large task into smaller, more manageable chunks, allowing the model to understand the relationships between words faster without sacrificing accuracy.
Gemma2ForCausalLM(
(model): Gemma2Model(
(embed_tokens): Embedding(256000, 4608, padding_idx=0)
(layers): ModuleList(
(0-45): 46 x Gemma2DecoderLayer(
(self_attn): Gemma2SdpaAttention(
(q_proj): Linear(in_features=4608, out_features=4096, bias=False)
(k_proj): Linear(in_features=4608, out_features=2048, bias=False)
(v_proj): Linear(in_features=4608, out_features=2048, bias=False)
(o_proj): Linear(in_features=4096, out_features=4608, bias=False)
(rotary_emb): Gemma2RotaryEmbedding()
)
(mlp): Gemma2MLP(
(gate_proj): Linear(in_features=4608, out_features=36864, bias=False)
(up_proj): Linear(in_features=4608, out_features=36864, bias=False)
(down_proj): Linear(in_features=36864, out_features=4608, bias=False)
(act_fn): PytorchGELUTanh()
)
(input_layernorm): Gemma2RMSNorm()
(post_attention_layernorm): Gemma2RMSNorm()
(pre_feedforward_layernorm): Gemma2RMSNorm()
(post_feedforward_layernorm): Gemma2RMSNorm()
)
)
(norm): Gemma2RMSNorm()
)
(lm_head): Linear(in_features=4608, out_features=256000, bias=False)
)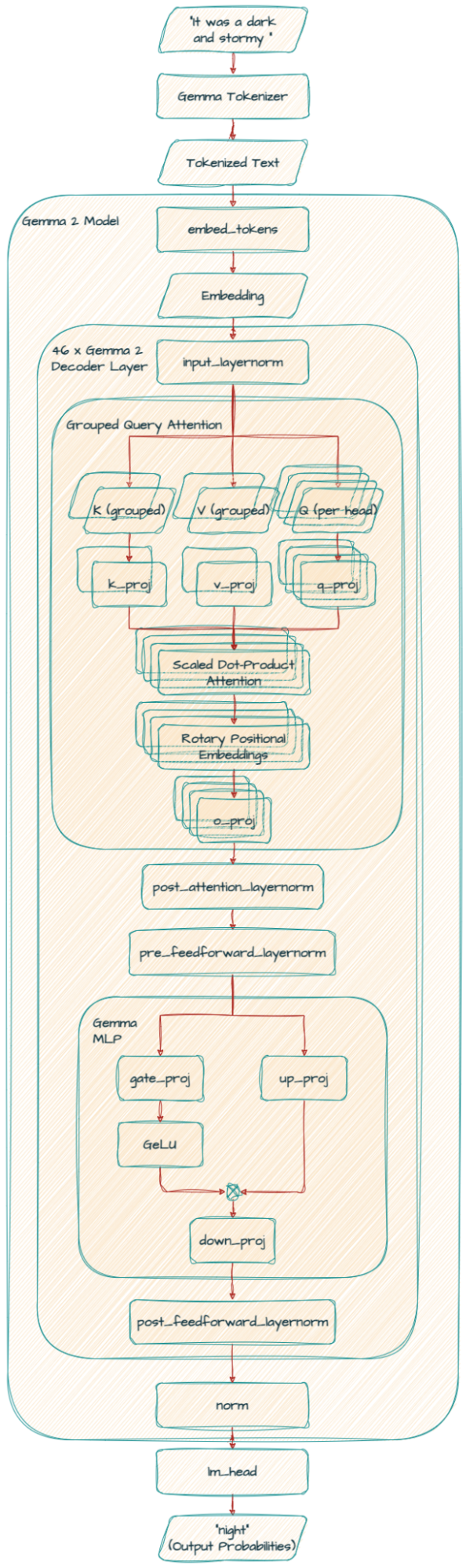
In the self-attention mechanism, Gemma 2 uses Grouped Query Attention (GQA).
k_proj and v_proj share the same head with a size of 128 and 16 heads (128 x 16 = 2048). In contrast, q_proj and o_proj have 32 heads (128 x 32 = 4096) in parallel.
Note that the Gemma 9B model uses the Same GQA but different number of heads(8 for k_proj and v_proj, 16 for q_proj and o_proj) and head size (256)
(self_attn): Gemma2SdpaAttention(
(q_proj): Linear(in_features=3584, out_features=4096, bias=False)
(k_proj): Linear(in_features=3584, out_features=2048, bias=False)
(v_proj): Linear(in_features=3584, out_features=2048, bias=False)
(o_proj): Linear(in_features=4096, out_features=3584, bias=False)
(rotary_emb): Gemma2RotaryEmbedding()
)The 2B model uses 4 for k_proj and v_proj, 8 for q_proj and o_proj and head size (256)
Another significant distinction is the inclusion of additional RMSNorm in Gemma 2, which enhances the stability of the training process.
Our technical report provides in-depth details, but here's a quick summary of Gemma 2's main findings:
We trained the 2B and 9B models with knowledge distillation from the larger model (27B).
Distilling knowledge from a larger model, even with an equal number of training tokens, leads to significant performance enhancements.
Replacing MHA with GQA results in comparable performance while offering parameter efficiency and faster inference times, making GQA the preferred choice.
A deeper model showcases slightly superior performance compared to a wider model with the same parameter count.
In this article, you learned about Gemma 2, the next generation of Gemma models.
In our next series of posts, you will examine the RecurrentGemma which is an open model based on Griffin.
If you want to delve into the fascinating world of AI and gain insights from the experts who are shaping its development, head over to goo.gle/ai-podcast or search for the show “People of AI Podcast” on any podcast platform.
Stay tuned and thank you for reading!

Announcing ADK for Java 1.0.0: Building the Future of AI Agents in Java

Introducing EmbeddingGemma: The Best-in-Class Open Model for On-Device Embeddings

Introducing Gemma 3 270M: The compact model for hyper-efficient AI

Closing the knowledge gap with agent skills

Introducing Metrax: performant, efficient, and robust model evaluation metrics in JAX
Introducing Coral NPU: A full-stack platform for Edge AI