

Gemma 徹底解説シリーズの前回の投稿では、Gemma のアーキテクチャについて説明しました。今回の投稿では、最新モデル Gemma 2 について説明します。さっそく始めましょう!
先日リリースされた Gemma 2 は、一連の新しい画期的なオープンモデルで、パフォーマンスとアクセシビリティの新たな基準を打ち立てています。Gemma 2 は 2B、9B、27B のパラメータ サイズで利用でき、すぐに評判になりました。27B モデルは、LMSYS Chatbot Arena のリーダーボードを急上昇し、現実世界で魅力的な会話を行う能力において、2 倍以上のサイズの人気モデルさえも凌駕し、特に有用な最高ランクのオープンモデルの 1 つとしての地位を確立しています。一方の Gemma 2 2B モデルも、比類ない会話型 AI 性能を示しており、エッジデバイスで実行可能なサイズにおいて、Chatbot Arena のすべての GPT-3.5 モデルを上回るパフォーマンスを発揮しています。
デベロッパーは、あらゆるプラットフォームやツールを通して Gemma 2 の堅牢なチューニング機能にアクセスできます。Gemma 2 のファイン チューニングは、Google Cloud や Axolotl をはじめとするコミュニティ ツールなど、クラウドベースのソリューションを使って簡単に行うことができます。Hugging Face、NVIDIA TensorRT-LLM、JAX、Keras などのパートナーとシームレスに連携できるので、さまざまなハードウェア構成でパフォーマンスの最適化や効率的なデプロイを実現できます。
新しいモデルのコアパラメータは次のとおりです。
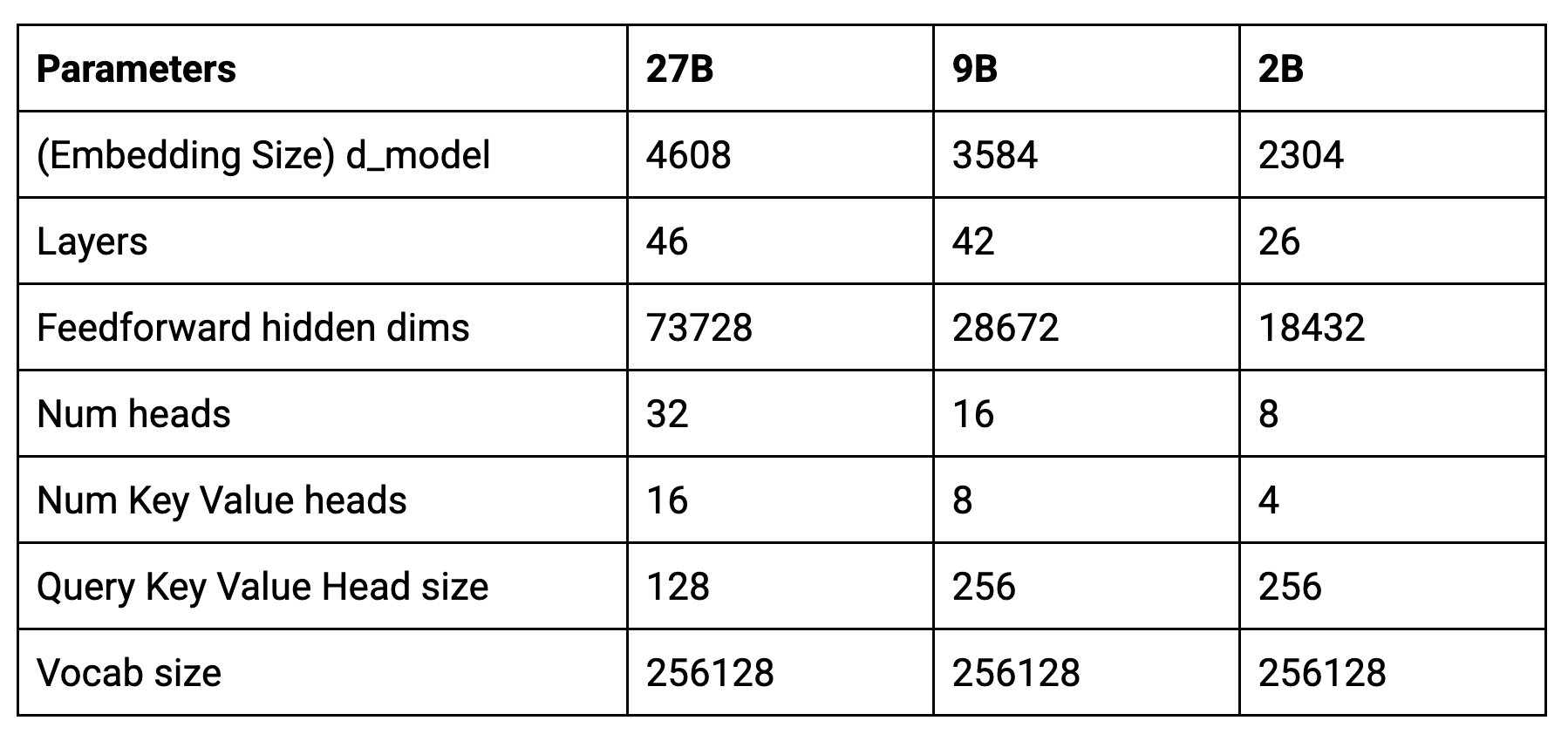
Gemma 2 は、ロータリー位置埋め込み(RoPE)や近似 GeGLU 非線形性の実装など、オリジナルの Gemma モデルと同じアーキテクチャ基盤を共有しています。しかし、前身のモデルとは一線を画す斬新で画期的なアーキテクチャも導入されています。
テキストのすべての単語を一度に考慮するのではなく、あるときは単語の小さな範囲(ローカル アテンション)に注目し、またあるときはすべての単語(グローバル アテンション)を考慮します。この組み合わせによって、モデルがテキストの直接的な文脈と全体的な意味の両方を効率的に理解できるようになります。
モデルをトレーニングし、文の次の単語を予測させることを考えてみてください。モデルは、それが最善の選択ではないにもかかわらず、特定の単語に過度に自信を持つ場合があります。ロジット ソフトキャッピングは、これを防ぐために、予測の信頼度に上限を設けます。これにより、全体的なパフォーマンスが向上します。
これは、トレーニング中にモデルの計算が大きすぎたり小さすぎたりしないようにする方法だと考えてください。スピーカーの音量を調整して歪みを防ぐのと同じく、RMSNorm はモデルを流れる情報を合理的な範囲内に保ちます。これにより、トレーニングの安定性と効率が向上します。
この技術により、特に大量のテキストを扱う場合に、モデルが効率的に情報を処理できるようになります。クエリをグループ化することで、従来のマルチヘッド アテンション(MHA)を改善し、特に大型モデルの処理を高速化します。大きなタスクを小さく管理しやすい塊に分割するようなもので、正確さを犠牲にすることなく、モデルの単語間の関係の理解を高速化します。
Gemma2ForCausalLM(
(model): Gemma2Model(
(embed_tokens): Embedding(256000, 4608, padding_idx=0)
(layers): ModuleList(
(0-45): 46 x Gemma2DecoderLayer(
(self_attn): Gemma2SdpaAttention(
(q_proj): Linear(in_features=4608, out_features=4096, bias=False)
(k_proj): Linear(in_features=4608, out_features=2048, bias=False)
(v_proj): Linear(in_features=4608, out_features=2048, bias=False)
(o_proj): Linear(in_features=4096, out_features=4608, bias=False)
(rotary_emb): Gemma2RotaryEmbedding()
)
(mlp): Gemma2MLP(
(gate_proj): Linear(in_features=4608, out_features=36864, bias=False)
(up_proj): Linear(in_features=4608, out_features=36864, bias=False)
(down_proj): Linear(in_features=36864, out_features=4608, bias=False)
(act_fn): PytorchGELUTanh()
)
(input_layernorm): Gemma2RMSNorm()
(post_attention_layernorm): Gemma2RMSNorm()
(pre_feedforward_layernorm): Gemma2RMSNorm()
(post_feedforward_layernorm): Gemma2RMSNorm()
)
)
(norm): Gemma2RMSNorm()
)
(lm_head): Linear(in_features=4608, out_features=256000, bias=False)
)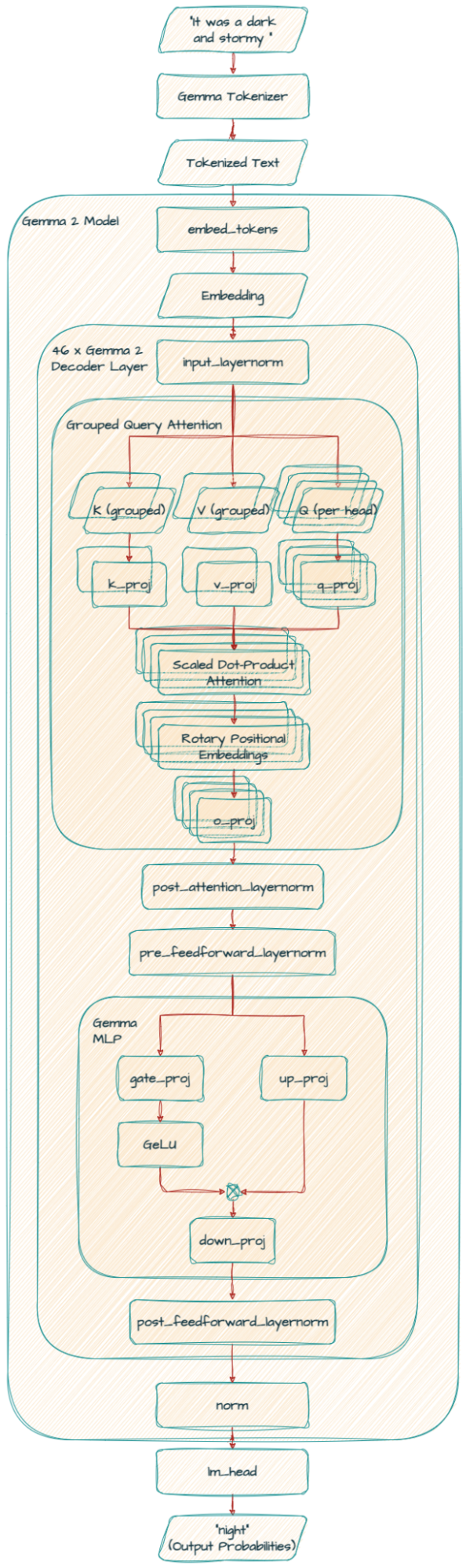
Gemma 2 は、セルフアテンション メカニズムにグループ化クエリ アテンション(GQA)を使います。
k_proj と v_proj は、サイズが 128 の同じヘッド 16 個を共有します(128 x 16 = 2048)。逆に、q_proj と o_proj には、並列に動作する 32 個のヘッドがあります(128 x 32 = 4096)。
Gemma 9B モデルも同じ GQA を利用しますが、ヘッド数(k_proj と v_proj は 8、q_proj と o_proj は 16)とヘッドのサイズ(256)が異なります。
(self_attn): Gemma2SdpaAttention(
(q_proj): Linear(in_features=3584, out_features=4096, bias=False)
(k_proj): Linear(in_features=3584, out_features=2048, bias=False)
(v_proj): Linear(in_features=3584, out_features=2048, bias=False)
(o_proj): Linear(in_features=4096, out_features=3584, bias=False)
(rotary_emb): Gemma2RotaryEmbedding()
)2B モデルは、k_proj と v_proj に 4、q_proj と o_proj に 8、そしてヘッドサイズ(256)を使っています。
もう 1 つの重要な違いは、Gemma 2 には RMSNorm が追加されている点です。これにより、トレーニング プロセスの安定性が高まります。
テクニカル レポートに詳しく記載されていますが、Gemma 2 から得られた主な知見は次のとおりです。
2B および 9B モデルは、大きなモデル(27B)からの知識の蒸留によってトレーニングを行いました。
大きなモデルから知識を蒸留すると、同じ数のトレーニング トークンしか使わなくても、パフォーマンスが大幅に向上します。
MHA を GQA に置き換えることで、同等のパフォーマンスを維持しながら、パラメータ効率が上がり、推論時間が高速になります。そのため、GQA は最適な選択肢となります。
同じパラメータ数では、深いモデルの方が広いモデルよりもわずかに優れたパフォーマンスを発揮します。
この記事では、次世代の Gemma モデルである Gemma 2 について説明しました。
シリーズの次の投稿では、Griffin ベースのオープンモデルである RecurrentGemma について説明します。
すばらしい AI の世界を探求し、それを発展させている専門家から知見を得たい方は、goo.gle/ai-podcast にアクセスするか、お好みのポッドキャスト プラットフォームで番組「People of AI Podcast」を検索してください。
今後の投稿にご期待ください。お読みいただきありがとうございました。

EmbeddingGemma の概要: オンデバイス埋め込み処理向けの最高水準オープンモデル

Building with Gemini 3 in Jules
Coral NPU のご紹介: エッジ AI 向けフルスタック プラットフォーム

Gemma 3 270M の概要: 超高効率 AI のためのコンパクト モデル

Announcing the Data Commons Gemini CLI extension

Introducing Metrax: performant, efficient, and robust model evaluation metrics in JAX