
140 results
APRIL 17, 2026 / Mobile
A2UI v0.9 introduces a framework-agnostic standard designed to help AI agents generate real-time, tailored UI widgets using a company’s existing design system. This update simplifies the developer experience with a new Agent SDK for Python, a shared web-core library, and official support for renderers like React, Flutter, and Angular. By decoupling UI intent from specific platforms, the release enables seamless, low-latency streaming of generative interfaces across web and mobile applications. Integrating with broader ecosystems like AG2 and Vercel, A2UI v0.9 aims to move generative UI from experimental demos to production-ready digital products.

APRIL 14, 2026 / AI
The Google Cloud AI Agent Bake-Off highlights a shift from simple prompt engineering to rigorous agentic engineering, emphasizing that production-ready AI requires a modular, multi-agent architecture. The post outlines five key developer tips, including decomposing complex tasks into specialized sub-agents and using deterministic code for execution to prevent probabilistic errors. Furthermore, it advises developers to prioritize multimodality and open-source protocols like MCP to ensure agents are scalable, integrated, and future-proof against rapidly evolving model capabilities.

APRIL 7, 2026 / AI
TorchTPU is a new engineering stack designed to provide a native, high-performance experience for running PyTorch workloads on Google’s TPU infrastructure with minimal code changes. It features an "Eager First" approach with multiple execution modes and utilizes the XLA compiler to optimize distributed training across massive clusters. Moving into 2026, the project aims to further reduce compilation overhead and expand support for dynamic shapes and custom kernels to ensure seamless scalability for the next generation of AI.

APRIL 2, 2026 / Mobile
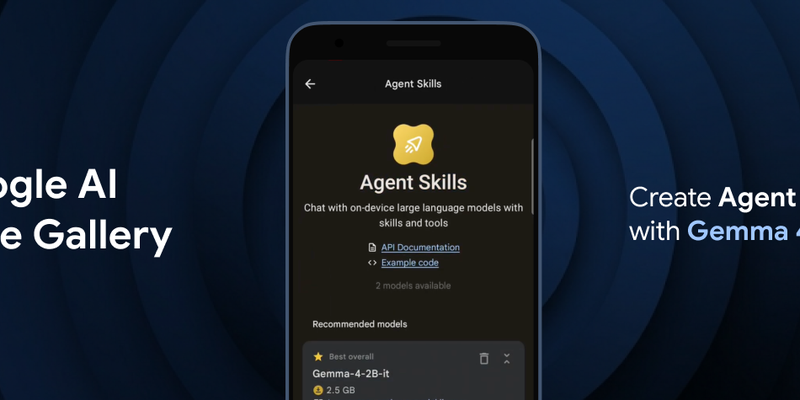
Google DeepMind has launched Gemma 4, a family of state-of-the-art open models designed to enable multi-step planning and autonomous agentic workflows directly on-device. The release includes the Google AI Edge Gallery for experimenting with "Agent Skills" and the LiteRT-LM library, which offers a significant speed boost and structured output for developers. Available under an Apache 2.0 license, Gemma 4 supports over 140 languages and is compatible with a wide range of hardware, including mobile devices, desktops, and IoT platforms like Raspberry Pi.
APRIL 2, 2026 / Web
Google has updated its account settings to allow U.S. users to change their @gmail.com usernames while keeping all existing account data and inboxes intact. For developers, this means that while old email addresses will remain active as aliases, apps that rely solely on email addresses for identification may face issues with account duplication or lost access. To ensure a seamless user experience, Google recommends migrating to the "subject ID" as the primary user identifier and allowing users to manually update their contact information within app settings.
APRIL 1, 2026 / AI
The Agent Development Kit (ADK) SkillToolset introduces a "progressive disclosure" architecture that allows AI agents to load domain expertise on demand, reducing token usage by up to 90% compared to traditional monolithic prompts. Through four distinct patterns—ranging from simple inline checklists to "skill factories" where agents write their own code—the system enables agents to dynamically expand their capabilities at runtime using the universal agentskills.io specification. This modular approach ensures that complex instructions and external resources are only accessed when relevant, creating a scalable and self-extending framework for modern AI development.

MARCH 31, 2026 / AI
The launch of Agent Development Kit (ADK) for Go 1.0 marks a significant shift from experimental AI scripts to production-ready services by prioritizing observability, security, and extensibility. Key updates include native OpenTelemetry integration for deep tracing, a new plugin system for self-healing logic, and "Human-in-the-Loop" confirmations to ensure safety during sensitive operations. Additionally, the release introduces YAML-based configurations for rapid iteration and refined Agent2Agent (A2A) protocols to support seamless communication across different programming languages. This framework empowers developers to build complex, reliable multi-agent systems using the high-performance engineering standards of Golang.

MARCH 30, 2026 / AI
Google has released version 1.0.0 of the Agent Development Kit (ADK) for Java, introducing powerful new features like Google Maps grounding, built-in URL fetching, and a standardized Agent2Agent protocol for cross-framework collaboration. The update enhances agent control through a new "App" and "Plugin" architecture, which allows for global logging, automated context window management via event compaction, and "Human-in-the-Loop" workflows for action confirmations. Additionally, the release provides robust session and memory services using Google Cloud integrations like Firestore and Vertex AI to manage long-term state and large data artifacts.

MARCH 25, 2026 / AI
To bridge the gap between static model knowledge and rapidly evolving software practices, Google DeepMind developed a "Gemini API developer skill" that provides agents with live documentation and SDK guidance. Evaluation results show a massive performance boost, with the gemini-3.1-pro-preview model jumping from a 28.2% to a 96.6% success rate when equipped with the skill. This lightweight approach demonstrates how giving models strong reasoning capabilities and access to a "source of truth" can effectively eliminate outdated coding patterns.

MARCH 24, 2026 / Mobile
The provided workflow streamlines motion-controlled game development by using Gemini Canvas to rapidly prototype mechanics like the MediaPipe Pose Landmarker through high-level prompting. Developers can refine these prototypes in Google AI Studio by optimizing for low-latency "lite" models and stable tracking points, such as shoulder landmarks, to ensure responsive gameplay. The process concludes by using Gemini Code Assist to refactor experimental code into a modular, production-ready application capable of supporting various multimodal inputs.
