

The current landscape of Large Language Model (LLM) acceleration is dominated by autoregressive speculative decoding, where a lightweight drafter predicts tokens sequentially before target verification. However, this serial drafting approach introduces a fundamental execution bottleneck: it requires K sequential forward passes to generate K candidate tokens. This step-by-step dependency forces the system to wait for each token to be predicted before starting the next, inherently limiting the speedup potential of the drafting phase. To break this efficiency ceiling, researchers move beyond token-by-token drafting toward block diffusion, a paradigm shift that enables generating an entire block of candidate tokens in a O(1) single forward pass.
We are proud to support external researchers pushing the boundaries of AI hardware. Today, we are thrilled to highlight a major open-source milestone from researchers at UCSD led by Hao Zhang, the co-inventor of paged attention and prefill/decode disaggregated serving. They successfully implemented block-diffusion speculative decoding (i.e., DFlash, a superior diffusion-style speculative decoding developed by Zhijian Liu, Jian Chen et al in Z Lab at UCSD) on Google TPUs.
By integrating this novel architecture directly into the open source vLLM TPU inference ecosystem, the UCSD team achieved an average 3.13x increase in tokens per second on TPU v5p, with peak speedups reaching nearly 6x for complex math tasks. In the head-to-head serving comparison between DFlash and EAGLE-3 on TPU v5p, DFlash achieved a 2.29x end-to-end serving speedup, nearly doubling the 1.30x performance gain of EAGLE-3.
Here is a technical deep dive from the UCSD researchers detailing how they built this, their performance benchmarks, and what it means for the future of the Google TPU ecosystem.
Standard LLM inference generates text autoregressively. This means the model requires a full forward pass for every single token generated, heavily underutilizing the massive parallel compute capabilities of AI accelerators like TPUs, especially at lower batch sizes.
Speculative decoding mitigates this by using a smaller, highly efficient "draft" model (or mechanism) to predict multiple future tokens simultaneously. The larger "target" model then verifies these draft tokens in a single parallel forward pass. If the draft tokens are accurate, the system accepts multiple tokens at the cost of a single step, drastically reducing latency.
However, the promise of speculative decoding is often hindered by the draft model itself. Most existing methods rely on autoregressive draft mechanisms that generate candidate tokens sequentially. This means that while the target model's verification is parallel, the drafting phase remains bottlenecked by O(K) serial steps. As a result, the time spent "guessing" tokens begins to eat into the time saved by verification, capping the practical speedup potential.
Diffusion LLMs (dLLMs) fundamentally change the game by replacing this sequential process with a block diffusion mechanism. Instead of guessing the next word, dLLM "paints" the entire block. A notable dLLM-based drafting method is DFlash. By leveraging the hidden features extracted from the target model, DFlash can generate an entire block of draft tokens in a single forward pass. This shift from O(K) to O(1) complexity reduces drafting latency to nearly negligible levels, making it the perfect architectural fit for the TPU's high-bandwidth Matrix Multiplication Units (MXUs).
The UCSD research team integrated DFlash into the vLLM TPU Inference framework. DFlash is a novel approach to speculative decoding that leverages block-diffusion mechanisms to propose draft tokens with exceptionally high acceptance lengths (T).
Implementing this on Google TPUs required deep optimization. With architectural guidance from Google Cloud engineers, the UCSD team minimized the overhead to ensure that the memory bandwidth and matrix multiplication units were fully saturated. By mapping the DFlash proposer and the verification pipeline efficiently to the TPU architecture, they minimized the overhead of the drafting phase while maximizing the parallel verification throughput of the target model.
Porting DFlash from its original GPU/PyTorch implementation to the Google TPU/JAX AI Stack ecosystem wasn't just a simple code translation; it required re-engineering the system to align with the unique architectural strengths of TPUs. Here is how the UCSD team tackled the three primary technical hurdles.
In the PyTorch world, DFlash relies on simple, dynamic KV management. However, high-performance TPU serving via tpu-inference uses paged attention with Pallas kernels—a system that breaks memory into fixed-size pages to maximize efficiency.
The catch? DFlash's non-causal block diffusion—the very thing that lets it "paint" a block of tokens—is fundamentally incompatible with standard paged attention. To solve this, the researchers designed a dual-cache architecture. The target model continues to use a paged KV cache, ensuring it benefits from the high-performance Pallas kernels required for large-scale serving. The draft model uses a specialized path with static on-device JAX arrays, successfully mirroring the original DFlash design while maintaining TPU-native performance.
DFlash is unique because the draft model is "target-conditioned"—it stays smart by watching the target model's intermediate reasoning steps. These "hidden states" are stored in a context buffer that grows over time.
To keep communication between the host CPU and the TPU accelerator as fast as possible, the team implemented a power-of-2 padding strategy. This ensures that as newly projected features are appended to the buffer, they are transferred in optimized chunks. By meticulously tracking exactly how much context the draft model has already "consumed," they prevent any duplicate processing or data loss, keeping the parallel drafting highly accurate.
Unlike standard drafting methods, DFlash is uniquely stateful, relying on persistent state across iterations (including context buffers, KV cache positions, and RoPE offsets) to maintain its parallel block predictions. In the TPU-optimized vLLM pipeline, the metadata forwarded to the proposer included the draft tokens currently under verification. While this is standard for most models, for a diffusion-based architecture, it resulted in "sequence length inflation"—a misalignment where the internal draft state drifted away from the target model's reality.
By re-engineering the proposer to synchronize strictly with the true accepted token count, the research team restored perfect alignment between the two models. This adjustment allowed the block diffusion logic to operate with full mathematical precision on TPU hardware, unlocking the dramatic speedups they see in the final results.
To ensure a rigorous and fair comparison, the UCSD researchers benchmarked DFlash against the current mainstream speculative decoding method on TPUs: EAGLE-3. In this comparative study, the researchers used the exact same hardware (TPU v5p) and the same target model (Llama-3.1-8B) for both.
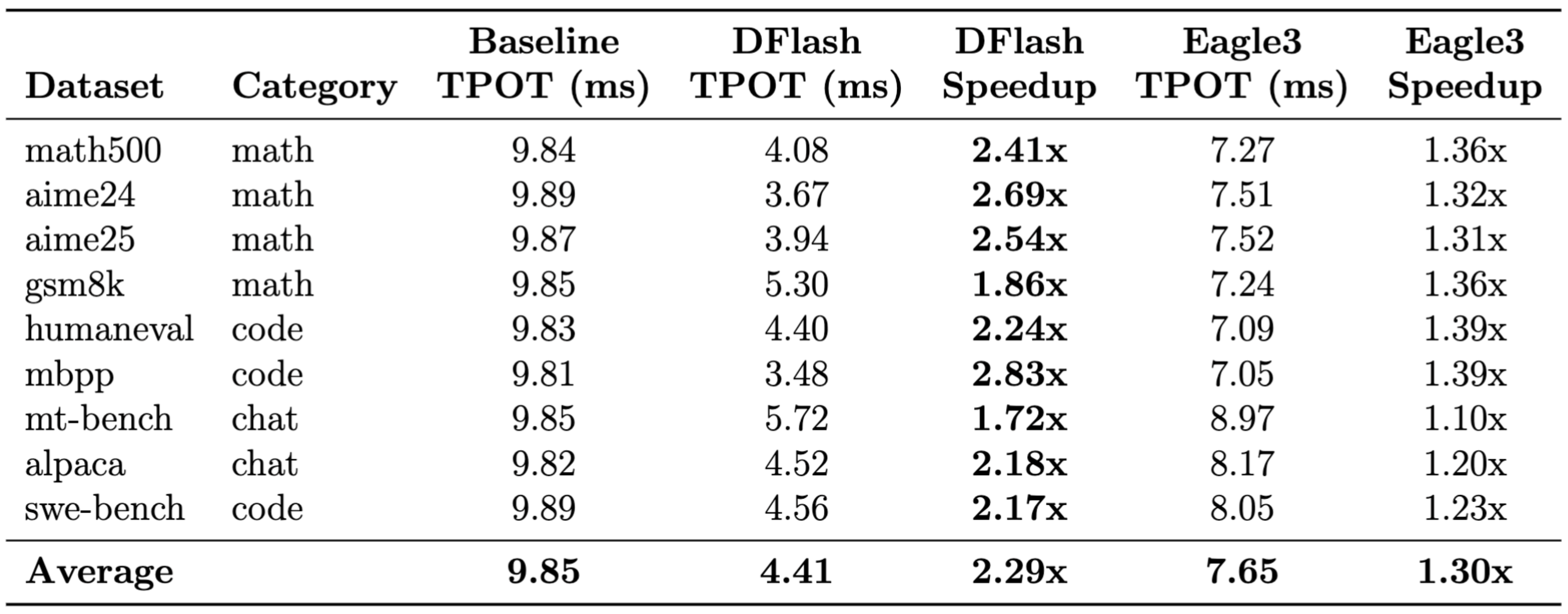
This setup represents the most practical deployment scenario for both methods, as the choice of K values is based on their respective official open-source checkpoints, used out-of-the-box without additional fine-tuning or re-configuration. Autoregressive drafters like EAGLE-3 incur a sequential latency penalty that grows linearly with K, which typically constrains them to smaller speculation budgets to maintain low per-token latency. In contrast, DFlash uses parallel block diffusion to predict all tokens in a single forward pass, making the drafting cost largely insensitive to K. The results were decisive: DFlash achieved a 2.29x speedup, while EAGLE-3 provided a 1.30x gain. On coding tasks like mbpp, DFlash compressed the generation time from 9.81ms per token down to 3.48ms, a 2.83x improvement.
Why is the gap so large? EAGLE-3 predicts 2 tokens per step autoregressively, requiring sequential forward passes with Python orchestration overhead between each. DFlash instead produces a block of 10 high-quality candidate tokens in a single forward pass, eliminating this serial bottleneck entirely. On TPUs, this "high-quality, high-quantity" draft output translates directly into a higher average acceptance length, turning the TPU's massive compute potential into real-world serving throughput.
To evaluate the impact of DFlash on Google TPUs, the UCSD team benchmarked their implementation across a variety of domains on TPU v5p, focusing heavily on complex reasoning, mathematics, and coding—areas where long-context generation typically suffers from high latency.
The UCSD team built a standalone JAX benchmark to evaluate DFlash results. By stripping away the serving layer overhead, they could isolate the raw power of the DFlash-on-TPU algorithm. They observed an average speedup of 3.13x across all datasets, with remarkable peaks in mathematical reasoning.
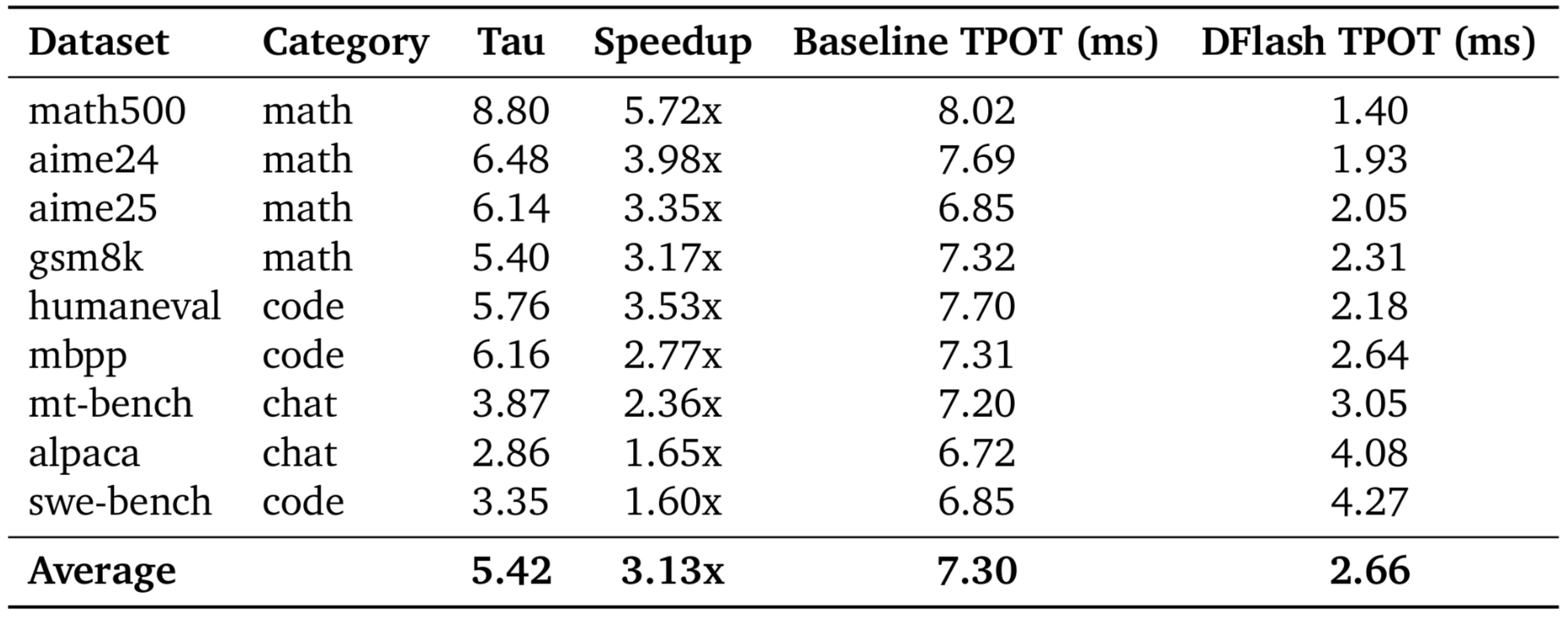
For rigorous math tasks like math500, DFlash pushed the generation time down from 8.02ms per token to 1.40ms per token. In coding evaluations like humaneval, generation speeds improved by over 3.5x.
During the optimization process, the research team uncovered a hardware characteristic that changes how engineers think about speculation limits: K-Flat verification.
On datacenter-grade accelerators like the TPU v5p, their systematic experiments revealed a surprising reality: the cost of verifying 1024 tokens is almost identical to the cost of verifying just 16 tokens. This phenomenon occurs because, on high-end hardware, the time spent is dominated by loading model weights rather than the raw math of the attention mechanism for these sequence lengths. In other words, the hardware's computational ceiling is so high that the extra work of checking a much longer "guess" is essentially free.
This discovery shifts the entire research frontier. It proves that the bottleneck for speculative decoding isn't "verification cost," but rather "draft quality." Knowing that wider blocks are computationally free allows developers to boldly scale draft block size, leveraging richer bidirectional context to improve accuracy without fear of slowing down the hardware.
While datacenter-grade AI accelerators make increasing the block size (K) virtually "free," their scaling theory reveals that simply adding more tokens yields diminishing returns. At their current operating points, a block size of K=16 already captures over 90% of the theoretical maximum speedup. In fact, scaling K from 16 all the way to 128 would likely net less than one additional accepted token per step.
The true lever for performance is quality over quantity. Their analysis shows that improving the per-position acceptance probability (a) is 2–3x more valuable than increasing the block size K. This shifts the research focus: in an environment where verification cost is constant, the primary bottleneck is no longer how many tokens systems can check, but how accurately they can predict them. The next frontier of LLM serving lies in smarter draft training, not just wider speculation windows.
Acceptance probability is deeply tied to the predictability of the task. The team observed a natural "positional decay" where tokens at the end of a block are harder to guess than those at the start. In logic-driven fields like math and coding, this decay is remarkably slow, maintaining high acceptance rates even deep into the block. Conversational chat, however, is more random, with accuracy dropping sharply after the first few tokens.
This predictability directly drives speedup. Because structured reasoning yields more predictable sequences, math and code tasks allow for much longer accepted blocks, more effectively saturating the TPU's parallel verification power. Consequently, DFlash achieves its highest gains in mathematical reasoning, followed by coding, while conversational tasks see a more moderate improvement.
A core tenet of this partnership is enriching the open-source ecosystem. Rather than keeping this as an internal research prototype, the complete implementation has been submitted to the vLLM tpu-inference repo, encompassing:
The UCSD team is actively working on adding a torchax proposer so that DFlash works on the PyTorch serving path as well.
This milestone sets the stage for the next wave of Google TPU innovation. By leveraging DFlash's unique parallel sampling, they are paving the way for Speculative Speculative Decoding (SSD), using speculation caches to drastically reduce latency in high-throughput environments. To capture richer context and boost acceptance rates for complex reasoning, they plan to scale to wider draft blocks using the TPU RL Stack Tunix and MaxText. Furthermore, the newly developed, high-performance JAX kernels provide the bedrock for supporting diffusion-based target models, keeping the vLLM-TPU ecosystem at the absolute cutting edge of efficient, non-autoregressive generation.
You can review the underlying technical report and implementation details via the Colab Notebook, or dive directly into the code on the vLLM GitHub repository.
This work was made possible by the TPU Builder program, reflecting our mission to empower the academic and open-source community with access to high-performance hardware and Google Cloud credits. If you are interested in using TPUs for research, teaching, or open-source development, we want to hear from you! Email us tpu-builders-support@google.com to get in touch.
Acknowledgements: A huge thank you to the research team at UCSD, including Zhongyan Luo, Son Nguyen, Andy Huang. Special thanks to Kyuyeun Kim, Brittany Rockwell, Chris Chan, Mitali Singh, Yixin Shi and Gang Ji’s team for working with research team to land the PR, and Josh Gordon, Edgar Chen, Aditi Joshi, Shubha Rao, Mani Varadarajan, Joe Pamer, Fenghui Zhang, Hassan Sipra, and Bill Jia for their unwavering support and investment in TPU Builder Program’s research partnerships.

ML Development in VS Code with Google Cloud Power: Workbench Extension Now Available

Run Ray on TPU, Part 2: Ray AI libraries
Run Ray on TPU, Part 1: The foundations

We terminated a TPU mid-training and it recovered in seconds: Introduction to elastic training with MaxText