

¿Alguna vez deseaste poder ver por qué el modelo Gemini eligió una palabra sobre otra? Para los desarrolladores que crean aplicaciones sofisticadas, comprender el proceso de toma de decisiones de un modelo es crucial. Ahora puedes hacerlo. El razonamiento del modelo ya no es una caja negra. La función logprobs se introdujo oficialmente en la API de Gemini en Vertex AI, lo que permite obtener una visión más profunda de las opciones del modelo.
Esta función te permite ver las puntuaciones de probabilidad para el token elegido y sus principales alternativas, lo que te brinda una visión sin precedentes del razonamiento del modelo. Esto es más que una herramienta de depuración; es una forma de compilar aplicaciones más inteligentes, confiables y conscientes del contexto.
Esta publicación de blog te guiará paso a paso a través del notebook "Introducción a logprobs": te mostrará cómo habilitar esta función y aplicarla a casos de uso potentes, como la clasificación segura, el autocompletado dinámico y la evaluación cuantitativa de RAG.
Primero, preparemos tu entorno para poder continuar.
%pip install -U -q google-genai2. Configura tu proyecto: configura tu ID y ubicación de Google Cloud Project. Este tutorial utiliza estas credenciales para autenticar tu entorno.
PROJECT_ID = "[your-project-id]"3. Inicializa el cliente y el modelo: crea un cliente para interactuar con la API de Vertex AI y especifica el modelo de Gemini que deseas usar.
desde google importa genai
client = genai.Client(vertexai=True, project=PROJECT_ID, location="global")
MODEL_ID = "gemini-2.5-flash"Antes de habilitar la función, aclaremos qué es una probabilidad logarítmica. Un logprob es el logaritmo natural de la puntuación de probabilidad del modelo asignado a un token.
Estos son los conceptos clave:
Por lo tanto, una puntuación de logprob más cercana a 0 indica una mayor confianza del modelo en su elección.
Puedes habilitar las probabilidades logarítmicas estableciendo dos parámetros en generation_config de tu solicitud.
response_logprobs=True: esto le indica al modelo que muestre las probabilidades logarítmicas de los tokens que eligió para su resultado. Su valor predeterminado es Falso.logprobs=[integer]: esto le pide al modelo que también muestre las probabilidades logarítmicas para un número específico de los tokens alternativos principales en cada paso. El valor aceptado está entre 1 y 20.
Veámoslo en acción con una simple indicación de clasificación. Le pediremos al modelo que clasifique una oración como "Positiva", "Negativa" o "Neutral".
from google.genai.types import GenerateContentConfig
prompt = "I am not sure if I really like this restaurant a lot."
response_schema = {"type": "STRING", "enum": ["Positive", "Negative", "Neutral"]}
response = client.models.generate_content(
model=MODEL_ID,
contents=prompt,
generation_config=GenerateContentConfig(
response_mime_type="application/json",
response_schema=response_schema,
response_logprobs=True,
logprobs=3,
),
)Los datos de logprobs se muestran dentro del objeto de respuesta. Puedes usar una función auxiliar para imprimir las probabilidades logarítmicas en un formato legible. La siguiente función proporciona una visión detallada de las predicciones del modelo para cada token en la respuesta generada.
def print_logprobs(response):
"""
Print log probabilities for each token in the response
"""
if response.candidates and response.candidates[0].logprobs_result:
logprobs_result = response.candidates[0].logprobs_result
for i, chosen_candidate in enumerate(logprobs_result.chosen_candidates):
print(
f"Token: '{chosen_candidate.token}' ({chosen_candidate.log_probability:.4f})"
)
if i < len(logprobs_result.top_candidates):
top_alternatives = logprobs_result.top_candidates[i].candidates
alternatives = [
alt
for alt in top_alternatives
if alt.token != chosen_candidate.token
]
if alternatives:
print("Alternative Tokens:")
for alt_token_info in alternatives:
print(
f" - '{alt_token_info.token}': ({alt_token_info.log_probability:.4f})"
)
print("-" * 20)Digamos que el modelo mostró lo siguiente:
2. Tokens alternativos:
Este resultado muestra que el modelo confía mucho en su elección de "Neutral", ya que su probabilidad logarítmica (-0,0214) es muy cercana a 0. Las alternativas, "Positiva" y "Negativa", tienen probabilidades logarítmicas significativamente más bajas (más negativas), lo que indica que el modelo las consideró mucho menos probables.
Logprobs transforma la clasificación de una respuesta simple en una decisión transparente, lo que te permite crear sistemas más sólidos.
Escenario: deseas automatizar una tarea de clasificación, pero debes marcar los casos ambiguos en los que el modelo no es seguro.
¿Por qué logprobs?: una pequeña diferencia entre las dos principales probabilidades logarítmicas es una señal de ambigüedad. Puedes verificar esta diferencia con un margen para decidir si se necesita una revisión humana.
La función check_for_ambiguity del notebook calcula la diferencia absoluta entre los logprobs de la primera y la segunda opción. Si esta diferencia es menor que un ambiguity_margin predefinido, marca el resultado como ambiguo.
Escenario: para aplicaciones críticas, solo deseas aceptar una clasificación si la confianza del modelo excede un cierto nivel, como el 90%.
¿Por qué logprobs?: logprobs te da una medida directa de la confianza del modelo. Puedes volver a convertir la probabilidad logarítmica del token elegido en una puntuación de probabilidad bruta para aplicar un umbral.
La función accept_if_confident lo demuestra utilizando math.exp() para convertir el logprob en un porcentaje de probabilidad y luego comprueba si está por encima de un umbral.
Escenario: deseas crear una función de autocompletado que sugiera las siguientes palabras más probables a medida que el usuario escribe.
¿Por qué logprobs?: al consultar repetidamente el modelo con el texto en crecimiento y examinar las logprobs de los mejores candidatos, puedes observar las predicciones cambiantes del modelo y ofrecer sugerencias relevantes en tiempo real.
El notebook simula a un usuario escribiendo "Lo mejor de vivir en Toronto es" palabra por palabra. A medida que el contexto crece, las sugerencias para la siguiente palabra se vuelven más específicas y precisas:

Análisis:
Esto muestra cómo las logprobs te brindan una ventana a la comprensión contextual del modelo, lo que te permite crear funciones más adaptativas y conscientes del contexto.
Escenario: tienes un sistema RAG y necesitas evaluar qué tan bien respaldadas están sus respuestas por el contexto obtenido.
¿Por qué logprobs?: cuando un LLM tiene un contexto relevante, aumenta su confianza en la generación de una respuesta objetivamente coherente, lo que se refleja en mayores probabilidades logarítmicas. Puedes calcular una probabilidad logarítmica promedio para que la respuesta generada obtenga una puntuación de "conexión a tierra" o "confianza".
El notebook establece una base de conocimientos ficticia y prueba tres escenarios: buena obtención, obtención deficiente y no obtención.
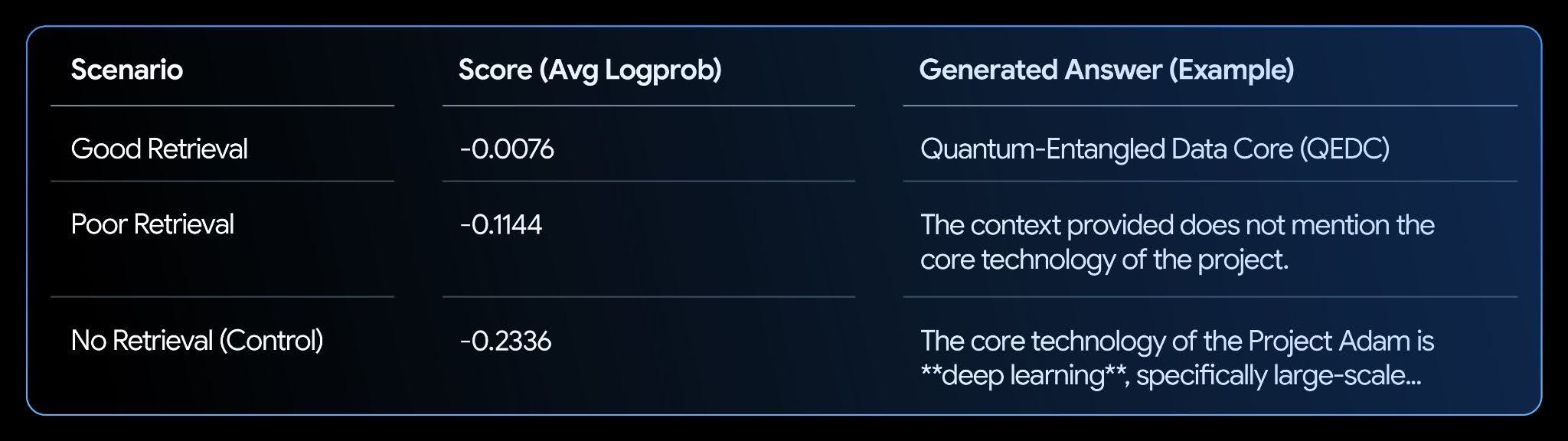
Análisis:
Los resultados muestran una clara correlación. El escenario "Buena obtención" tiene la puntuación más alta (más cercana a cero), ya que el modelo tiene mucha confianza en que su respuesta está respaldada por el texto. Esto hace que logprobs sea una métrica poderosa para automatizar la evaluación y mejora de tus sistemas RAG.
Ya aprendiste a usar la función logprobs para obtener una visión más profunda del proceso de toma de decisiones del modelo. Analizamos cómo aplicar estos conocimientos para analizar los resultados de la clasificación, crear funciones dinámicas de autocompletado y evaluar los sistemas RAG.
Estas son solo algunas de las aplicaciones de ejemplo, y con esta función, hay muchos más casos de uso para que los desarrolladores exploren.
Para profundizar, explora el notebook completo y consulta la documentación oficial:

Introducing Metrax: performant, efficient, and robust model evaluation metrics in JAX

Creación de canalizaciones de datos de alto rendimiento con Grain y ArrayRecord

El ADK para Java ahora está disponible para modelos de lenguaje de terceros a través de la integración con LangChain4j

Google Colab is Coming to VS Code