

Gemini モデルがある単語よりも別の単語を選ぶ理由を理解したいと思ったことはありませんか?高度なアプリケーションを構築するデベロッパーにとって、モデルの意思決定プロセスを理解することは重要ですが、このたび、それが可能になりました。モデルの推論はもはやブラック ボックスではありません。Vertex AI の Gemini API に logprobs 機能が正式に導入され、モデルの選択をより詳細に把握できるようになりました。
この機能により、選択したトークンとその上位の代替オプションの確率スコアを確認でき、モデルの推論について類を見ないほどの分析情報を得られます。これは単なるデバッグツールではありません。よりスマートで信頼性が高い、コンテキストに応じたアプリケーションの構築を可能にします。
このブログ投稿では、「Logprobs の概要」ノートブックをステップごとに説明し、この機能を有効にして、信頼性の高い分類、動的予測入力、定量的な RAG 評価などの優れたユースケースに適用する方法を紹介します。
まず、お使いの環境で使用できるように準備しましょう。
%pip install -U -q google-genai2. プロジェクトを構成する: Google Cloud のプロジェクト ID と場所を設定します。このチュートリアルでは、これらの認証情報を使用して環境を認証します。
PROJECT_ID = "[your-project-id]"3. クライアントとモデルを初期化する: Vertex AI API を操作するクライアントを作成し、使用する Gemini モデルを指定します。
from google import genai
client = genai.Client(vertexai=True, project=PROJECT_ID, location="global")
MODEL_ID = "gemini-2.5-flash"この機能を有効にする前に、ログ確率とは何かを確認しましょう。logprob は、トークンに割り当てられたモデルの確率スコアの自然対数です。
主なコンセプトは次のとおりです。
したがって、logprob スコアが 0 に近いほど、その選択に対するモデルの信頼度が高いことを示します。
ログ確率を有効にするには、リクエストの generation_config で 2 つのパラメータを設定します。
response_logprobs=True: 出力に選択したトークンのログ確率を返すようにモデルに指示します。デフォルトは False です。logprobs=[integer]: 各ステップで指定された数の上位の代替トークンのログ確率も返すようにモデルに要求します。許容される値は 1 から 20 の間です。
簡単な分類プロンプトで実際に見てみましょう。モデルに、文章を「Positive」、「Negative」、または「Neutral」に分類するよう指示します。
from google.genai.types import GenerateContentConfig
prompt = "I am not sure if I really like this restaurant a lot."
response_schema = {"type": "STRING", "enum": ["Positive", "Negative", "Neutral"]}
response = client.models.generate_content(
model=MODEL_ID,
contents=prompt,
generation_config=GenerateContentConfig(
response_mime_type="application/json",
response_schema=response_schema,
response_logprobs=True,
logprobs=3,
),
)logprobs データはレスポンス オブジェクト内で返されます。ヘルパー関数を使用して、ログ確率を読み取り可能な形式で出力できます。次の関数は、生成されたレスポンス内の各トークンに対するモデルの予測の詳細を示します。
def print_logprobs(response):
"""
Print log probabilities for each token in the response
"""
if response.candidates and response.candidates[0].logprobs_result:
logprobs_result = response.candidates[0].logprobs_result
for i, chosen_candidate in enumerate(logprobs_result.chosen_candidates):
print(
f"Token: '{chosen_candidate.token}' ({chosen_candidate.log_probability:.4f})"
)
if i < len(logprobs_result.top_candidates):
top_alternatives = logprobs_result.top_candidates[i].candidates
alternatives = [
alt
for alt in top_alternatives
if alt.token != chosen_candidate.token
]
if alternatives:
print("Alternative Tokens:")
for alt_token_info in alternatives:
print(
f" - '{alt_token_info.token}': ({alt_token_info.log_probability:.4f})"
)
print("-" * 20)たとえば、モデルが次のように返したとします。
2. Alternative Tokens:
この出力は、ログ確率(-0.0214)が 0 に非常に近いため、「Neutral」の選択に対するモデルの信頼度が非常に高いことを示しています。他のトークンの「Positive」と「Negative」は、ログ確率が大幅に低く(より負に寄っている)、モデルがそれらを考慮する可能性がはるかに低いことを示しています。
logprobs は、分類を単純な回答から透明性のある意思決定に変換し、より堅牢なシステムを構築できるようにします。
シナリオ: 分類タスクを自動化したいものの、モデルの信頼性が欠如している曖昧なケースにフラグを立てる必要があります。
logprobs を使用する理由: 上位 2 つのログ確率のわずかな違いは、曖昧さの兆候です。この差をマージンと照らし合わせて確認し、人間によるレビューが必要かどうかを判断できます。
ノートブックの check_for_ambiguity 関数は、上位 2 つの選択の logprob の絶対差を計算します。この差が事前定義された ambiguity_margin よりも小さい場合、結果に曖昧のフラグが立てられます。
シナリオ: 重要なアプリケーションの場合、モデルの信頼度が特定のレベル(90% など)を超えた場合にのみ、分類を受け入れます。
logprobs を使用する理由: logprobs は、モデルの信頼度を直接測定します。選択したトークンのログ確率を未加工の確率スコアに再び変換して、しきい値を適用できます。
accept_if_confident 関数は、math.exp() を使用して logprob を確率パーセンテージに変換し、しきい値を超えているかどうかを確認することで、これを実証します。
シナリオ: ユーザーが次に入力する可能性の高い単語を提案する予測入力機能を構築します。
logprobs を使用する理由: テキストを増やしながらモデルに対してクエリを繰り返し実行し、上位の候補の logprob を調べることで、モデルの変化する予測を観察し、関連性のあるリアルタイムの提案を提供できます。
このノートブックでは、ユーザーが「The best thing about living in Toronto is the」と 1 単語ずつ入力するのをシミュレートします。コンテキストが拡大するにつれて、次の単語の提案はより具体的で正確になります。

分析:
これは、logprobs がモデルのコンテキストをどの程度理解しているかを示しており、より適応性があり、コンテキストに応じた機能の構築を可能にします。
シナリオ: RAG システムがあり、その回答が取得されたコンテキストによってどの程度サポートされているかを評価する必要があります。
logprobs を使用する理由: LLM に関連するコンテキストがある場合、事実上一貫した回答を生成する信頼度が高まり、ログ確率が高くなります。生成された回答の平均ログ確率を計算して、「グラウンディング」スコアまたは「信頼」スコアを取得できます。
このノートブックでは、架空のナレッジベースを設定し、良好な検索、不十分な検索、検索なしの 3 つのシナリオをテストします。
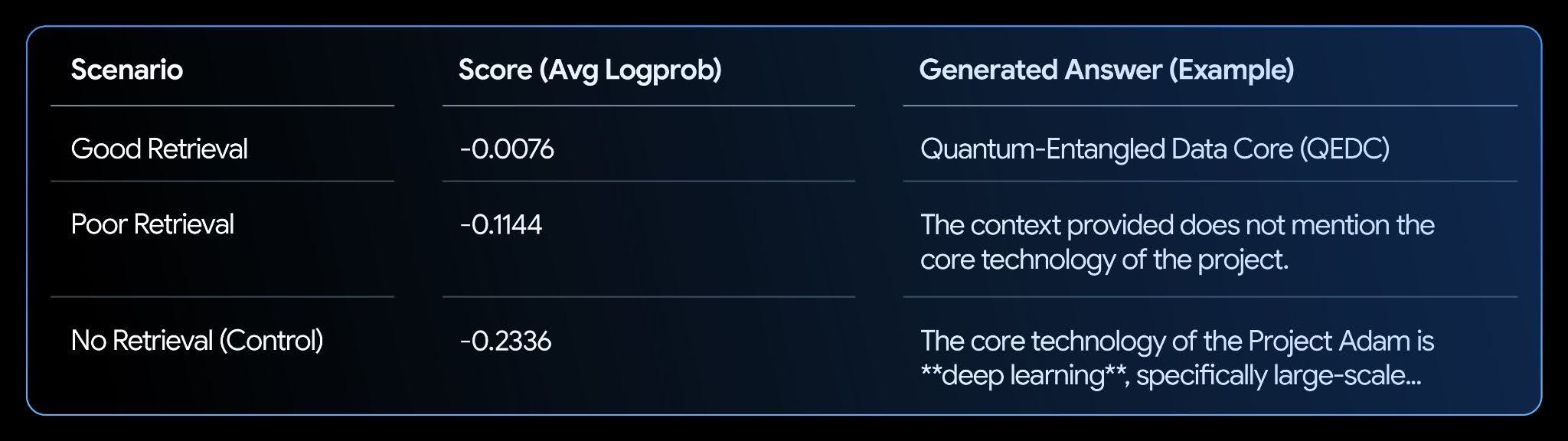
分析:
結果は明確な相関を示しています。最もスコアが高い(ゼロに近い)のは「良好な検索」シナリオで、その回答がテキストによってサポートされていることに対するモデルの信頼度が非常に高くなっています。これにより、logprobs は RAG システムの評価と改善を自動化するための優れた指標になります。
logprobs 機能を使用して、モデルの意思決定プロセスについてより深いインサイトを得る方法の説明は以上です。ここまで、これらのインサイトを適用して分類結果を分析し、動的予測入力機能を構築し、RAG システムを評価する方法について見てきました。
これらは応用例のほんの一部にすぎません。この機能により、デベロッパーが模索するユースケースがさらに多くなります。
詳細については、ノートブックの概要全体と公式ドキュメントを参照してください。



