

Pernahkah Anda ingin tahu mengapa model Gemini memilih satu kata daripada kata lainnya? Bagi developer yang membuat aplikasi mutakhir, memahami proses pengambilan keputusan sebuah model sangatlah penting. Sekarang Anda bisa melakukannya. Penalaran model bukan lagi sebuah kotak hitam. Fitur logprobs telah secara resmi diperkenalkan di Gemini API dalam Vertex AI, membuka pandangan yang lebih dalam mengenai pilihan model.
Fitur ini memungkinkan Anda melihat nilai probabilitas untuk token terpilih dan alternatif terbaiknya, memberikan Anda insight yang luar biasa tentang penalaran model. Ini lebih dari sekadar alat proses debug; ini adalah cara untuk membangun aplikasi yang lebih cerdas, andal, dan sadar konteks.
Postingan blog ini akan memandu Anda langkah demi langkah melalui notebook “Pengantar Logprobs”, menunjukkan kepada Anda cara mengaktifkan fitur ini dan menerapkannya pada kasus penggunaan yang kuat, seperti klasifikasi keyakinan, pelengkapan otomatis dinamis, dan evaluasi RAG kuantitatif.
Pertama, siapkan lingkungan Anda dan ikuti langkah berikut.
%pip install -U -q google-genai2. Konfigurasikan project Anda: Siapkan lokasi dan Project ID Google Cloud Anda. Tutorial ini menggunakan kredensial ini untuk mengautentikasi lingkungan Anda.
PROJECT_ID = "[your-project-id]"3. Lakukan inisialisasi klien dan model: Buat klien untuk berinteraksi dengan Vertex AI API dan tentukan model Gemini yang ingin Anda gunakan.
from google import genai
client = genai.Client(vertexai=True, project=PROJECT_ID, location="global")
MODEL_ID = "gemini-2.5-flash"Sebelum mengaktifkan fitur ini, mari kita perjelas apa yang dimaksud dengan probabilitas log. Logprob adalah logaritma natural dari nilai probabilitas yang ditetapkan model untuk sebuah token.
Inilah konsep utamanya:
Oleh karena itu, nilai logprob yang mendekati 0 mengindikasikan kepercayaan model yang lebih tinggi pada pilihannya.
Anda bisa mengaktifkan probabilitas log dengan mengatur dua parameter dalam generation_config permintaan Anda.
response_logprobs=True: Ini memberi tahu model untuk menampilkan probabilitas log dari token yang dipilihnya sebagai output. Nilai default-nya adalah False.logprobs=[integer]: Ini meminta model agar menampilkan juga probabilitas log untuk sejumlah token alternatif terbaik pada setiap langkah. Nilai yang diterima antara 1 dan 20.
Mari kita lihat aksinya dengan prompt klasifikasi sederhana. Kami akan meminta model untuk mengklasifikasikan kalimat sebagai "Positif", "Negatif", atau "Netral".
from google.genai.types import GenerateContentConfig
prompt = "I am not sure if I really like this restaurant a lot."
response_schema = {"type": "STRING", "enum": ["Positive", "Negative", "Neutral"]}
response = client.models.generate_content(
model=MODEL_ID,
contents=prompt,
generation_config=GenerateContentConfig(
response_mime_type="application/json",
response_schema=response_schema,
response_logprobs=True,
logprobs=3,
),
)Data logprobs ditampilkan dalam objek respons. Anda bisa menggunakan fungsi bantuan untuk mencetak probabilitas log dalam format yang dapat dibaca. Fungsi berikut memberikan tampilan prediksi model terperinci untuk setiap token dalam respons yang dihasilkan.
def print_logprobs(response):
"""
Print log probabilities for each token in the response
"""
if response.candidates and response.candidates[0].logprobs_result:
logprobs_result = response.candidates[0].logprobs_result
for i, chosen_candidate in enumerate(logprobs_result.chosen_candidates):
print(
f"Token: '{chosen_candidate.token}' ({chosen_candidate.log_probability:.4f})"
)
if i < len(logprobs_result.top_candidates):
top_alternatives = logprobs_result.top_candidates[i].candidates
alternatives = [
alt
for alt in top_alternatives
if alt.token != chosen_candidate.token
]
if alternatives:
print("Alternative Tokens:")
for alt_token_info in alternatives:
print(
f" - '{alt_token_info.token}': ({alt_token_info.log_probability:.4f})"
)
print("-" * 20)Katakanlah model menunjukkan hasil seperti berikut:
2. Token Alternatif:
Output ini menunjukkan bahwa model sangat yakin dengan pilihan "Netral," karena probabilitas lognya (-0,0214) sangat dekat dengan 0. Alternatif lainnya, "Positif" dan "Negatif," memiliki probabilitas log yang jauh lebih rendah (lebih negatif), mengindikasikan bahwa model menganggapnya memiliki kemungkinan yang jauh lebih kecil.
Logprobs mentransformasi klasifikasi dari jawaban sederhana menjadi keputusan yang transparan, sehingga Anda dapat membangun sistem yang lebih kuat.
Skenario: Anda ingin mengotomatiskan tugas klasifikasi tetapi perlu menandai kasus-kasus ambigu ketika model tidak yakin.
Mengapa Logprobs?: Perbedaan kecil antara dua probabilitas log teratas adalah sinyal ambiguitas. Anda bisa memeriksa perbedaan ini terhadap margin untuk memutuskan apakah perlu dilakukan peninjauan manusia.
Fungsi check_for_ambiguity di notebook menghitung perbedaan absolut antara logprobs pilihan teratas dan kedua. Jika perbedaan ini kurang dari ambiguity_margin yang telah ditentukan, ia akan menandai hasilnya sebagai ambigu.
Skenario: Untuk aplikasi penting, Anda sebaiknya hanya menerima klasifikasi jika keyakinan model melebihi level tertentu, seperti 90%.
Mengapa Logprobs?: Logprobs memberikan Anda ukuran keyakinan model secara langsung. Anda bisa mengonversi probabilitas log token terpilih kembali menjadi skor probabilitas mentah untuk menerapkan ambang batas.
Fungsi accept_if_confident menunjukkan hal ini dengan menggunakan math.exp() untuk mengonversi logprob menjadi persentase probabilitas dan kemudian memeriksanya jika itu di atas threshold.
Skenario: Anda ingin membangun fitur pelengkapan otomatis yang menyarankan kata berikutnya yang paling sesuai saat pengguna mengetik.
Mengapa Logprobs?: Dengan berulang kali melakukan kueri model dengan teks yang terus bertambah dan memeriksa logprobs kandidat teratas, Anda bisa mengamati pergeseran prediksi model dan menawarkan saran real-time yang relevan.
Notebook ini menyimulasikan pengguna yang mengetik “The best thing about living in Toronto is the” kata demi kata. Seiring dengan bertambahnya konteks, saran untuk kata berikutnya semakin spesifik dan akurat:

Analisis:
Hal ini menunjukkan bagaimana logprobs memberi Anda jendela ke dalam pemahaman kontekstual model, memungkinkan Anda membangun fitur yang lebih adaptif dan sadar konteks.
Skenario: Anda memiliki sistem RAG dan perlu mengevaluasi seberapa baik jawabannya didukung oleh konteks yang diambil.
Mengapa Logprobs?: Ketika LLM memiliki konteks yang relevan, keyakinannya dalam menghasilkan jawaban yang konsisten secara faktual akan meningkat, yang tercermin dalam probabilitas log yang lebih tinggi. Anda bisa menghitung probabilitas log rata-rata jawaban yang dihasilkan untuk mendapatkan nilai “dasar” atau “keyakinan”.
Notebook ini menyiapkan pusat informasi fiksi dan menguji tiga skenario: good retrieval (pengambilan yang baik), poor retrieval (pengambilan yang buruk), dan no retrieval (tidak ada pengambilan).
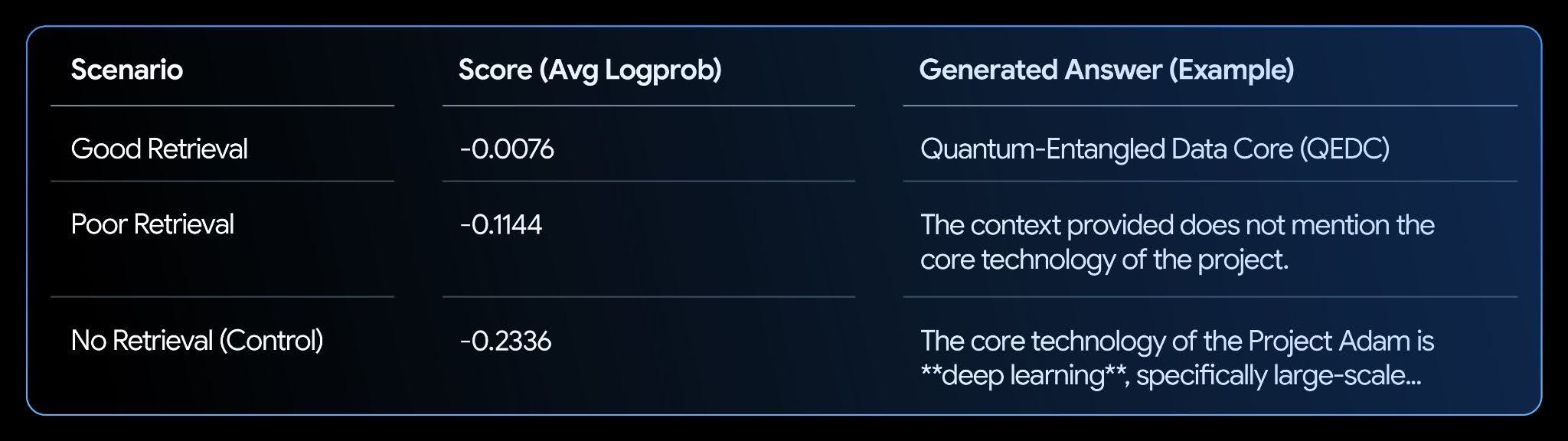
Analisis:
Hasilnya menunjukkan korelasi yang jelas. Skenario “Good Retrieval” memiliki nilai tertinggi (mendekati nol), karena model sangat yakin bahwa jawabannya didukung oleh teks. Hal ini menjadikan logprobs sebagai metrik yang kuat untuk mengotomatiskan evaluasi dan peningkatan sistem RAG Anda.
Anda sekarang telah mempelajari cara menggunakan fitur logprobs untuk mendapatkan insight yang lebih mendalam tentang proses pengambilan keputusan model. Kami telah membahas cara menerapkan insight ini untuk menganalisis hasil klasifikasi, membangun fitur pelengkapan otomatis dinamis, dan mengevaluasi sistem RAG.
Ini hanyalah sebagian kecil dari contoh aplikasi, dan dengan fitur ini, masih banyak lagi kasus penggunaan yang dapat dijelajahi oleh developer.
Untuk mempelajari lebih dalam, jelajahi notebook lengkap dan baca dokumentasi resminya:

Membangun Data Pipelines Berkinerja Tinggi dengan Grain dan ArrayRecord

Introducing Metrax: performant, efficient, and robust model evaluation metrics in JAX

Google Colab is Coming to VS Code

ADK untuk Java membuka model bahasa pihak ketiga melalui integrasi LangChain4j