

Ever wished you could see why the Gemini model chose one word over another? For developers building sophisticated applications, understanding a model's decision-making process is crucial. Now you can. The model's reasoning is no longer a black box. The logprobs feature has been officially introduced in the Gemini API on Vertex AI, unlocking a deeper view into the model's choices.
This feature allows you to see the probability scores for the chosen token and its top alternatives, giving you unprecedented insight into the model's reasoning. This is more than just a debugging tool; it's a way to build smarter, more reliable, and context-aware applications.
This blog post will walk you step-by-step through the "Intro to Logprobs" notebook, showing you how to enable this feature and apply it to powerful use cases like confident classification, dynamic autocomplete, and quantitative RAG evaluation.
First, let's get your environment ready to follow along.
%pip install -U -q google-genai2. Configure your project: Set up your Google Cloud Project ID and location. This tutorial uses these credentials to authenticate your environment.
PROJECT_ID = "[your-project-id]"3. Initialize the client and model: Create a client to interact with the Vertex AI API and specify the Gemini model you want to use.
from google import genai
client = genai.Client(vertexai=True, project=PROJECT_ID, location="global")
MODEL_ID = "gemini-2.5-flash"Before enabling the feature, let's clarify what a log probability is. A logprob is the natural logarithm of the probability score the model assigned to a token.
Here are the key concepts:
Therefore, a logprob score closer to 0 indicates higher model confidence in its choice.
You can enable log probabilities by setting two parameters in your request's generation_config.
response_logprobs=True: This tells the model to return the log probabilities of the tokens it chose for its output. Its default is False.logprobs=[integer]: This asks the model to also return the log probabilities for a specified number of the top alternative tokens at each step. The accepted value is between 1 and 20.
Let's see this in action with a simple classification prompt. We'll ask the model to classify a sentence as "Positive," "Negative," or "Neutral".
from google.genai.types import GenerateContentConfig
prompt = "I am not sure if I really like this restaurant a lot."
response_schema = {"type": "STRING", "enum": ["Positive", "Negative", "Neutral"]}
response = client.models.generate_content(
model=MODEL_ID,
contents=prompt,
generation_config=GenerateContentConfig(
response_mime_type="application/json",
response_schema=response_schema,
response_logprobs=True,
logprobs=3,
),
)The logprobs data is returned within the response object. You can use a helper function to print the log probabilities in a readable format. The following function provides a detailed look at the model's predictions for each token in the generated response.
def print_logprobs(response):
"""
Print log probabilities for each token in the response
"""
if response.candidates and response.candidates[0].logprobs_result:
logprobs_result = response.candidates[0].logprobs_result
for i, chosen_candidate in enumerate(logprobs_result.chosen_candidates):
print(
f"Token: '{chosen_candidate.token}' ({chosen_candidate.log_probability:.4f})"
)
if i < len(logprobs_result.top_candidates):
top_alternatives = logprobs_result.top_candidates[i].candidates
alternatives = [
alt
for alt in top_alternatives
if alt.token != chosen_candidate.token
]
if alternatives:
print("Alternative Tokens:")
for alt_token_info in alternatives:
print(
f" - '{alt_token_info.token}': ({alt_token_info.log_probability:.4f})"
)
print("-" * 20)Let's say the model returned the following:
2. Alternative Tokens:
This output shows the model is highly confident in its choice of "Neutral," as its log probability (-0.0214) is very close to 0. The alternatives, "Positive" and "Negative," have significantly lower (more negative) log probabilities, indicating the model considered them much less likely.
Logprobs transform classification from a simple answer into a transparent decision, allowing you to build more robust systems.
Scenario: You want to automate a classification task but need to flag ambiguous cases where the model isn't confident.
Why Logprobs?: A small difference between the top two log probabilities is a signal of ambiguity. You can check this difference against a margin to decide if human review is needed.
The check_for_ambiguity function in the notebook calculates the absolute difference between the top and second choice's logprobs. If this difference is less than a predefined ambiguity_margin, it flags the result as ambiguous.
Scenario: For critical applications, you only want to accept a classification if the model's confidence exceeds a certain level, like 90%.
Why Logprobs?: Logprobs give you a direct measure of the model's confidence. You can convert the log probability of the chosen token back into a raw probability score to apply a threshold.
The accept_if_confident function demonstrates this by using math.exp() to convert the logprob to a probability percentage and then checks if it's above a threshold.
Scenario: You want to build an auto-complete feature that suggests the most likely next words as a user types.
Why Logprobs?: By repeatedly querying the model with the growing text and examining the logprobs of the top candidates, you can observe the model's shifting predictions and offer relevant, real-time suggestions.
The notebook simulates a user typing "The best thing about living in Toronto is the" word by word . As the context grows, the suggestions for the next word become more specific and accurate:

Analysis:
This shows how logprobs give you a window into the model's contextual understanding, allowing you to build more adaptive and context-aware features.
Scenario: You have a RAG system and need to evaluate how well its answers are supported by the retrieved context.
Why Logprobs?: When an LLM has relevant context, its confidence in generating a factually consistent answer increases, which is reflected in higher log probabilities. You can calculate an average log probability for the generated answer to get a "grounding" or "confidence" score.
The notebook sets up a fictional knowledge base and tests three scenarios: good retrieval, poor retrieval, and no retrieval.
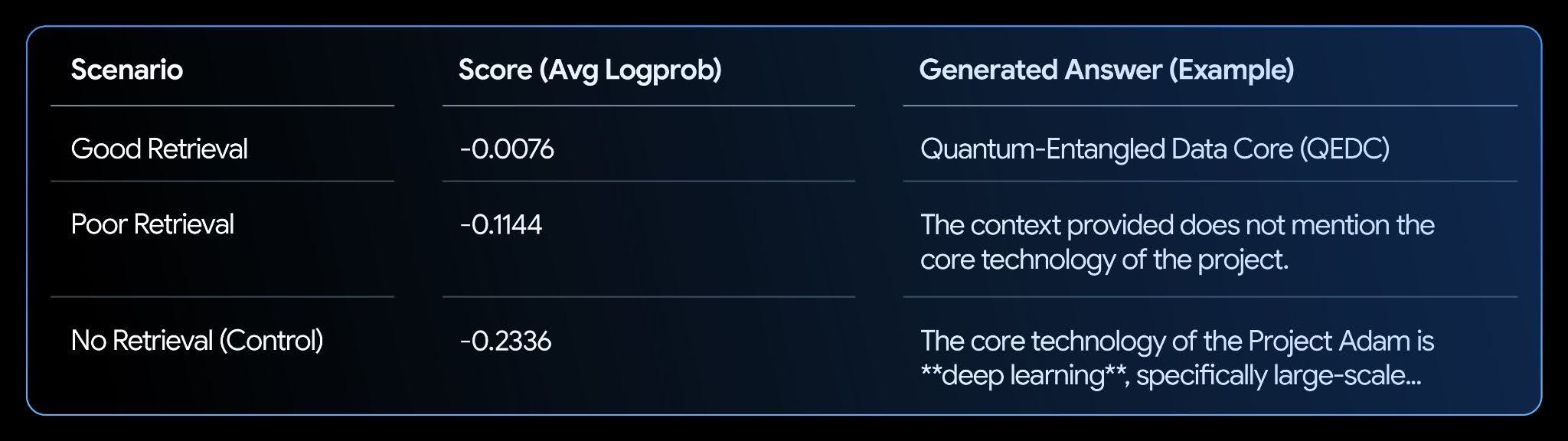
Analysis:
The results show a clear correlation. The "Good Retrieval" scenario has the highest score (closest to zero), as the model is very confident its answer is supported by the text. This makes logprobs a powerful metric for automating the evaluation and improvement of your RAG systems.
You've now learned how to use the logprobs feature to gain deeper insight into the model's decision-making process. We've walked through how to apply these insights to analyze classification results, build dynamic autocomplete features, and evaluate RAG systems.
These are just a few of the example applications, and with this feature, there are many more use cases for developers to explore.
To dive deeper, explore the full notebook and consult the official documentation:

ADK for Java opening up to third-party language models via LangChain4j integration

Building High-Performance Data Pipelines with Grain and ArrayRecord

Architecting efficient context-aware multi-agent framework for production

Announcing the Data Commons Gemini CLI extension