

Gemini 모델이 다른 단어 대신 특정 단어를 선택하는 이유를 알고 싶지 않으셨나요? 복잡한 애플리케이션을 구축하는 개발자에게 모델의 의사 결정 과정을 이해하는 것은 중요한 일이죠. 이제 그 이유를 알아볼 수 있습니다. 모델의 추론 과정은 이제 더 이상 블랙박스가 아닙니다. 로그 확률 기능이 Vertex AI의 Gemini API에 공식적으로 도입되어 모델의 선택에 대한 깊이 있는 시각을 제공합니다.
이 기능을 사용하면 선택한 토큰과 상위 대체 토큰에 대한 확률 점수를 볼 수 있어 모델의 추론 과정에 대한 전례 없는 인사이트를 얻을 수 있습니다. 이 기능은 단순한 디버깅 도구가 아닌 더 스마트하고, 안정적이며, 컨텍스트를 잘 인식하는 애플리케이션을 구축하는 수단입니다.
이 블로그 게시물에서는 '로그 확률 소개' 메모장을 통해 단계별로 이 기능을 활성화 및 해석하고 확실한 분류, 동적 자동 완성, 정량적 RAG 평가 등 다양한 사용 사례에 적용하는 방법을 소개합니다.
먼저 다음과 같이 환경을 준비합니다.
%pip install -U -q google-genai2. 프로젝트 구성하기: Google Cloud 프로젝트 ID와 위치를 설정합니다. 이 튜토리얼에서는 이 사용자 인증 정보를 사용하여 환경을 인증합니다.
PROJECT_ID = "[your-project-id]"3. 클라이언트와 모델 초기화하기: Vertex AI API와 설치된 앱과 상호작용할 클라이언트를 생성하고 사용하려는 Gemini 모델을 특정합니다.
from google import genai
client = genai.Client(vertexai=True, project=PROJECT_ID, location="global")
MODEL_ID = "gemini-2.5-flash"이 기능을 활성화하기 전에 로그 확률이 무엇인지 명확히 알아봅시다. 로그 확률은 모델이 토큰에 할당하는 확률 점수에 대한 자연 로그입니다.
다음은 로그 확률의 주요 개념입니다.
따라서 로그 확률 점수가 0에 가까울수록 모델이 자신의 선택을 더 확신한다는 뜻입니다.
요청의 generation_config의 두 매개변수를 설정하여 로그 확률을 활성화할 수 있습니다.
response_logprobs=True: 모델에 출력한 값에 대하여 선택한 토큰의 로그 확률을 반환하라고 하는 명령어입니다. 이 명령어의 기본값은 False입니다.logprobs=[integer]: 모델에 각 단계에서 상위 대체 토큰의 특정 수에 대한 로그 확률도 반환하라고 요청하는 명령어입니다. 허용되는 값은 1에서 20 사이입니다.
간단한 분류 프롬프트를 통해 실제로 작동하는 과정을 살펴봅시다. 모델에게 문장을 '긍정', '부정' 또는 '중립'으로 분류하라고 요청합니다.
from google.genai.types import GenerateContentConfig
prompt = "I am not sure if I really like this restaurant a lot."
response_schema = {"type": "STRING", "enum": ["Positive", "Negative", "Neutral"]}
response = client.models.generate_content(
model=MODEL_ID,
contents=prompt,
generation_config=GenerateContentConfig(
response_mime_type="application/json",
response_schema=response_schema,
response_logprobs=True,
logprobs=3,
),
)로그 확률 데이터는 응답 객체 내에서 반환됩니다. 도우미 함수를 사용하여 로그 확률을 읽을 수 있는 형식으로 출력할 수 있습니다. 다음 기능을 통해 생성된 응답의 각 토큰에 대한 모델의 예측을 자세히 살펴볼 수 있습니다.
def print_logprobs(response):
"""
Print log probabilities for each token in the response
"""
if response.candidates and response.candidates[0].logprobs_result:
logprobs_result = response.candidates[0].logprobs_result
for i, chosen_candidate in enumerate(logprobs_result.chosen_candidates):
print(
f"Token: '{chosen_candidate.token}' ({chosen_candidate.log_probability:.4f})"
)
if i < len(logprobs_result.top_candidates):
top_alternatives = logprobs_result.top_candidates[i].candidates
alternatives = [
alt
for alt in top_alternatives
if alt.token != chosen_candidate.token
]
if alternatives:
print("Alternative Tokens:")
for alt_token_info in alternatives:
print(
f" - '{alt_token_info.token}': ({alt_token_info.log_probability:.4f})"
)
print("-" * 20)모델이 다음과 같이 반환했다고 가정합시다.
2. 대체 토큰:
이 출력값은 로그 확률 (-0.0214)가 0에 아주 근접하므로 모델이 자신이 내린 '중립'이라는 선택을 무척 확신한다는 것을 보여줍니다. 대안인 '긍정'과 '부정'의 로그 확률은 훨씬 낮으므로(더 부정적이므로) 모델이 해당 응답의 가능성이 더 낮다고 생각한 것을 시사합니다.
분류를 간단한 답변에서 투명한 결정으로 변환하는 로그 확률 기능을 통해 더욱 탄탄한 시스템을 구축할 수 있습니다.
시나리오: 분류 작업을 자동화하고 싶지만 모델이 확신할 수 없는 모호한 케이스를 플래그해야 합니다.
로그 확률이 필요한 이유: 두 가지 상위 로그 확률 간 사소한 차이는 모호함을 유발합니다. 이러한 차이를 확인하고 인적 검토가 필요한지 결정할 수 있습니다.
메모장의 check_for_ambiguity 기능은 첫 번째 및 두 번째 선택의 로그 확률 간 절대차를 계산합니다. 만약 이 차이가 사전 정의된 ambiguity_margin보다 적을 경우 이 값을 '모호함'으로 플래그합니다.
시나리오: 중요한 애플리케이션의 경우 모델의 신뢰도가 특정 수준(예: 90%)을 초과하는 경우에만 분류를 수용하고 싶습니다.
로그 확률이 필요한 이유: 로그 확률은 모델의 신뢰도에 대한 직접 측정 방식을 제공합니다. 선택한 토큰의 로그 확률을 원 확률 점수로 다시 변환하여 기준점에 적용할 수 있습니다.
math.exp()을 사용하여 로그 확률을 확률 백분율로 전환한 후 해당 값이 기준점을 초과하는지 확인함으로써 accept_if_confident 기능으로 이 작업을 수행할 수 있습니다.
시나리오: 사용자가 다음에 입력할 가능성이 가장 높은 단어를 제안하는 자동 완성 기능을 구축하고 싶습니다.
로그 확률이 필요한 이유: 점점 더 많아지는 텍스트를 모델에 반복적으로 쿼리하고 상위 후보의 로그 확률을 검토하여 모델의 변화하는 예상 검색어를 관찰하고 관련성 있는 실시간 제안을 제공할 수 있습니다.
메모장은 '토론토에서 살면 가장 좋은 점은'을 한 단어씩 입력한 사용자를 시뮬레이션합니다. 컨텍스트가 늘어날수록 다음 단어를 위한 제안이 점차 구체적이고 정확해집니다.

분석:
이러한 과정은 로그 확률을 통해 모델의 맥락적 이해를 확인하여 더 뛰어난 적응형 컨텍스트 인식 기능을 구축할 수 있음을 보여줍니다.
시나리오: RAG 시스템이 있고 해당 시스템의 답변이 검색한 맥락에 의해 얼마나 뒷받침되는지 평가해야 합니다.
로그 확률이 필요한 이유: LLM에 관련성 있는 맥락이 있는 경우, 해당 LLM이 생성한 사실적으로 일관된 답변에 대한 신뢰도가 올라가며, 이는 더 높은 로그 확률로 이어집니다. 생성된 답변에 대한 평균 로그 확률을 계산하여 '일관적' 또는 '확실한' 점수를 얻을 수 있습니다.
메모장은 가상의 기술 자료를 설정하고 세 시나리오(좋은 검색 결과, 나쁜 검색 결과, 검색 결과 없음)를 테스트합니다.
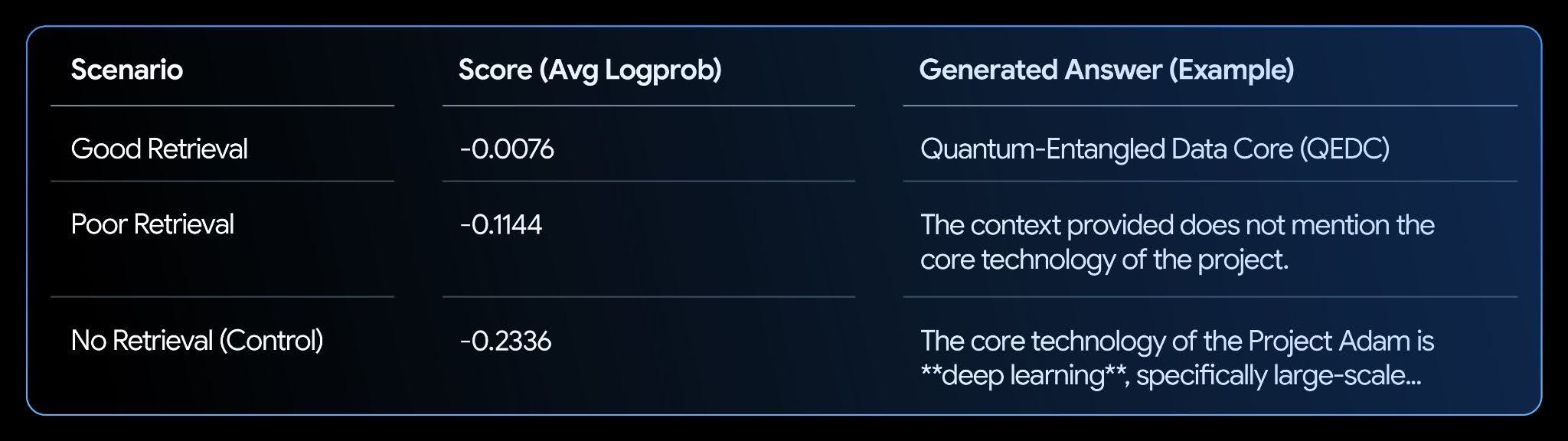
분석:
결과를 통해 명확한 상관관계를 알 수 있습니다. '좋은 검색 결과' 시나리오는 가장 높은 점수(0에 가까운 점수)를 받았습니다. 이는 모델이 텍스트가 답을 뒷받침한다고 매우 확신하기 때문입니다. 따라서 로그 확률은 RAG 시스템의 평가 및 개선을 자동화하는 강력한 지표가 됩니다.
로그 확률 기능을 사용하여 모델의 의사 결정 과정에 대한 깊이 있는 인사이트를 얻는 방법을 알아보았습니다. 이 글에서는 이러한 인사이트를 적용하여 분류 결과를 분석하고, 동적 자동 완성 기능을 구축하고, RAG 시스템을 평가하는 방법을 소개했습니다.
이러한 작업은 예시 애플리케이션의 일부분일 뿐입니다. 이 기능을 사용한 더 많은 개발자용 사용 사례를 살펴보세요.
더 자세히 알아보려면 다음 메모장 전문과 공식 문서를 살펴보세요.



