
Google Cloud Dataflow는 확장성이 뛰어난 방식으로 Google Cloud에서 Apache Beam 파이프라인을 실행하기 위한 완전 관리형 데이터 처리 시스템을 제공합니다. 완전 관리형 서비스이므로, Dataflow 사용자는 서비스 측 회귀 및 버전 관리에 대해 걱정할 필요가 없습니다. Google이 서비스 인프라를 관리하는 동안 파이프라인 로직에만 집중하면 된다는 점을 약속드립니다. 이는 분명한 사실이지만, Apache Beam 자체는 모든 기능을 완비한 SDK로서, 파이프라인에서 사용할 수 있는 간단한 것부터 매우 복잡한 것까지 다양한 수준의 변환을 제공합니다. 예를 들어, Apache Beam은 많은 I/O 커넥터를 제공합니다. 이러한 커넥터 중 다수는 수십에서 수백 단계로 구성된 Apache Beam 복합 변환입니다. 과거에는 이러한 것을 사용자가 작성하거나 유지 관리하지 않았음에도 서비스 관점에서 '사용자 코드'로 간주했습니다. 고객이 I/O 커넥터 같은 복잡한 Beam 변환에서 흔히 직면하는 몇 가지 복잡하고 까다로운 문제가 있습니다.
이러한 세 가지 문제를 모두 완화하기 위해, Dataflow는 최근 관리형 I/O라는 새로운 솔루션을 선보였습니다. 관리형 I/O를 사용하면 서비스 자체가 사용자를 대신해서 이러한 복잡한 부분을 관리할 수 있습니다. 따라서 사용자는 자신의 니즈에 맞는 특정 커넥터의 사용 및 구성과 관련된 세부 사항에 초점을 맞추는 대신 파이프라인 비즈니스 로직에 온전히 집중할 수 있습니다. 위에서 언급한 각각의 복잡한 문제를 관리형 I/O를 통해 어떻게 해결하는지 아래에서 자세히 설명합니다.
Apache Beam은 많은 변환과 기능, 최적화를 모두 갖춘 SDK입니다. 많은 대규모 소프트웨어와 마찬가지로, Beam을 새 버전으로 업그레이드하는 것은 중요한 프로세스가 될 수 있습니다. Beam을 업그레이드하려면 보통 모든 I/O 커넥터를 포함하여 파이프라인의 모든 부분을 업그레이드해야 합니다. 하지만 때로는 파이프라인에 사용되는 하나 이상의 I/O 커넥터 최신 버전에서 이용 가능한 중요한 버그 수정 또는 개선 사항에 대한 액세스 권한만 있으면 됩니다.
Managed I/O with Dataflow simplifies this by completely taking over the management of the Beam I/O connector version. With Managed I/O, Dataflow will make sure that I/O connectors used by pipelines are always up to date. Dataflow performs this by always upgrading I/O connectors to the latest vetted version during job submission and streaming update via replacement.
For example, assume that you use a Beam pipeline that uses Beam 2.x.0 and assume that you use the Managed Apache Iceberg I/O source in your pipeline. Also, assume that the latest vetted version of the Iceberg I/O source supported by Dataflow is 2.y.0. During job submission, Dataflow will replace this specific connector with version 2.y.0 and will keep the rest of the Beam pipeline including any standard (non-managed) I/O connectors at version 2.x.0.
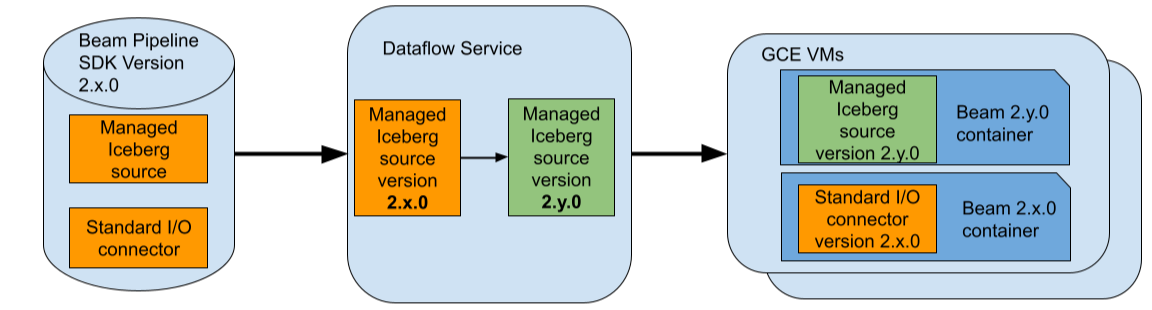
교체 후 Dataflow는 업데이트된 파이프라인을 최적화하고 GCE에서 실행합니다. 다른 Beam 버전의 커넥터 간 격리를 위해, Dataflow는 GCE VM에 Beam SDK 컨테이너를 추가로 배포합니다. 따라서 이 경우에는 두 버전 2.x.0과 2.y.0의 Beam SDK 컨테이너가 Dataflow 작업에 사용되는 각 GCE VM에서 실행됩니다.
따라서 관리형 I/O를 사용하면 파이프라인에 사용되는 I/O 커넥터가 항상 최신 상태가 되도록 보장할 수 있습니다. 이를 통해 사용자는 단순히 I/O 커넥터 업데이트를 위해 Beam 버전 업그레이드에 대해 신경 쓸 필요 없이 파이프라인의 비즈니스 로직 개선에 집중할 수 있습니다.
Beam I/O 커넥터 간의 API 차이는 크게 변화합니다. 즉, 새 Beam I/O 커넥터를 사용하려고 할 때마다 해당 커넥터에 고유한 API를 배워야 합니다. 일부 API는 상당히 크고 직관적이지 않을 수 있습니다. 이는 다음과 같은 이유 때문일 수 있습니다.
상기한 사항들로 인해 일부 커넥터는 API 표시 영역이 너무 커져 신규 고객이 효율적으로 사용하기에는 직관적이지 않습니다.
Managed I/O offers standardized Java and Python APIs for supported I/O connectors. For example, with Beam Java SDK an I/O connector source can be instantiated in the following standardized form.
Managed.read(SOURCE).withConfig(sourceConfig)An I/O connector sink can be instantiated in the following form.
Managed.write(SINK).withConfig(sinkConfig)Here SOURCE and SINK are keys specifically identifying the connector while sourceConfig and sinkConfig are maps of configurations used to instantiate the connector source or sink. The map of configurations may also be provided as YAML files available locally or in Google Cloud Storage. Please see the Managed I/O website for more complete examples for supported sources and sinks.
Beam Python SDK는 비슷하게 단순화된 API를 제공합니다.
즉, 서로 다른 API를 사용하는 다양한 Beam I/O 커넥터를 매우 표준적인 방식으로 인스턴스화할 수 있습니다. 예를 들면 다음과 같습니다.
// Java BigQuery I/O 소스를 만듭니다.
Map<String, Object> bqReadConfig = ImmutableMap.of("query", "<query>", ...);
Managed.read(Managed.BIGQUERY).withConfig(bqReadConfig)
// Java Kafka I/O 소스를 만듭니다.
Map<String, Object> kafkaReadConfig = ImmutableMap.of("bootstrap_servers", "<server>", "topic", "<topic>", ...);
Managed.read(Managed.KAFKA).withConfig(kafkaReadConfig)
// Java Kafka I/O 소스를 만들되, Google Cloud Storage에서 제공되는 YAML 기반 구성을 사용합니다.
String kafkaReadYAMLConfig = "gs://path/to/config.yaml"
Managed.read(Managed.KAFKA).withConfigUrl(kafkaReadYAMLConfig)
// Python Iceberg I/O 소스를 만듭니다.
iceberg_config = {"table": "<table>", ...}
managed.Read(managed.ICEBERG, config=iceberg_config)많은 Beam 커넥터는 주어진 파이프라인과 주어진 Beam 러너에 맞는 커넥터를 구성하고 최적화하기 위한 포괄적인 API를 제공합니다. 이 API의 한 가지 단점은 특별히 Dataflow에서 실행하고자 한다면 Dataflow에 가장 적합한 특정 구성을 학습하여 파이프라인을 설정할 때 적용해야 할 수도 있다는 점입니다. 커넥터 관련 문서가 길고 상세할 수 있으며 필요한 특정 변경 사항이 직관적이지 않을 수도 있습니다. 이로 인해 Dataflow 파이프라인에 사용되는 커넥터가 차선의 방식으로 작동할 수도 있습니다.
관리형 I/O 커넥터는 모범 사례를 통합하고 Dataflow에 가장 적합하도록 구성할 수 있도록 커넥터를 자동으로 재구성함으로써 이 문제를 완화합니다. 이러한 재구성은 작업 제출 또는 교체를 통한 스트리밍 업데이트 중에 발생할 수 있습니다.
예를 들어, Dataflow 스트리밍 파이프라인은 '정확히 한 번'과 '최소한 한 번'의 두 가지 모드를 제공하며 Storage Write API를 사용하는 BigQuery I/O 싱크는 '정확히 한 번'과 '최소한 한 번'의 두 가지 유사한 전달 보장 방식을 제공합니다. '최소한 한 번' 전달 보장 방식을 사용하는 BigQuery 싱크는 보통 비용이 적게 들고 지연 시간이 줄어듭니다. 표준 BigQuery I/O 커넥터를 사용할 경우 BigQuery I/O 사용 시 적절한 모드를 사용해야 합니다. 관리형 BigQuery I/O 싱크를 사용할 경우에는 적절한 모드가 자동으로 구성됩니다. 즉, 스트리밍 파이프라인이 '최소한 한 번' 모드로 작동 중이라면 관리형 I/O BigQuery 싱크가 '최소한 한 번' 전달 보장 방식을 사용하도록 자동으로 구성됩니다.
저희는 GCS에 배포된 Hadoop 카탈로그를 기반으로 하는 관리형 Iceberg I/O 싱크를 사용하여 데이터를 작성한 여러 파이프라인을 실행했습니다(지원되는 다른 카탈로그는 여기 참조). 파이프라인은 Beam 2.61.0을 사용하여 제출되었으며 Dataflow에 의해 관리형 I/O 싱크는 지원되는 최신 버전으로 자동 업그레이드되었습니다. 모든 업계 기준치에서는 n1-standard-4 VM을 사용했으며 파이프라인에서 사용되는 VM 수는 100개로 고정되었습니다. 이때 실행 시간에는 시작 시간과 종료 시간이 포함되지 않음을 유념해 주십시오.
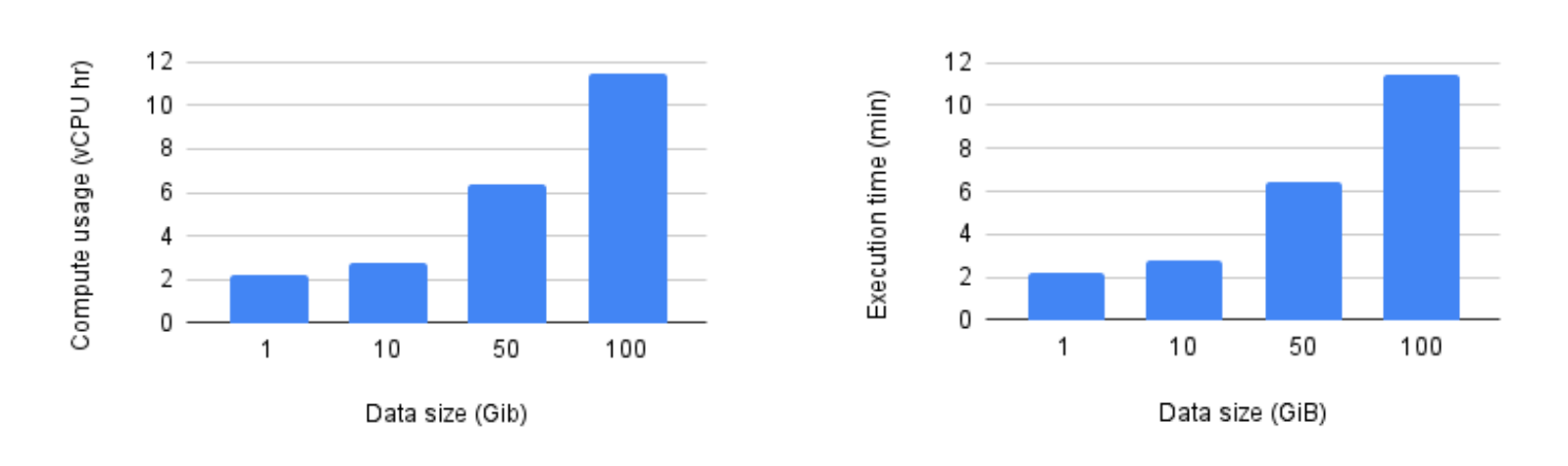
업계 기준치에서 알 수 있듯이, 관리형 Iceberg I/O는 훌륭하게 확장되었으며 두 측정항목 모두 데이터 크기에 따라 선형적으로 증가했습니다.
또한 Google Pub/Sub에서 읽은 스트리밍 파이프라인을 실행하고 관리형 I/O Kafka 싱크를 사용하여 GCP에서 호스팅되는 Kafka 클러스터로 메시지를 푸시했습니다. 이 파이프라인은 Beam 2.61.0을 사용했으며 Dataflow는 관리형 Kafka 싱크를 최신 지원 버전으로 업그레이드했습니다. 정상 상태에 있는 동안 파이프라인은 10개의 n1-standard-4 VM(최대 20개의 VM)을 사용했습니다. 파이프라인은 모든 단계에서 초당 250k개의 메시지를 지속적으로 처리했고 2시간 동안 실행되었습니다.
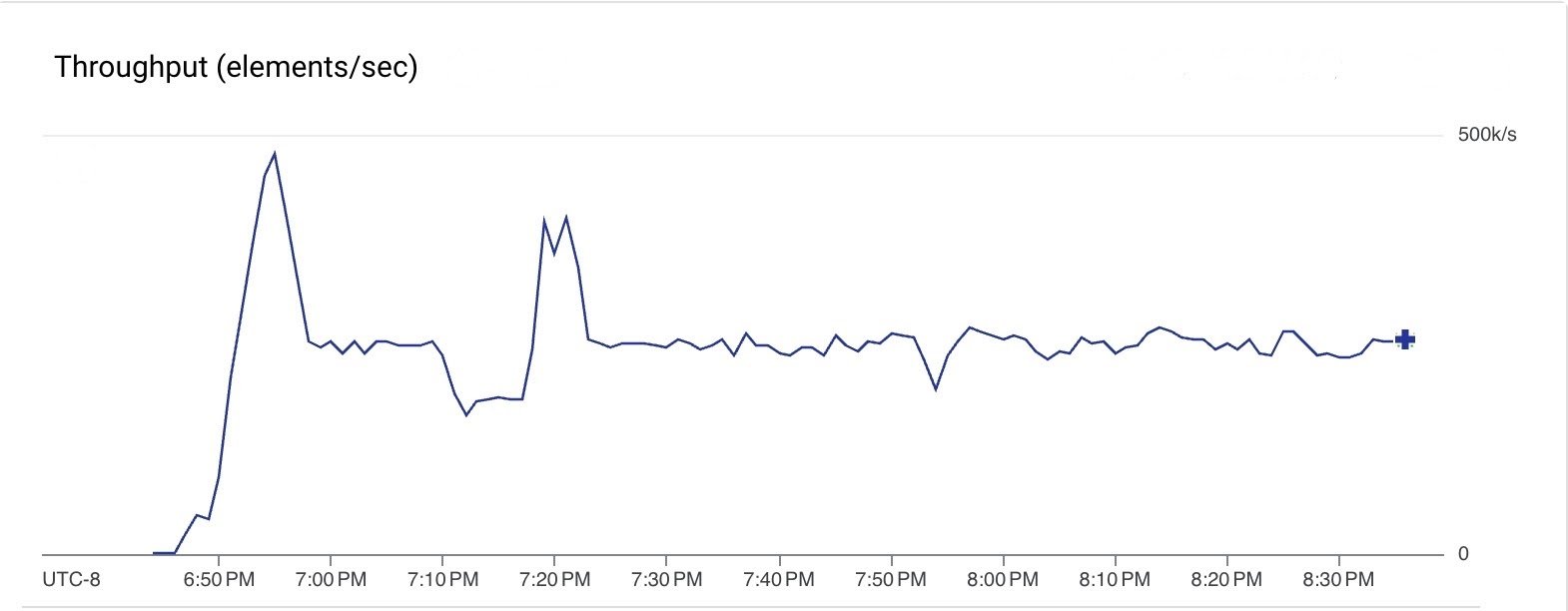
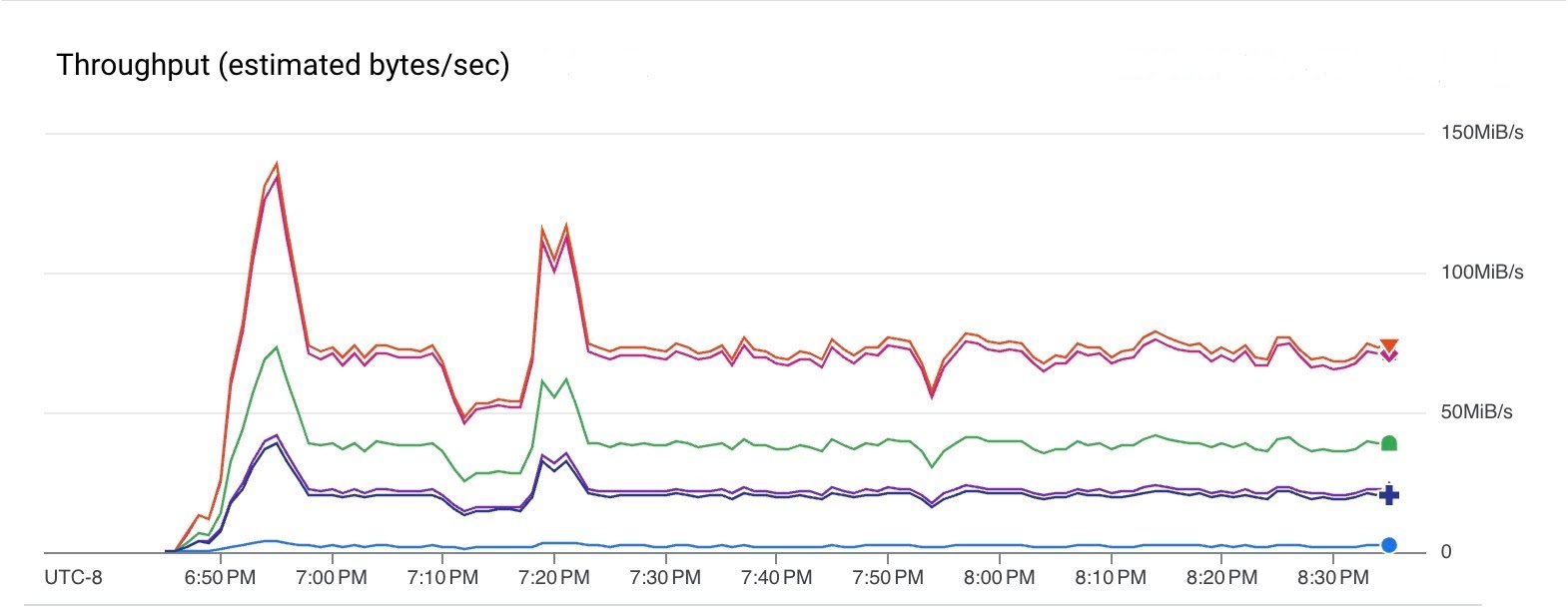
다음 그래프에서는 파이프라인의 다양한 단계에서 데이터 처리량을 보여줍니다. 단계마다 요소 크기가 변하므로 처리량이 다릅니다. 파이프라인은 Pub/Sub에서 75 MiB/sec(빨간색 선)의 속도로 읽었고 Kafka에 40 MiB/sec(녹색 선)의 속도로 썼습니다.
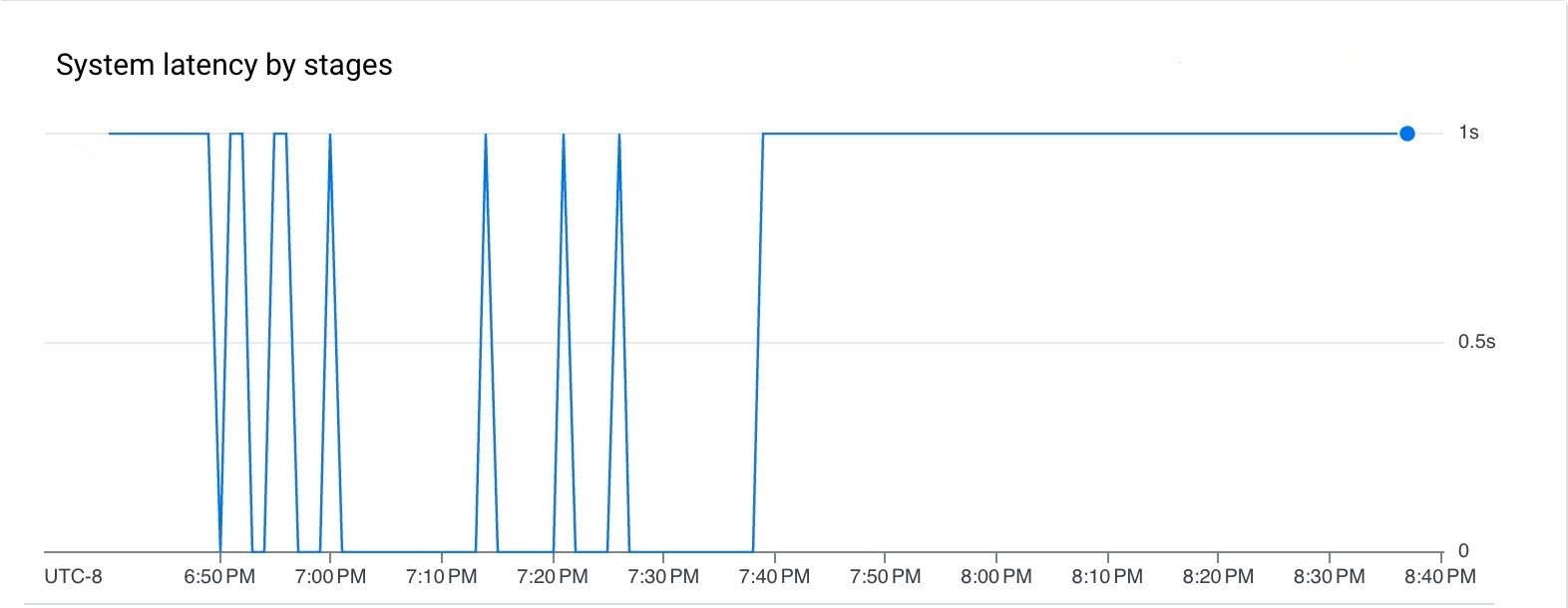
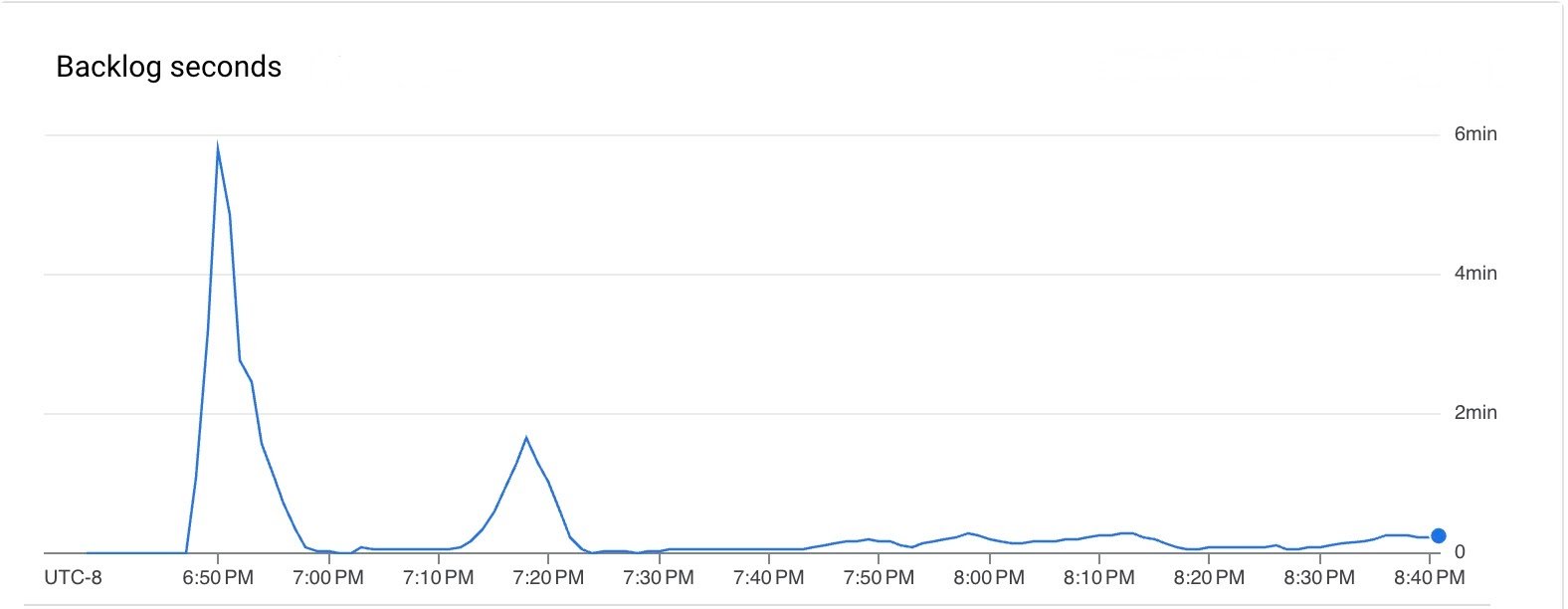
파이프라인 실행 기간 동안 지연 시간과 백로그가 모두 낮았습니다.
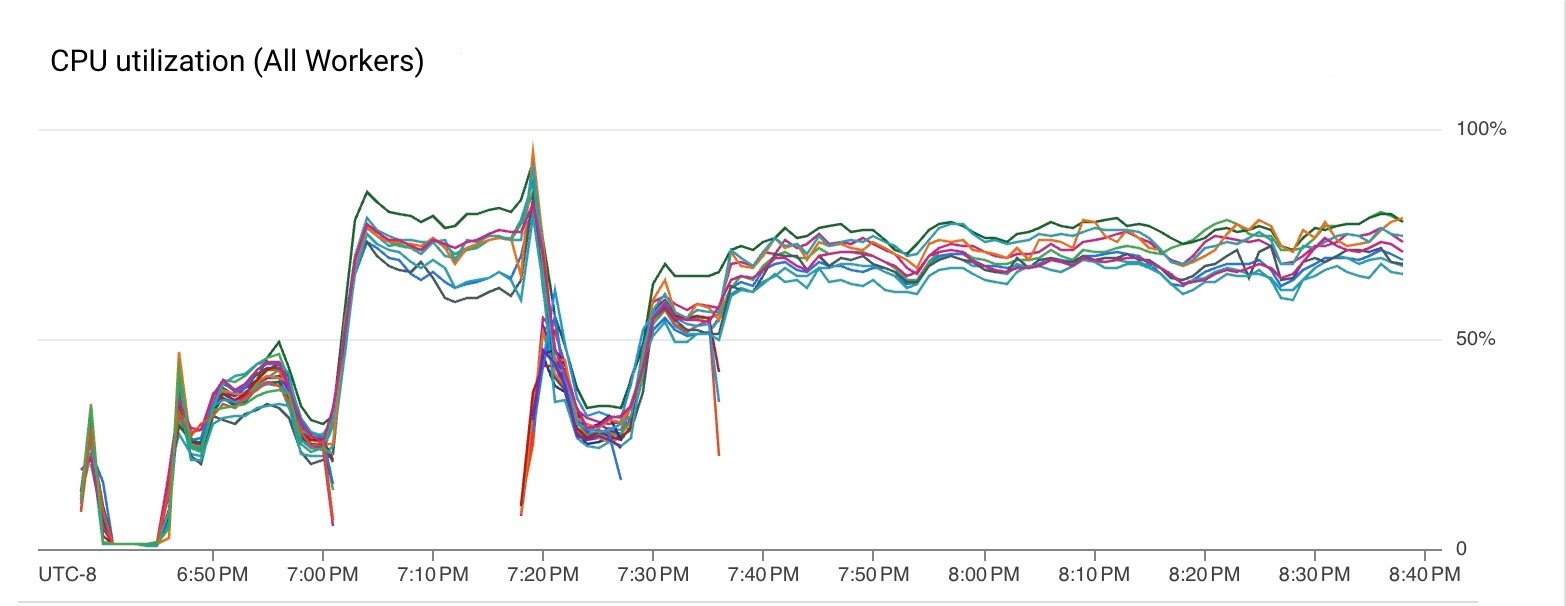
파이프라인은 VM CPU와 메모리를 효율적으로 사용했습니다.
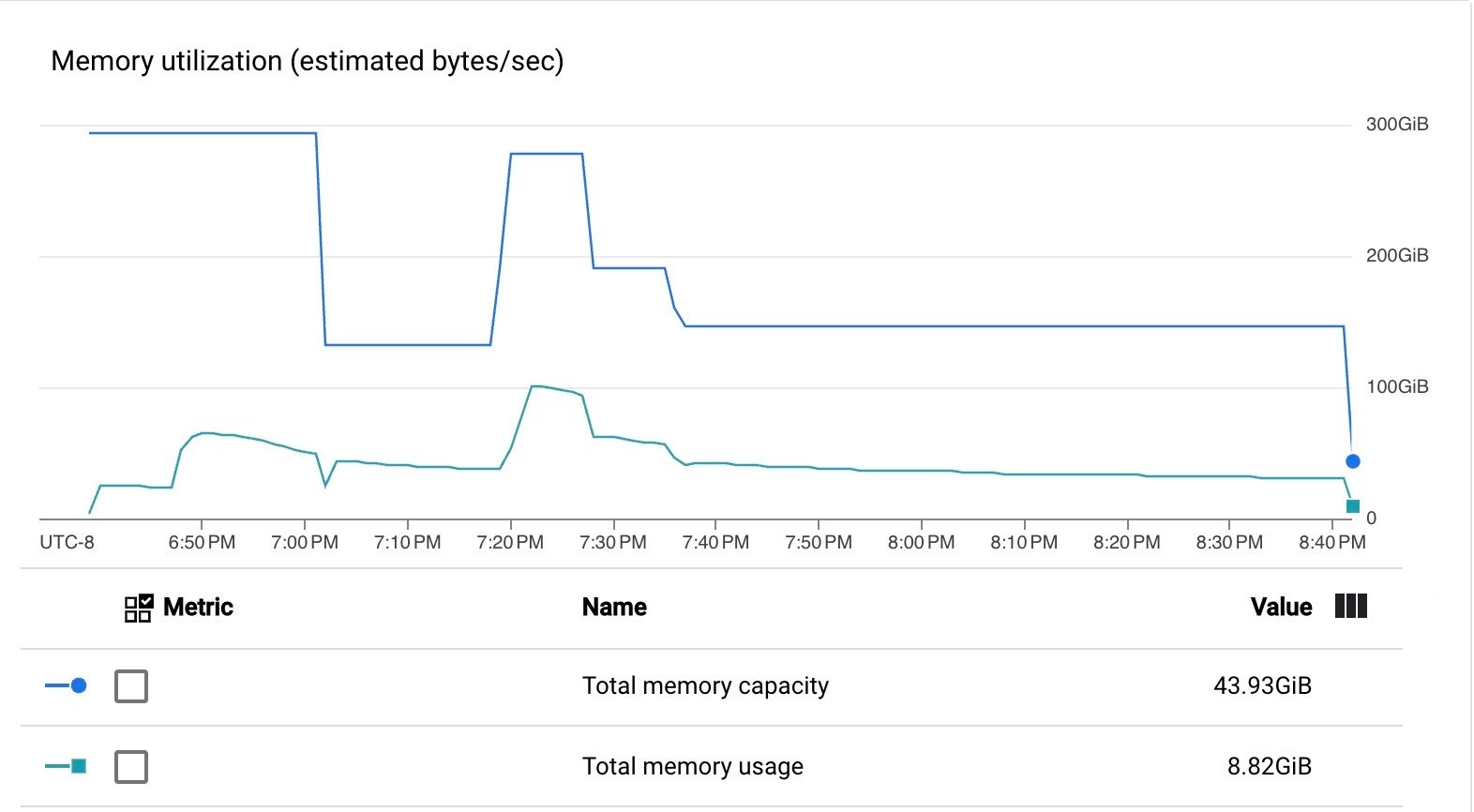
이러한 결과에서 알 수 있듯이 파이프라인은 Dataflow 서비스가 제공하는 업그레이드된 관리형 I/O Kafka 싱크로 효율적으로 실행되었습니다.
파이프라인에서 지원되는 소스와 싱크 중 하나를 사용하고 Dataflow Runner v2로 파이프라인을 실행하기만 하면 간단히 관리형 I/O를 사용할 수 있습니다. 파이프라인을 실행할 때 파이프라인에 이전 Beam 버전을 사용한다 하더라도 Dataflow는 작업 제출 및 교체를 통한 스트리밍 업데이트 중에 검증된 최신 버전의 소스와 싱크가 활성화되도록 보장합니다.

Building production AI on Google Cloud TPUs with JAX

Announcing the Data Commons Gemini CLI extension

Google Colab is Coming to VS Code

Stanford의 Marin 파운데이션 모델: JAX를 사용하여 개발된 최초의 완전 개방형 모델

Building with Gemini 3 in Jules

Firebase Studio로 에이전트 AI 개발 진전