
Google Cloud Dataflow offers a fully managed data processing system for running Apache Beam pipelines on Google Cloud in a highly scalable manner. Due to being a fully managed service, Dataflow users do not have to worry about any service side regressions and versioning. The promise is that you only concern yourself with your pipeline logic while Google takes care of the service infrastructure. While this is certainly true, Apache Beam itself is a very full featured SDK that provides many simple to highly complex transforms for you to use in their pipelines. For example, Apache Beam provides a number of I/O connectors. Many of these connectors are Apache Beam composite transforms from 10s to 100s of steps. Historically, these have been considered "user code" from the service's perspective, despite being not authored or maintained by the user. There are several common complications customers run into complex Beam transforms such as I/O connectors.
To alleviate all three of these issues, Dataflow recently introduced a new offering named Managed I/O. With Managed I/O the service itself is able to manage these complexities on your behalf. Hence you can truly focus on their pipelines business logic instead of focussing on the minutiae related to using and configuring a specific connector to suit their needs. Below we detail how each of the above mentioned complexities are addressed via Managed I/O.
Apache Beam is a fully fledged SDK with many transforms, features, and optimization. Like many large pieces of software, upgrading Beam to a new version can be a significant process. Usually upgrading Beam involves upgrading all parts of a pipeline including all I/O connectors. But sometimes, you just need to obtain access to a critical bug fix or an improvement available in the latest version of one or more I/O connectors used in your pipeline.
Managed I/O with Dataflow simplifies this by completely taking over the management of the Beam I/O connector version. With Managed I/O, Dataflow will make sure that I/O connectors used by pipelines are always up to date. Dataflow performs this by always upgrading I/O connectors to the latest vetted version during job submission and streaming update via replacement.
For example, assume that you use a Beam pipeline that uses Beam 2.x.0 and assume that you use the Managed Apache Iceberg I/O source in your pipeline. Also, assume that the latest vetted version of the Iceberg I/O source supported by Dataflow is 2.y.0. During job submission, Dataflow will replace this specific connector with version 2.y.0 and will keep the rest of the Beam pipeline including any standard (non-managed) I/O connectors at version 2.x.0.
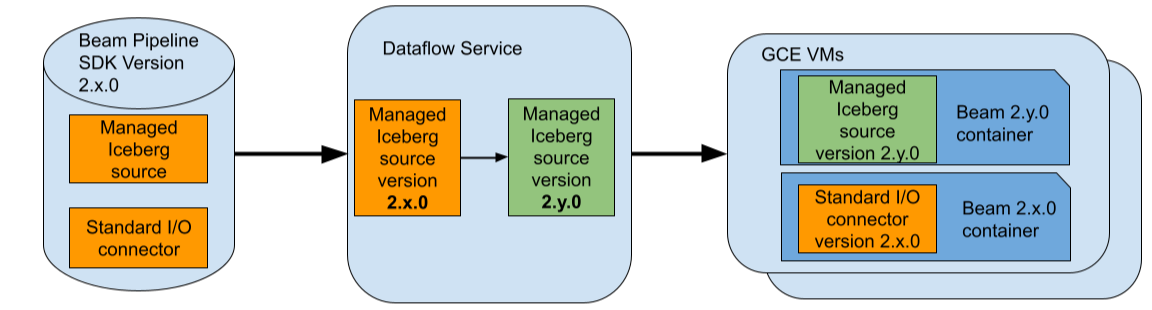
After replacement, Dataflow optimizes the updated pipeline and executes it in GCE. To achieve isolation between connectors from different Beam versions, Dataflow deploys an additional Beam SDK container in GCE VMs. So in this case, Beam SDK containers from both versions 2.x.0 and 2.y.0 will be running in each GCE VM used by the Dataflow job.
So with Managed I/O you can be assured that I/O connectors used in your pipeline are always up to date. This allows you to focus on improving the business logic of your pipeline without worrying about upgrading the Beam version to simply obtain I/O connector updates.
APIs differences across Beam I/O connectors vary greatly. This means that, whenever you try to use a new Beam I/O connector, you would have to learn an API specific to that connector. Some of the APIs can be quite large and non-intuitive. This can be due to:
Above points result in very large API surfaces for some connectors that are not intuitive for a new customer to use efficiently.
Managed I/O offers standardized Java and Python APIs for supported I/O connectors. For example, with Beam Java SDK an I/O connector source can be instantiated in the following standardized form.
Managed.read(SOURCE).withConfig(sourceConfig)An I/O connector sink can be instantiated in the following form.
Managed.write(SINK).withConfig(sinkConfig)Here SOURCE and SINK are keys specifically identifying the connector while sourceConfig and sinkConfig are maps of configurations used to instantiate the connector source or sink. The map of configurations may also be provided as YAML files available locally or in Google Cloud Storage. Please see the Managed I/O website for more complete examples for supported sources and sinks.
Beam Python SDK offers a similarly simplified API.
This means that various Beam I/O connectors with different APIs can be instantiated in a very standard way. For example,
// Create a Java BigQuery I/O source
Map<String, Object> bqReadConfig = ImmutableMap.of("query", "<query>", ...);
Managed.read(Managed.BIGQUERY).withConfig(bqReadConfig)
// Create a Java Kafka I/O source.
Map<String, Object> kafkaReadConfig = ImmutableMap.of("bootstrap_servers", "<server>", "topic", "<topic>", ...);
Managed.read(Managed.KAFKA).withConfig(kafkaReadConfig)
// Create a Java Kafka I/O source but with a YAML based config available in Google Cloud Storage.
String kafkaReadYAMLConfig = "gs://path/to/config.yaml"
Managed.read(Managed.KAFKA).withConfigUrl(kafkaReadYAMLConfig)
// Create a Python Iceberg I/O source.
iceberg_config = {"table": "<table>", ...}
managed.Read(managed.ICEBERG, config=iceberg_config)Many Beam connectors offer a comprehensive API for configuring and optimizing the connector to suit a given pipeline and a given Beam runner. One downside of this is that if you specifically want to run on Dataflow, you may have to learn the specific configurations that best suit Dataflow and apply them when setting up your pipeline. Connector related documentation can be long and detailed and specific changes needed might not be intuitive. This might result in connectors used in Dataflow pipelines performing in a sub-optimal way.
Manage I/O connectors alleviates this by automatically re-configuring the connectors to incorporate best practices and configure them to best suit Dataflow. Such re-configuration may occur during job submission or streaming update via replacement.
For example, Dataflow streaming pipelines offer two modes, exactly-once and at-least-once while BigQuery I/O sink with Storage Write API offer two analogous delivery semantics, exactly-once and at-least-once. BigQuery sink with at-least-once delivery semantics is usually less expensive and results in lower latencies. With standard BigQuery I/O connectors, you are responsible for making sure that you use the appropriate mode when using the BigQuery I/O. With Managed BigQuery I/O sink this is automatically configured for you. Which means that if your streaming pipeline is operating at the at-least-once mode, your Managed I/O BigQuery sink will be automatically configured to use the at-least-once delivery semantics.
We ran several pipelines that wrote data using the Managed Iceberg I/O sink backed by a Hadoop catalog deployed in GCS (please see here for the other supported catalogs). Pipelines were submitted using Beam 2.61.0 and the Managed I/O sink was automatically upgraded by Dataflow to the latest supported version. All benchmarks used n1-standard-4 VMs and the number of VMs used by the pipeline was fixed to 100. Please note that execution time here does not include the startup and shutdown time.
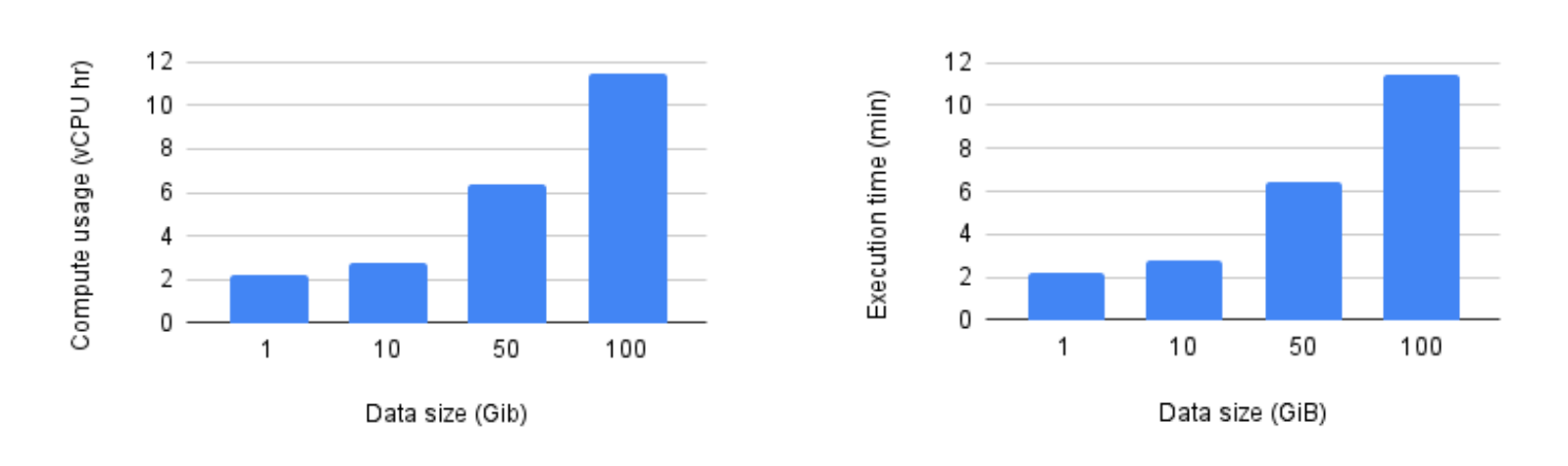
As the benchmarks show, Managed Iceberg I/O scaled up nicely and both metrics grew linearly with the data size.
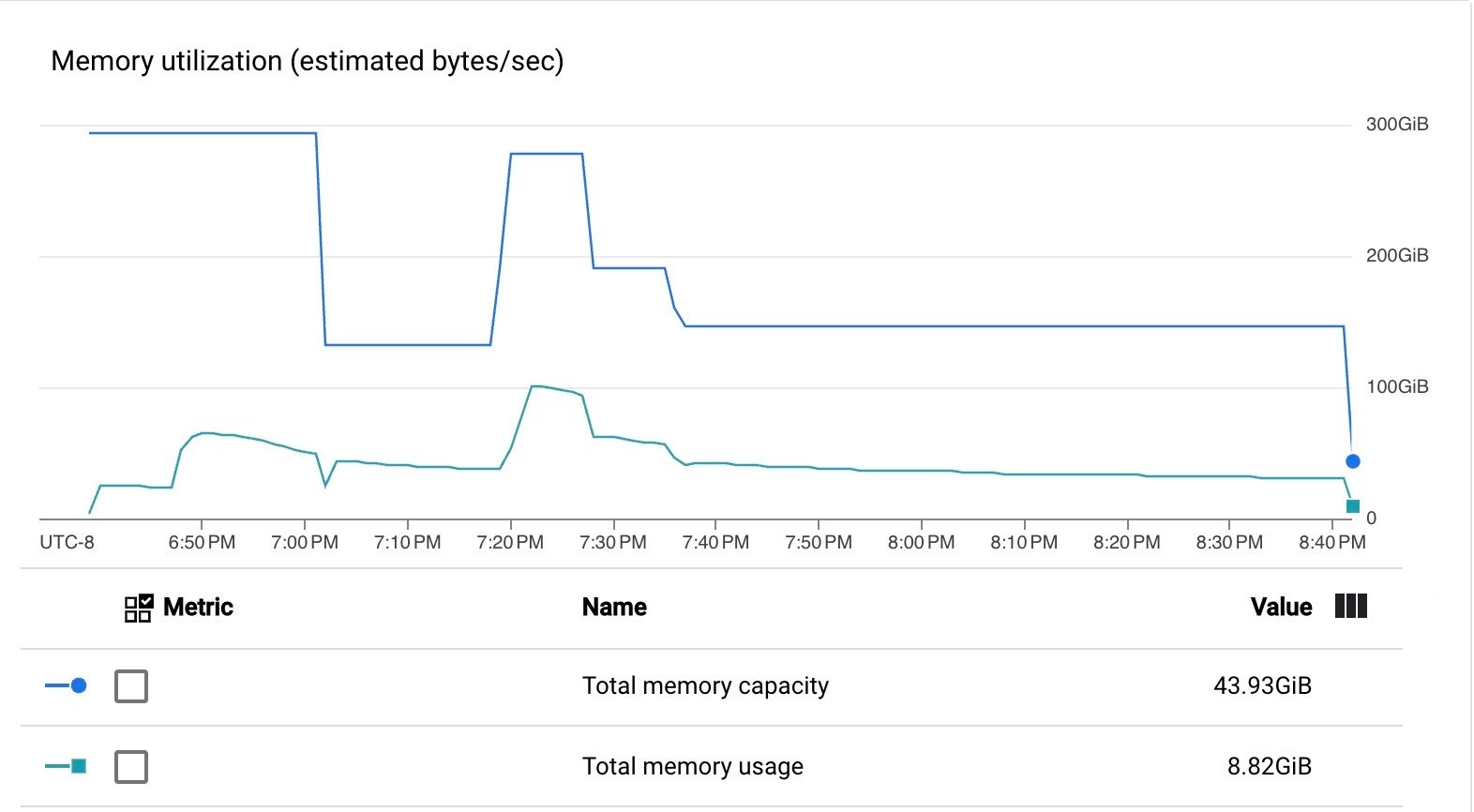
We also ran a streaming pipeline that read from Google Pub/Sub and used the Managed I/O Kafka sink to push messages to a Kafka cluster hosted in GCP. The pipeline used Beam 2.61.0 and Dataflow upgraded the Managed Kafka sink to the latest supported version. During the steady state, the pipeline used 10 n1-standard-4 VMs (max 20 VMs). The pipeline was consistently processing messages at a throughput of 250k msgs/sec across all steps and was run for 2 hours.
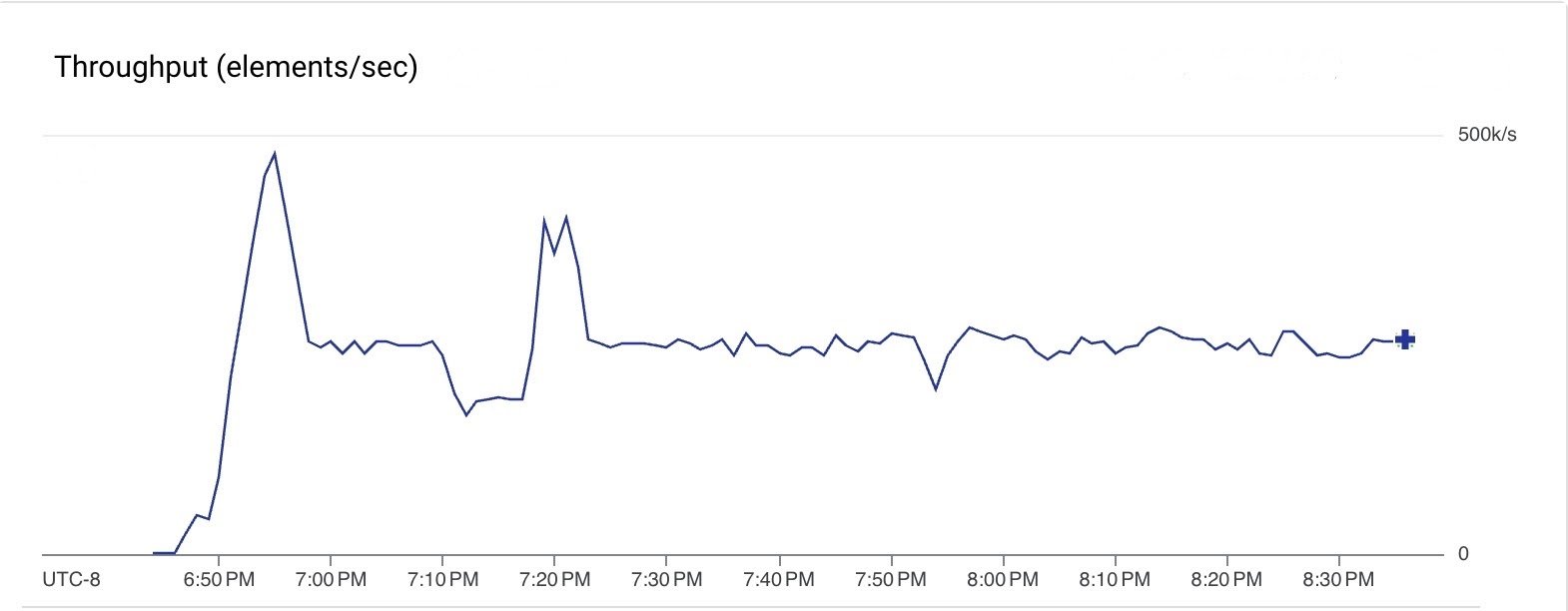
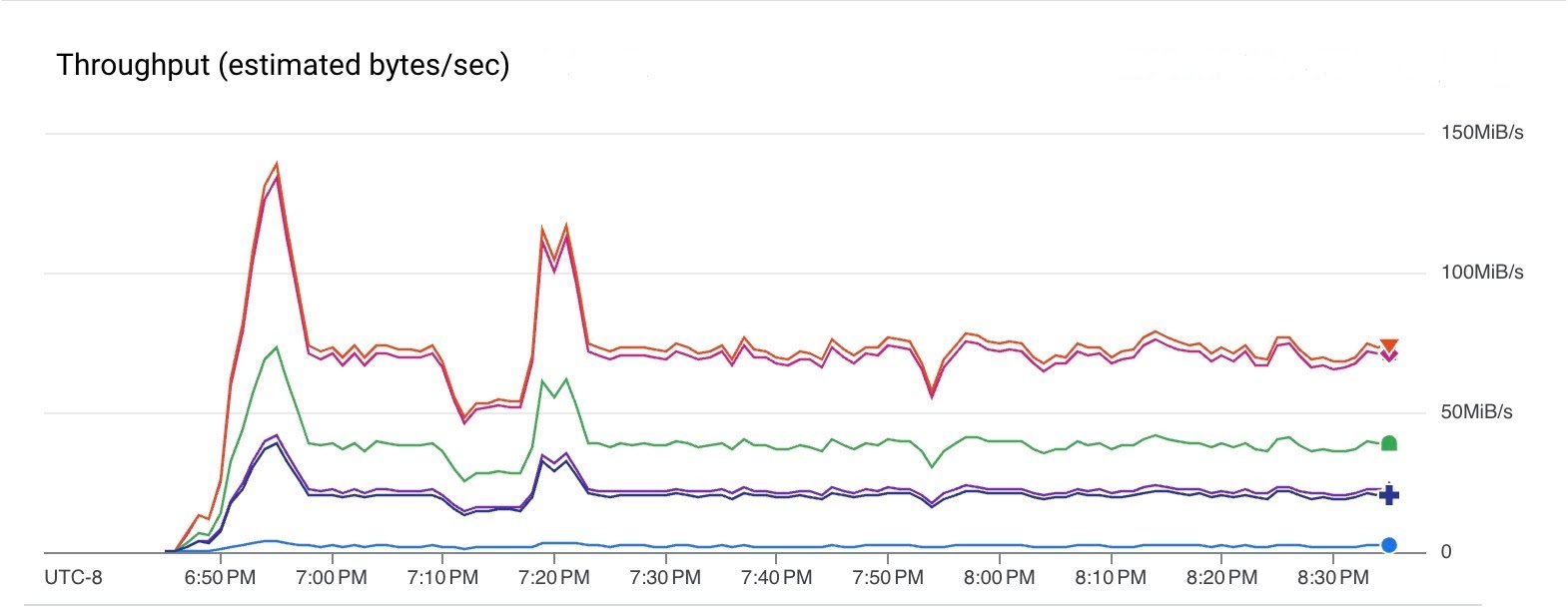
The following graph shows the data throughputs of various steps of the pipeline. Note that throughputs are different here since the element size changes between steps. The pipeline read from Pub/Sub at a rate of 75 MiB/sec (red line) and wrote to Kafka at a rate of 40 MiB/sec (green line).
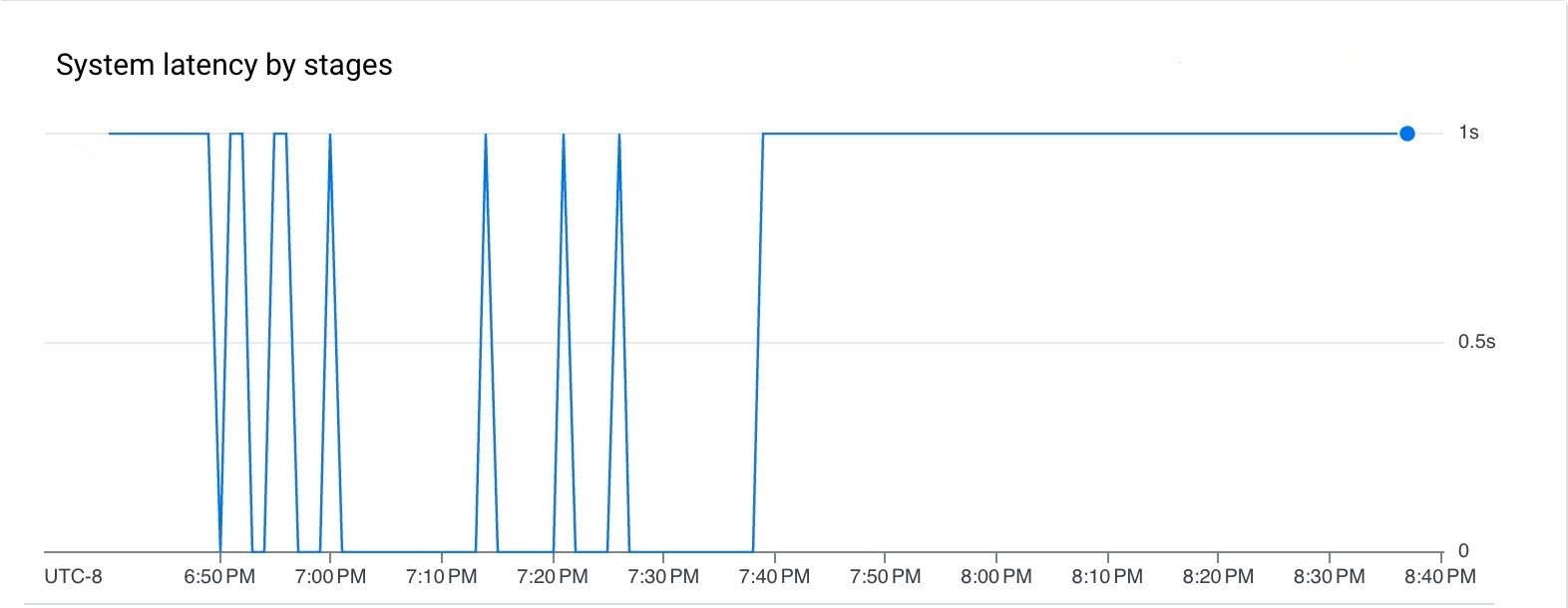
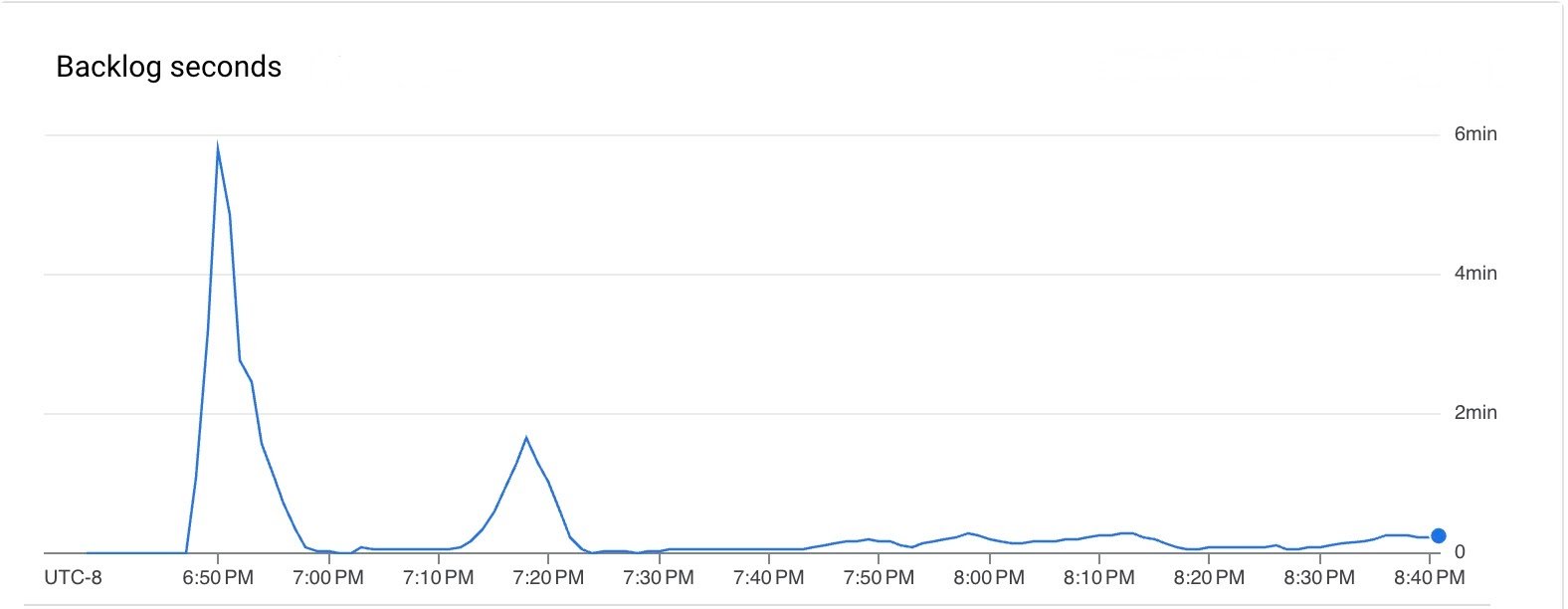
Both latency and backlog was low for the duration of the pipeline execution.
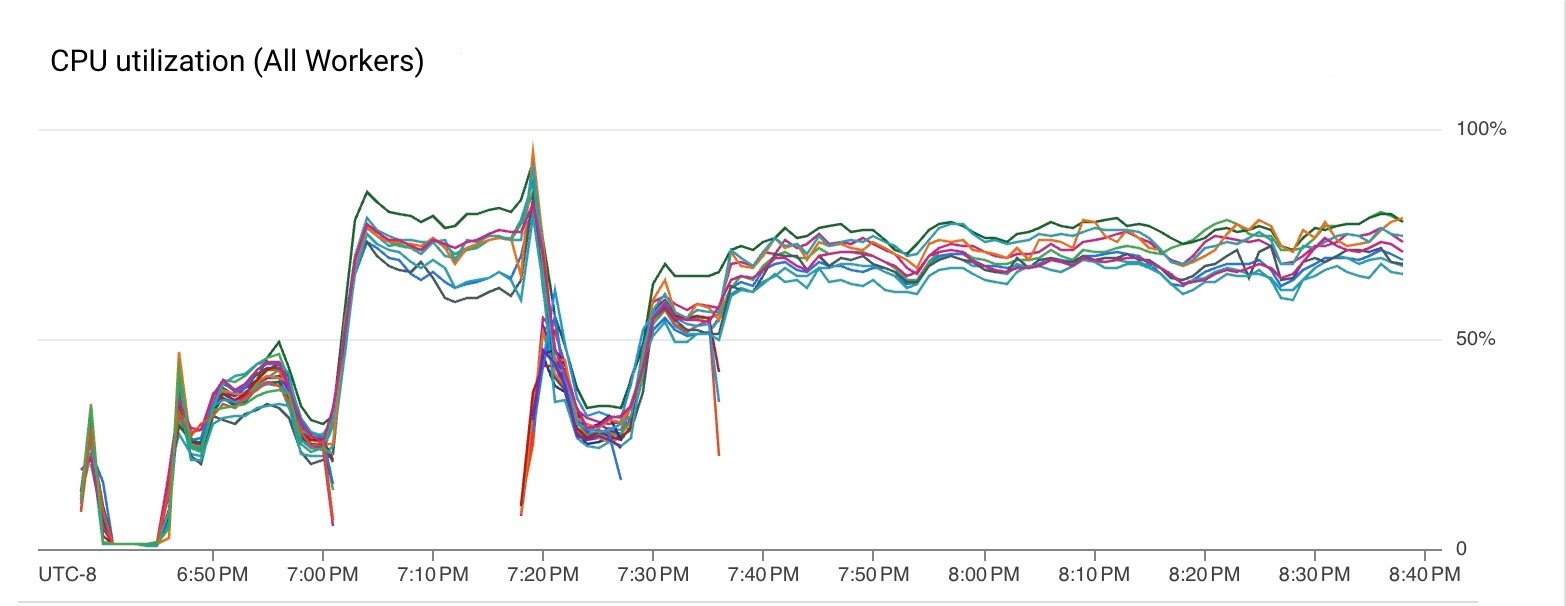
The pipeline used VM CPU and memory efficiently.
As these results show, the pipeline executed efficiently with the upgraded Managed I/O Kafka sink provided by the Dataflow service.
Using Managed I/O is simple as using one of the supported sources and sinks in your pipeline and running the pipeline with Dataflow Runner v2. When you run your pipeline, Dataflow will make sure that the latest vetted versions of the sources and sinks are enabled during job submission and streaming update via replacement, even if you are using an older Beam version for your pipeline.

An important update: Transitioning Gemini CLI to Antigravity CLI

All the news from the Google I/O 2026 Developer keynote

Speeding Up AI: Bringing Google Colossus to PyTorch via GCSFS and Rapid Bucket

One Year of Innovation: Celebrating 100k Members in the Google Cloud x NVIDIA Developer Community

Empowering Service Providers and Hardware Partners with Gemini for Home