
フルマネージド データ処理システムである Google Cloud Dataflow は、Google Cloud で非常にスケーラブルな形で Apache Beam パイプラインを実行できます。フルマネージド サービスであるため、Dataflow ユーザーはサービス側のリグレッションやバージョン管理について心配する必要はありません。Google がサービス インフラストラクチャを管理するので、皆さんはパイプラインのロジックだけに集中できるようになります。この事実に加えて、Apache Beam 自体はフル機能の SDK なので、多くのシンプルな変換から非常に複雑な変換まで、パイプラインでさまざまな変換を利用できます。たとえば、Apache Beam は多くの I/O コネクタを提供しています。こういったコネクタの多くは、数十から数百ステップの Apache Beam コンポジット変換です。こういった変換は、ユーザーが作成または管理しているものではないのに、サービス側では、以前から「ユーザーコード」だと考えられてきました。そのため、I/O コネクタなどの複雑な Beam 変換を行うと、いくつかの問題に遭遇することになります。
この 3 つの問題すべてを軽減するため、先日より Dataflow でマネージド I/O という新サービスを導入しました。マネージド I/O を使うと、サービス自体が皆さんに代わって複雑な問題を管理してくれます。したがって、ニーズに合わせて特定のコネクタを使ったり設定したりといった細かい部分を気にすることなく、パイプラインのビジネス ロジックに集中できます。以下では、マネージド I/O でどのようにして前述の複雑な問題それぞれに対処するのかについて、詳しく説明します。
Apache Beam は本格的な SDK で、多くの変換や機能が搭載され、最適化されています。多くの大規模ソフトウェアと同じく、Beam を新しいバージョンにアップグレードするのは、大変な作業になる可能性があります。通常、Beam をアップグレードすると、すべての I/O コネクタを含むパイプラインのすべての部分がアップグレードされます。しかし、重要なバグ修正のみ必要な場合や、パイプラインで使っている 1 つまたは複数の I/O コネクタだけを最新バージョンにしたい場合もあります。
Managed I/O with Dataflow simplifies this by completely taking over the management of the Beam I/O connector version. With Managed I/O, Dataflow will make sure that I/O connectors used by pipelines are always up to date. Dataflow performs this by always upgrading I/O connectors to the latest vetted version during job submission and streaming update via replacement.
For example, assume that you use a Beam pipeline that uses Beam 2.x.0 and assume that you use the Managed Apache Iceberg I/O source in your pipeline. Also, assume that the latest vetted version of the Iceberg I/O source supported by Dataflow is 2.y.0. During job submission, Dataflow will replace this specific connector with version 2.y.0 and will keep the rest of the Beam pipeline including any standard (non-managed) I/O connectors at version 2.x.0.
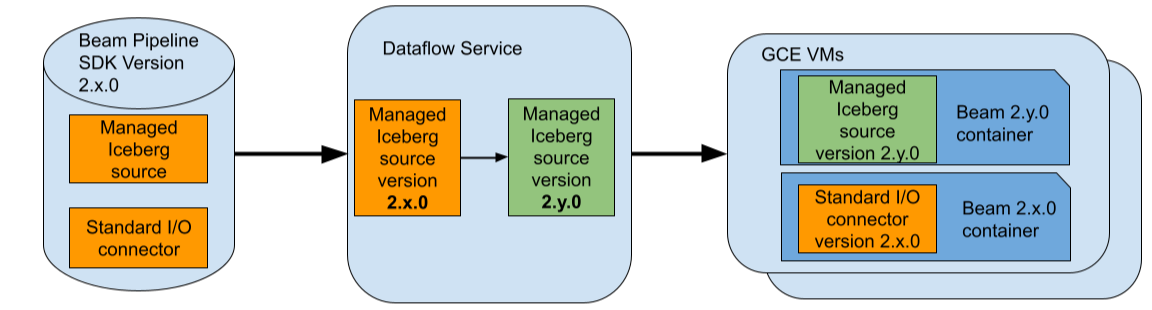
置換後、Dataflow は更新したパイプラインを最適化し、GCE で実行します。各コネクタを別の Beam バージョンから分離するために、Dataflow は GCE VM に追加の Beam SDK コンテナをデプロイします。したがって、この例では、Dataflow ジョブに使うそれぞれの GCE VM で、バージョン 2.x.0 と 2.y.0 の両方の Beam SDK コンテナが実行されます。
つまり、マネージド I/O では、パイプラインで使われる I/O コネクタが常に最新の状態であることが保証されます。そのため、I/O コネクタの更新のためだけに Beam バージョンをアップグレードすることについて心配する必要なく、パイプラインのビジネス ロジック改善に集中できるようになります。
Beam I/O コネクタ間で API は大きく異なっています。つまり、新しい Beam I/O コネクタを使うたびに、そのコネクタに固有の API を学習しなければなりません。また、巨大で直感的でない API もあります。これには、次のような理由が考えられます。
以上のような理由で、一部のコネクタの API サーフェスは巨大になっており、新規ユーザーが直感的かつ効率的に利用することはできなくなっています。
Managed I/O offers standardized Java and Python APIs for supported I/O connectors. For example, with Beam Java SDK an I/O connector source can be instantiated in the following standardized form.
Managed.read(SOURCE).withConfig(sourceConfig)An I/O connector sink can be instantiated in the following form.
Managed.write(SINK).withConfig(sinkConfig)Here SOURCE and SINK are keys specifically identifying the connector while sourceConfig and sinkConfig are maps of configurations used to instantiate the connector source or sink. The map of configurations may also be provided as YAML files available locally or in Google Cloud Storage. Please see the Managed I/O website for more complete examples for supported sources and sinks.
同じように、Beam Python SDK でもシンプルな API が提供されます。
これを使うと、異なる API を持つさまざまな Beam I/O コネクタを、きわめて標準的な方法でインスタンス化できます。次の例をご覧ください。
// Java BigQuery I/O ソースの作成
Map<String, Object> bqReadConfig = ImmutableMap.of("query", "<query>", ...);
Managed.read(Managed.BIGQUERY).withConfig(bqReadConfig)
// Java Kafka I/O ソースの作成
Map<String, Object> kafkaReadConfig = ImmutableMap.of("bootstrap_servers", "<server>", "topic", "<topic>", ...);
Managed.read(Managed.KAFKA).withConfig(kafkaReadConfig)
// Java Kafka I/O ソースを Google Cloud Storage にある YAML ベースの設定で作成
String kafkaReadYAMLConfig = "gs://path/to/config.yaml"
Managed.read(Managed.KAFKA).withConfigUrl(kafkaReadYAMLConfig)
// Python Iceberg I/O ソースの作成.
iceberg_config = {"table": "<table>", ...}
managed.Read(managed.ICEBERG, config=iceberg_config)多くの Beam コネクタには包括的な API があり、特定のパイプラインや特定の Beam ランナーに合わせてコネクタを設定したり最適化したりできます。この方法の欠点の 1 つは、特に Dataflow で実行する場合、Dataflow に最適な特定の設定を学習し、そのようにパイプラインを設定しなければならない場合があることです。コネクタ関連のドキュメントには長くて細かいものもあり、必要な変更には直感的でないものもあります。そのため、Dataflow パイプラインで使われるコネクタが最適ではない形で実行される可能性があります。
この問題を軽減するために、マネージド I/O コネクタでは、コネクタを自動的に再構成してベスト プラクティスを反映し、Dataflow に最適な設定を行います。この再構成は、ジョブの送信時やストリーミング アップデート時に置換することによって行います。
たとえば、Dataflow のストリーミング パイプラインには、「厳密に一度」と「少なくとも一度」という 2 つのモードがあります。ストレージ書き込み API を使う BigQuery I/O シンクにも、「厳密に一度」と「少なくとも一度」という 2 つのよく似た配信セマンティクスがあります。通常は、「少なくとも一度」配信セマンティクスの BigQuery シンクの方が安価で、レイテンシが低くなります。標準の BigQuery I/O コネクタでは、BigQuery I/O を使うときに適切なモードを選ぶのはユーザーの責任です。マネージド BigQuery I/O シンクでは、これが自動で設定されます。つまり、ストリーミング パイプラインが「少なくとも一度」モードで動作している場合、マネージド I/O BigQuery シンクが自動設定され、「少なくとも一度」配信セマンティクスが使われます。
Hadoop カタログをバックエンドとして GCS にデプロイし、マネージド Iceberg I/O シンクを使ってデータを書き込むいくつかのパイプラインを実行してみました(その他のサポート対象カタログについては、こちらをご覧ください)。Beam 2.61.0 を使ってパイプラインを送信すると、Dataflow によって、マネージド I/O シンクがサポートされている最新バージョンに自動アップグレードされました。すべてのベンチマークで n1-standard-4 VM を使い、パイプラインが利用する VM の数は 100 に固定しました。ここでの実行時間には、起動時間とシャットダウン時間は含まれていません。
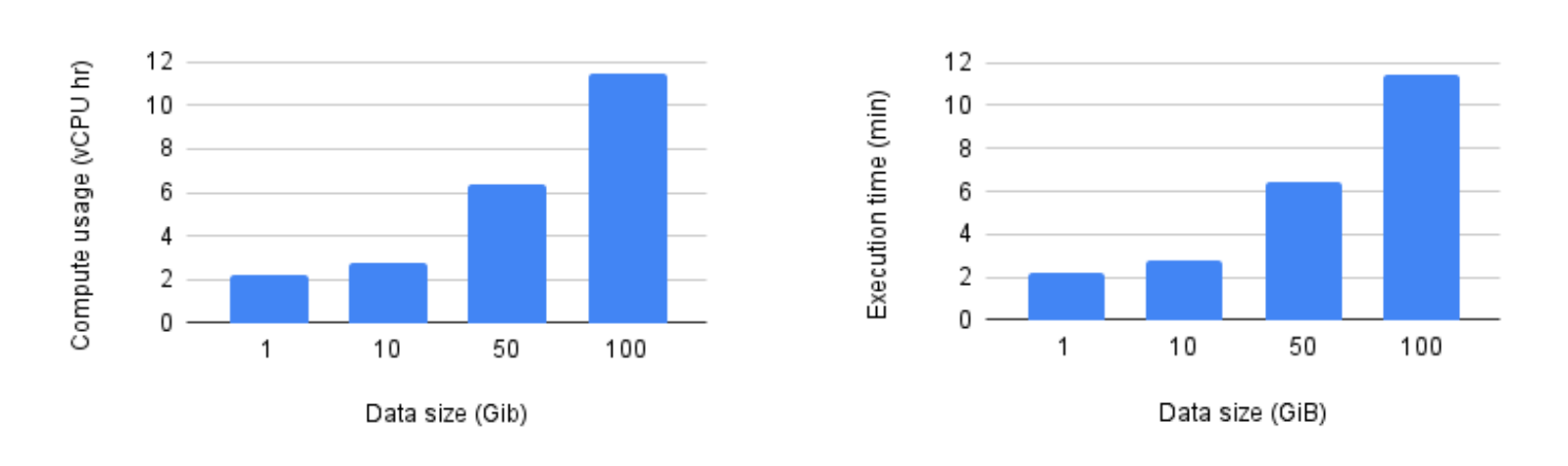
ベンチマークが示すように、マネージド Iceberg I/O は適切にスケールアップされ、どちらの指標もデータサイズとともに直線的に増加しました。
また、Google Pub/Sub から読み取り、マネージド I/O Kafka シンクを使って GCP にホストした Kafka クラスタにメッセージをプッシュするストリーミング パイプラインも実行してみました。このパイプラインには Beam 2.61.0 を使いました。マネージド Kafka シンクは、Dataflow によって、サポートされている最新バージョンにアップグレードされました。定常状態でパイプラインに 10 台(最大 20 台)の n1-standard-4 VM を使い、2 時間にわたって、すべてのステップで 25 万メッセージ/秒のスループットでメッセージが処理されました。
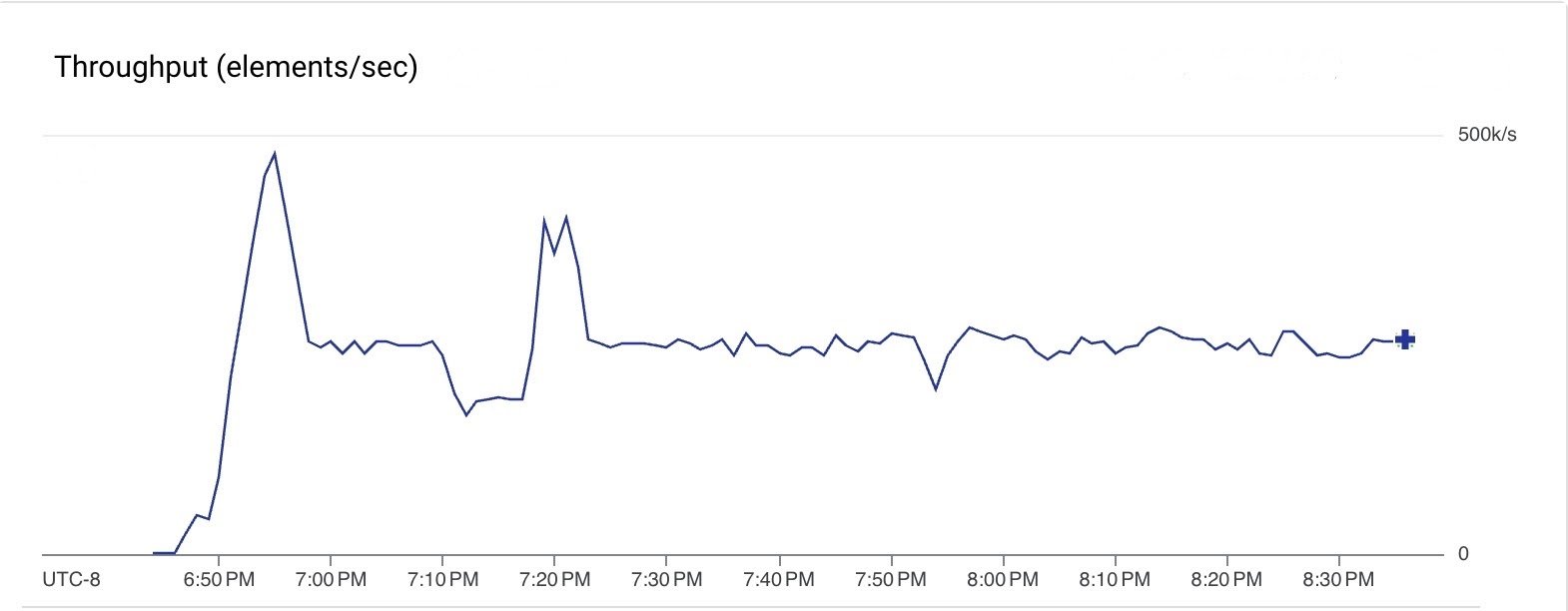
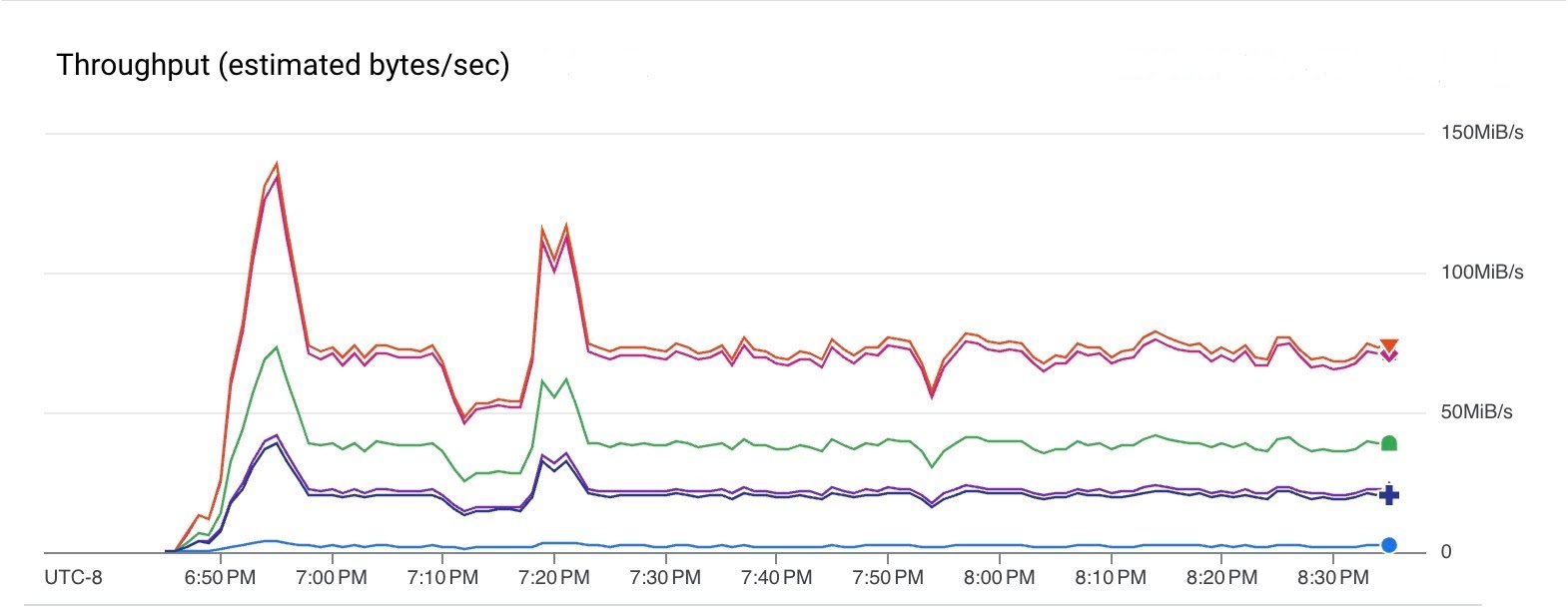
次のグラフは、パイプラインのさまざまなステップでのデータのスループットを示しています。要素サイズがステップによって変わるため、スループットが異なることに注意してください。このパイプラインは、Pub/Sub から 75 MiB/秒(赤線)のレートで読み取り、40 MiB/秒(緑線)のレートで Kafka に書き込みました。
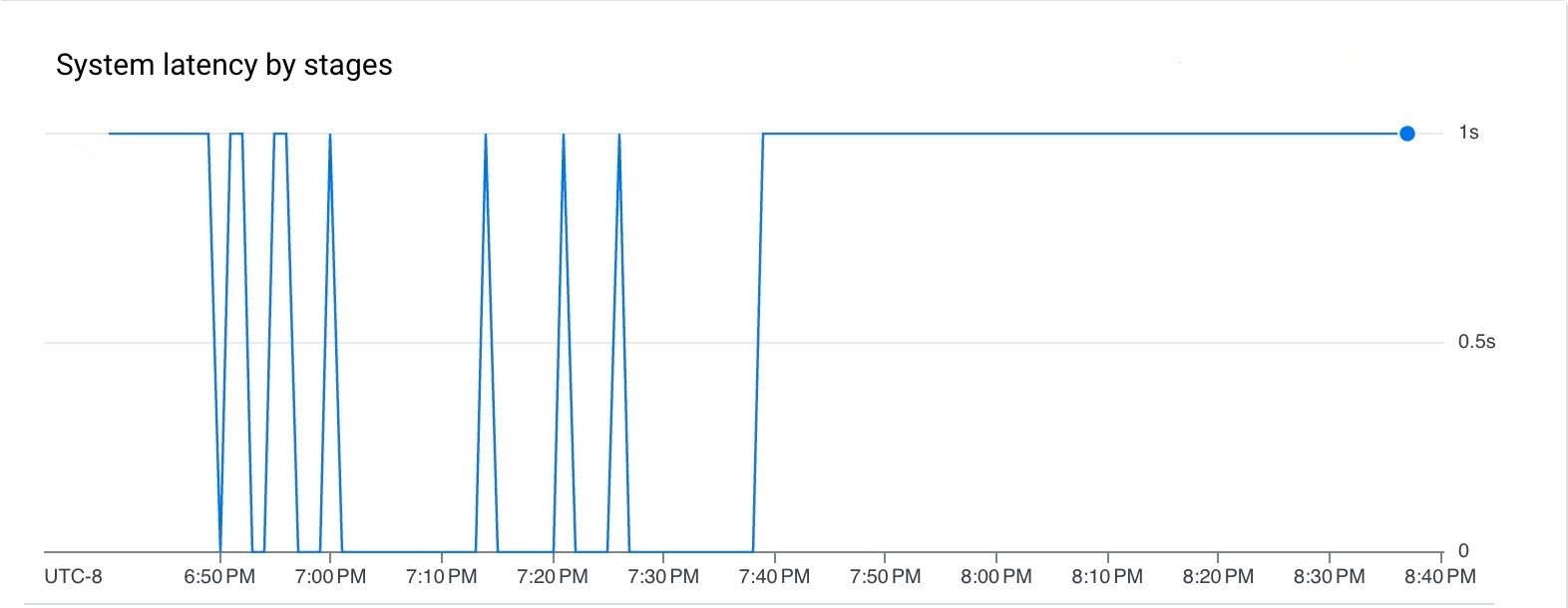
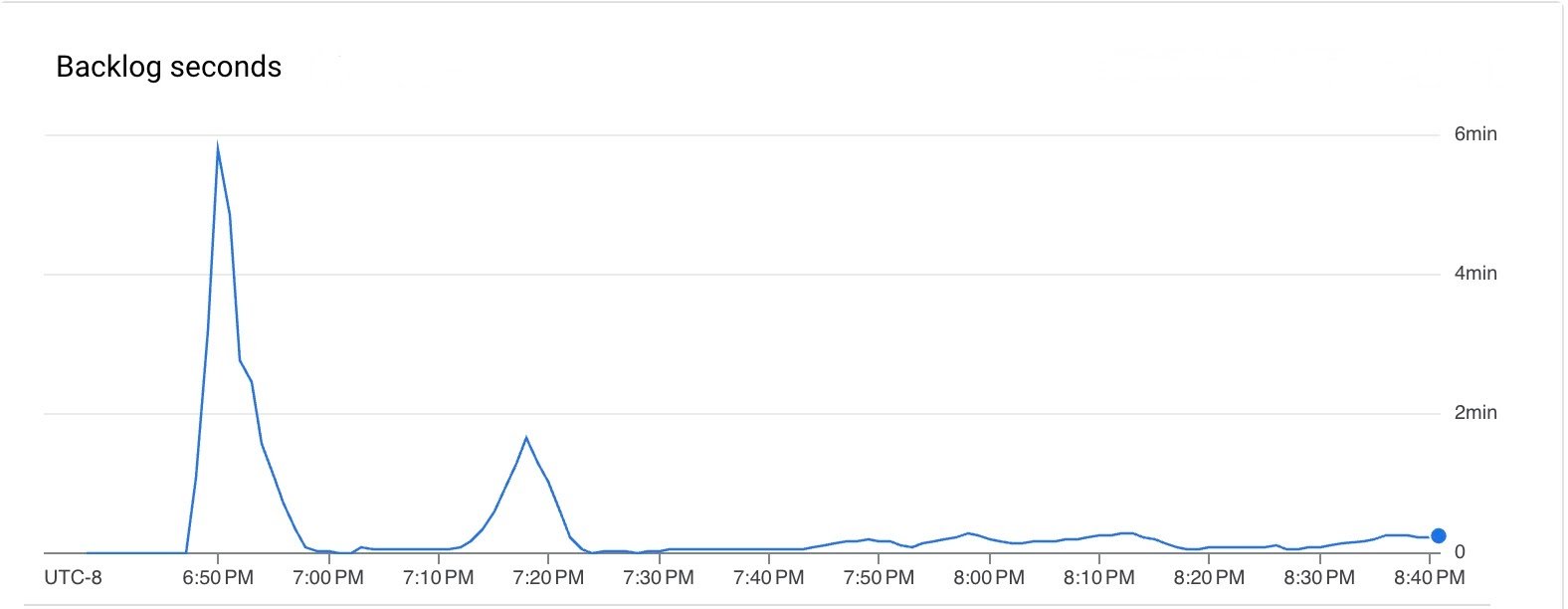
パイプラインの実行中、待ち時間とバックログはどちらも低くなりました。
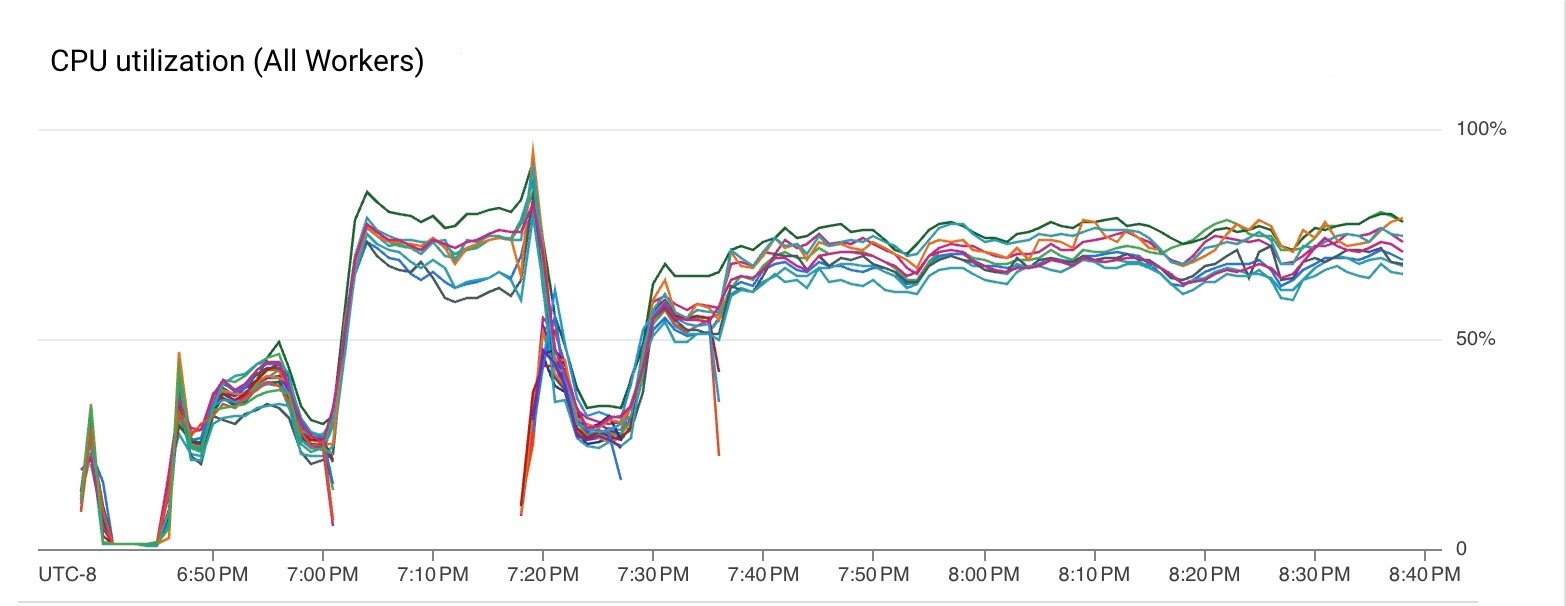
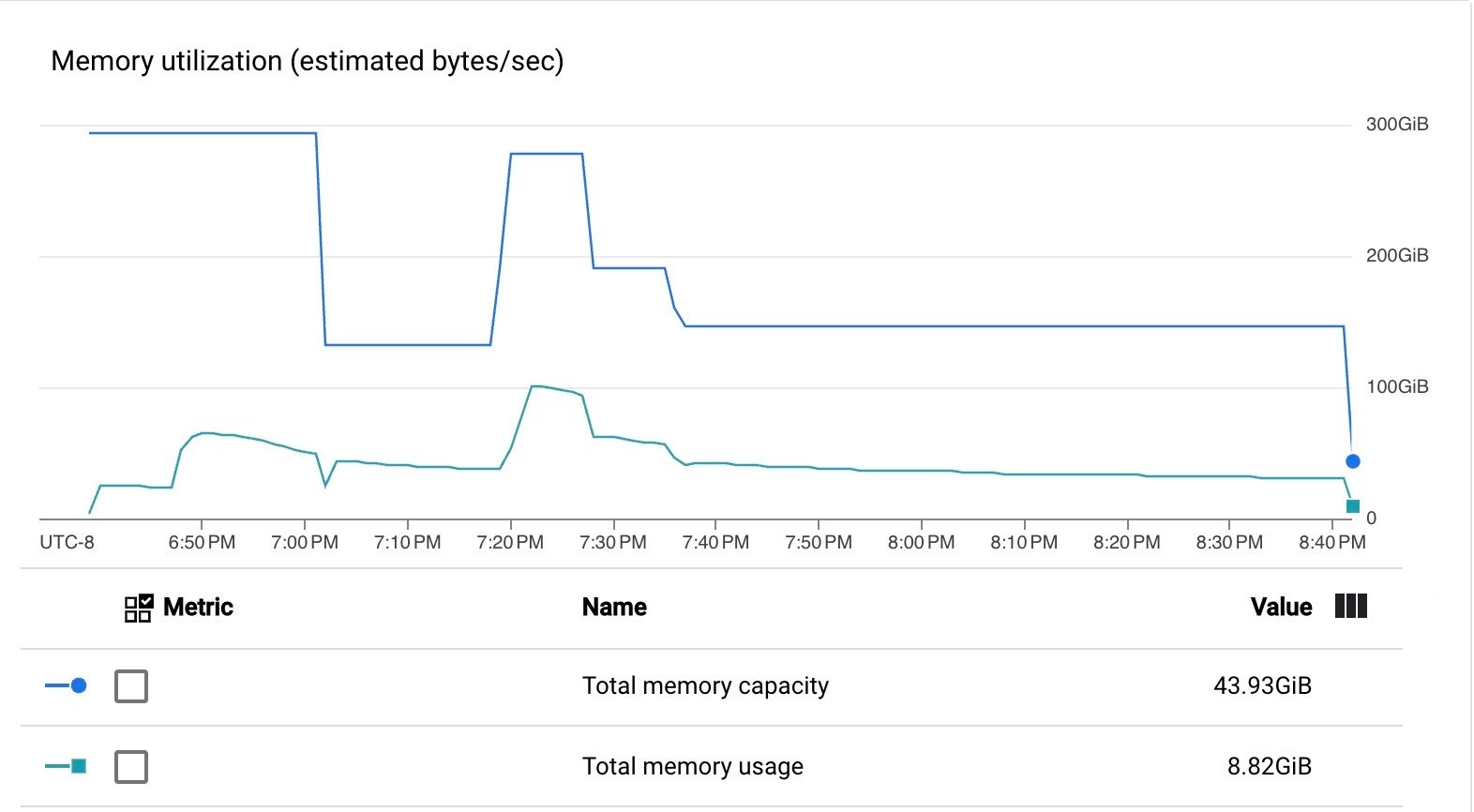
パイプラインは、VM の CPU とメモリを効率的に使いました。
以上の結果が示すように、Dataflow サービスがマネージド I/O Kafka シンクをアップグレードし、そこでパイプラインが効率的に実行されました。
マネージド I/O は簡単に使うことができます。パイプラインでサポートされるソースとシンクを使い、Dataflow Runner v2 でパイプラインを実行するだけです。古い Beam バージョンを使っていても、パイプラインを実行すれば、Dataflow がジョブの送信時とストリーミング アップデート時に置換を行い、ソースとシンクを最新の審査済みバージョンにしてくれます。

Google Colab is Coming to VS Code

スタンフォード大学の Marin 基盤モデル: JAX を使用して開発された初の完全オープンモデル

Firebase Studio でエージェント AI 開発を推進

Building with Gemini 3 in Jules

Announcing the Data Commons Gemini CLI extension

Building production AI on Google Cloud TPUs with JAX