

Gemma es una colección de modelos de código abiertos que son ligeros y de última generación, y están creados con la misma tecnología que impulsa nuestros modelos Gemini. Están disponibles en una variedad de tamaños y cualquier usuario puede adaptarlos y ejecutarlos en su propia infraestructura. Esta combinación de rendimiento y accesibilidad generó más de 250 millones de descargas y 85,000 variaciones de la comunidad publicadas para una amplia gama de tareas y dominios.
No se necesita hardware costoso para crear modelos personalizados altamente especializados. El tamaño compacto de Gemma 3 270M te permite ajustarlo rápidamente a nuevos casos de uso y luego implementarlo en el dispositivo, lo que te brinda flexibilidad en relación con el desarrollo de modelos y control total de una poderosa herramienta.
Para demostrar lo simple que es utilizarlo, en esta publicación se incluye un ejemplo de cómo entrenar tu propio modelo para traducir texto a emoji y probarlo en una aplicación web. Incluso puedes enseñarle los emojis específicos que usas en la vida real, con lo que tendrás un generador de emojis personal. Pruébalo en la demostración en vivo.
Te guiaremos a través del proceso integral de creación de un modelo específico para cada tarea en menos de una hora. Aprenderás a hacer lo siguiente:
Desde el primer momento, los modelos de lenguaje grandes (LLM) son generalistas. Si le pides a Gemma que traduzca texto a emoji, es posible que obtengas más de lo que pediste, como muletillas de conversaciones.
Indicación:
Traduce el siguiente texto en una combinación creativa de 3 a 5 emojis: “qué fiesta tan divertida”
Resultado del modelo (ejemplo):
¡Claro! Aquí está tu emoji: 🥳🎉🎈
Para nuestra aplicación, Gemma solo necesita mostrar emojis. Si bien puedes probar la ingeniería de indicaciones complejas, la forma más confiable de aplicar un formato de salida específico y enseñar al modelo nuevos conocimientos es ajustarlo con datos de ejemplo. Entonces, para enseñar al modelo a usar emojis específicos, deberías entrenarlo con un conjunto de datos que incluya ejemplos de texto y emoji.
Los modelos aprenden más cuantos más ejemplos proporciones, por lo que puedes lograr fácilmente que tu conjunto de datos sea más sólido si le pides a la IA que genere diferentes frases de texto para la misma salida de emoji. Para divertirnos, lo hicimos con emojis que asociamos con canciones pop y fandoms:
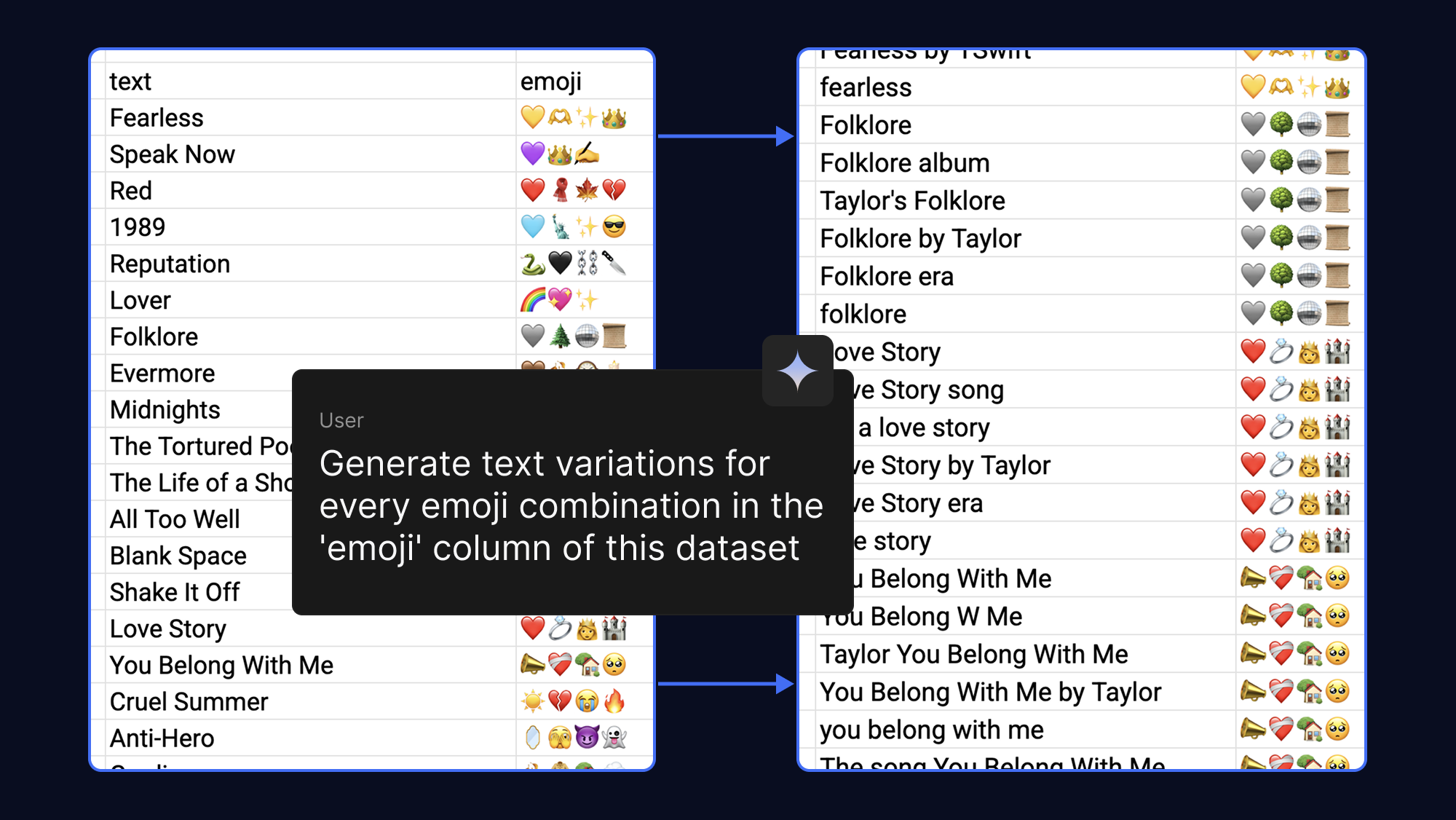
Para ajustar un modelo, se solía necesitar una enorme capacidad de VRAM. Sin embargo, con la adaptación cuantificada de bajo rango (QLoRA), una técnica de ajuste de parámetros eficientes (PEFT), solo actualizamos un pequeño número de pesos. De esta manera, se reducen en gran medida los requisitos de memoria, lo que te permite ajustar Gemma 3 270M en minutos si usas la aceleración de GPU T4 sin costo en Google Colab.
Comienza con un conjunto de datos de ejemplo o completa la plantilla con tus propios emojis. Luego, puedes ejecutar el notebook de ajuste para cargar el conjunto de datos, entrenar el modelo y probar el rendimiento del nuevo modelo en comparación con el original.
Ahora que tienes un modelo personalizado, ¿qué puedes hacer con él? Dado que, por lo general, usamos emojis en dispositivos móviles o computadoras, tiene sentido implementar el modelo en una aplicación integrada en el dispositivo.
Aunque es pequeño, el modelo original tiene más de 1 GB. Para garantizar una experiencia de usuario de carga rápida, debemos hacerlo aún más pequeño. Podemos lograrlo si usamos la cuantificación, un proceso que permite reducir la precisión de los pesos del modelo (p. ej., de enteros de 16 bits a enteros de 4 bits). De esta manera, se reduce en gran medida el tamaño del archivo, con un impacto mínimo en el rendimiento de muchas tareas.
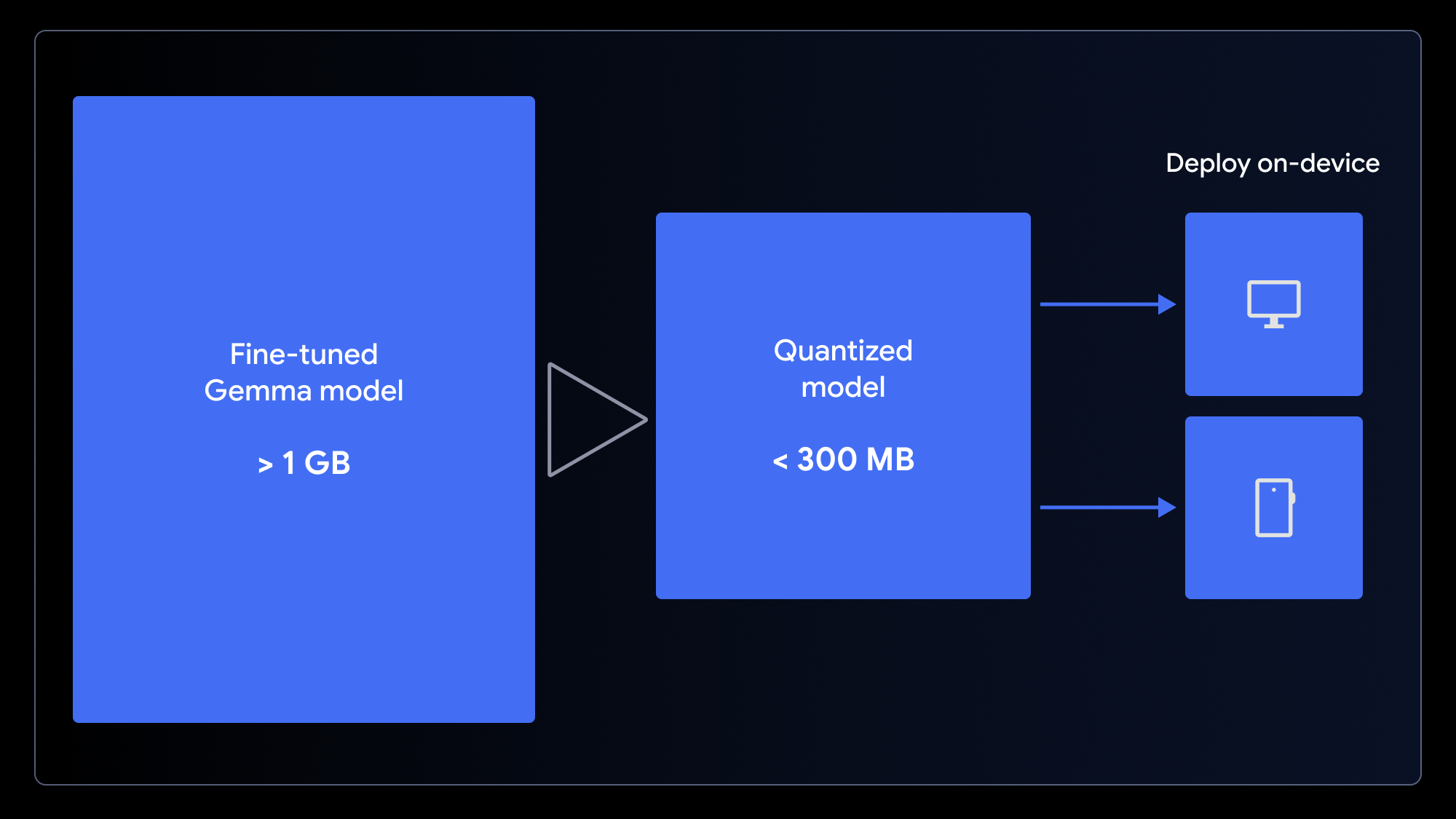
Si quieres preparar el modelo para una aplicación web, cuantifícalo y conviértelo en un solo paso utilizando el notebook de conversión LiteRT para usar con MediaPipe o el notebook de conversión ONNX para usar con Transformers.js. Estos marcos de trabajo permiten ejecutar LLM del cliente en el navegador aprovechando WebGPU, una API web moderna que brinda a las aplicaciones acceso al hardware de un dispositivo local para los cálculos, lo que elimina la necesidad de configuraciones complejas del servidor y los costos de inferencia por llamada.
Ahora puedes ejecutar tu modelo personalizado directamente en el navegador. Descarga nuestra aplicación web de ejemplo y cambia una línea de código para conectar tu nuevo modelo.
Tanto con MediaPipe como con Transformers.js, este proceso es sencillo. El siguiente es un ejemplo de la tarea de inferencia que se ejecuta dentro del worker de MediaPipe:
// Initialize the MediaPipe Task
const genai = await FilesetResolver.forGenAiTasks('https://cdn.jsdelivr.net/npm/@mediapipe/tasks-genai@latest/wasm');
llmInference = await LlmInference.createFromOptions(genai, {
baseOptions: { modelAssetPath: 'path/to/yourmodel.task' }
});
// Format the prompt and generate a response
const prompt = `Translate this text to emoji: what a fun party!`;
const response = await llmInference.generateResponse(prompt);Una vez que el modelo se almacena en caché en el dispositivo del usuario, las solicitudes posteriores se ejecutan localmente con baja latencia, los datos del usuario permanecen completamente privados y la aplicación funciona incluso sin conexión.
¿Te encanta tu aplicación? Compártela en Hugging Face Spaces (al igual que la demostración).
No es necesario tener una gran experiencia en IA ni dedicarse a la ciencia de datos para crear un modelo de IA especializado. Puedes mejorar el rendimiento del modelo Gemma utilizando conjuntos de datos relativamente pequeños (y lleva minutos, no horas).
Esperamos que te inspires y crees tus propias variaciones del modelo. Si usas estas técnicas, puedes crear potentes aplicaciones de IA que no solo se adapten a tus necesidades, sino que también ofrezcan una experiencia de usuario superior: rápida, privada y accesible para cualquier persona y en cualquier lugar.
El código fuente completo y los recursos para este proyecto están disponibles y puedes usarlos como ayuda para empezar a experimentar:

Announcing the Agent Development Kit for Go: Build Powerful AI Agents with Your Favorite Languages

GenAI en el dispositivo para Chrome, Chromebook Plus y Pixel Watch con LiteRT-LM

Announcing User Simulation in ADK Evaluation

Google AI Edge Gallery: Ahora con audio y en Google Play