

O Gemma é uma coleção de modelos abertos leves e de última geração, criados com a mesma tecnologia que habilita nossos modelos Gemini. Ele está disponível em uma variedade de tamanhos que qualquer pessoa pode adaptar e executar na própria infraestrutura. Essa combinação de desempenho e acessibilidade já levou a mais de 250 milhões de downloads e 85.000 variações da comunidade publicadas para uma ampla gama de tarefas e domínios.
Você não precisa de um hardware caro para criar modelos personalizados e altamente especializados. O tamanho compacto do Gemma 3 270M permite ajustá-lo rapidamente para novos casos de uso e, em seguida, implantá-lo no dispositivo, oferecendo flexibilidade no desenvolvimento de modelos e controle total de uma ferramenta poderosa.
Para mostrar como isso é simples, esta postagem apresenta um exemplo de como treinar seu próprio modelo para traduzir texto em emoji e testá-lo em um app da Web. Você pode até ensinar a ele os emojis específicos que usa na vida real para ter um gerador de emojis pessoal. Experimente na demonstração ao vivo.
Vamos orientar você pelo processo completo de criação de um modelo específico de tarefa em menos de uma hora. Você verá como:
Em sua forma original, os LLMs são generalistas. Se você pedir ao Gemma para traduzir um texto em emoji, poderá receber mais do que pediu, como um preenchimento de conversa.
Prompt:
Traduza o seguinte texto em uma combinação criativa de 3 a 5 emojis: "que festa divertida"
Saída do modelo (exemplo):
Claro! Aqui estão os seus emojis: 🥳🎉🎈
Para nosso app, o Gemma precisa gerar uma saída apenas com emojis. Embora você possa tentar uma engenharia de prompt complexa, a maneira mais confiável de aplicar um formato de saída específico e ensinar ao modelo novos conhecimentos é ajustá-lo com dados de exemplo. Portanto, para ensinar o modelo a usar emojis específicos, você o treinaria em um conjunto de dados contendo exemplos de texto e emojis.
Os modelos aprendem melhor quando você fornece mais exemplos, e que você pode facilmente tornar seu conjunto de dados mais robusto elaborando prompts para que a IA gere diferentes frases de texto para a mesma saída de emojis. Por diversão, fizemos isso com emojis que associamos a músicas pop e fandoms:
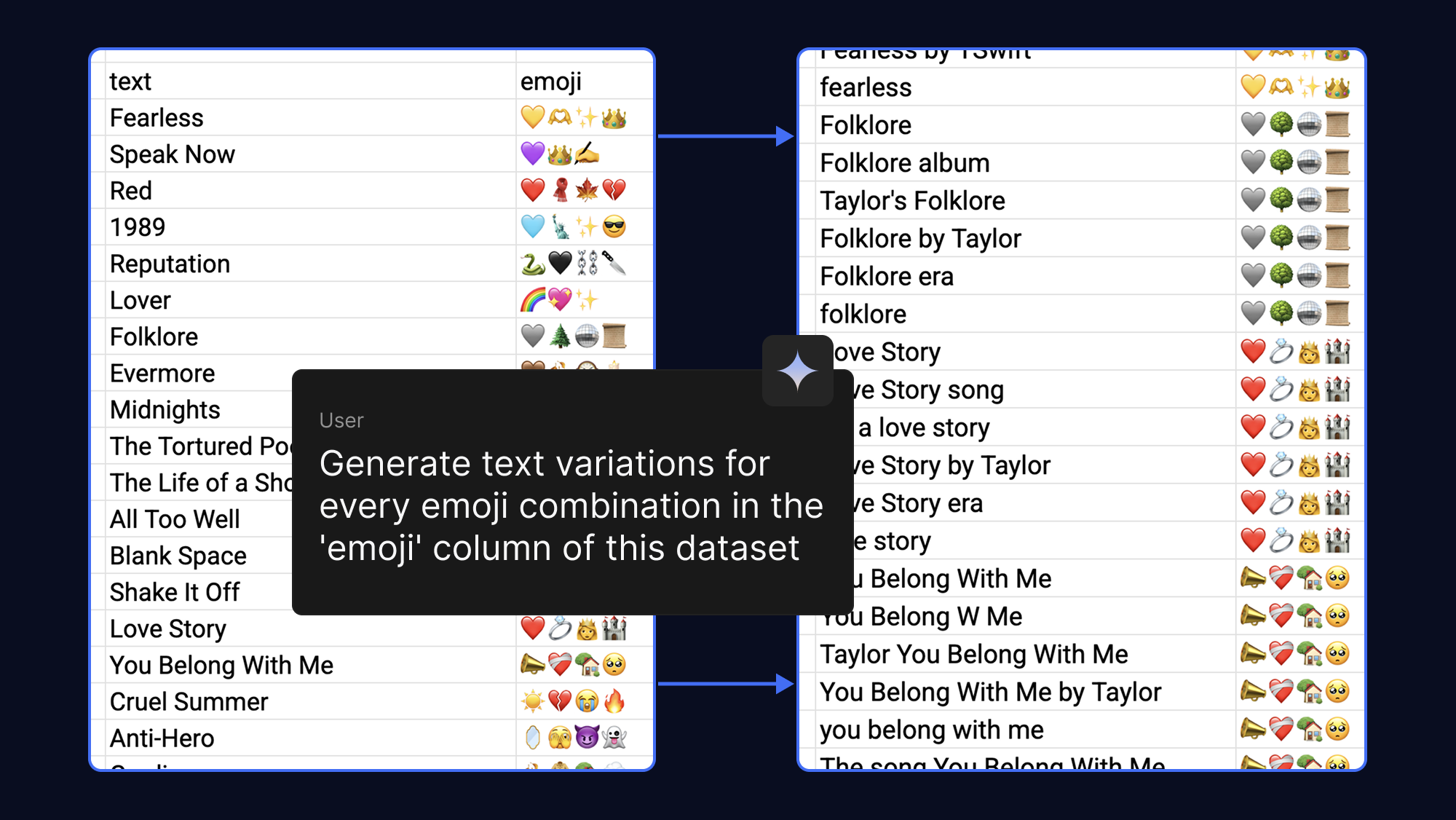
O ajuste de um modelo costumava exigir enormes quantidades de VRAM. No entanto, com a QLoRA (Quantized Low-Rank Adaptation), uma técnica de ajuste PEFT (Parameter-Efficient Fine-Tuning), atualizamos apenas um pequeno número de pesos. Isso reduz drasticamente os requisitos de memória, permitindo ajustar o Gemma 3 270M em questão de minutos com o uso da aceleração de GPU T4 sem custos financeiros no Google Colab.
Comece com um conjunto de dados de exemplo ou preencha o modelo com seus próprios emojis. Em seguida, você pode executar o notebook de ajuste para carregar o conjunto de dados, treinar o modelo e testar o desempenho do novo modelo em relação ao original.
Agora que você tem um modelo personalizado, o que pode fazer com ele? Como geralmente usamos emojis em dispositivos móveis ou computadores, faz sentido implantar o modelo em um app no dispositivo.
O modelo original, embora pequeno, ainda tem mais de 1 GB. Para garantir uma experiência de usuário com carregamento rápido, precisamos reduzi-lo. Podemos fazer isso usando a quantização, um processo que reduz a precisão dos pesos do modelo (por exemplo, de inteiros de 16 bits para 4 bits). Isso reduz significativamente o tamanho do arquivo com impacto mínimo no desempenho para muitas tarefas.
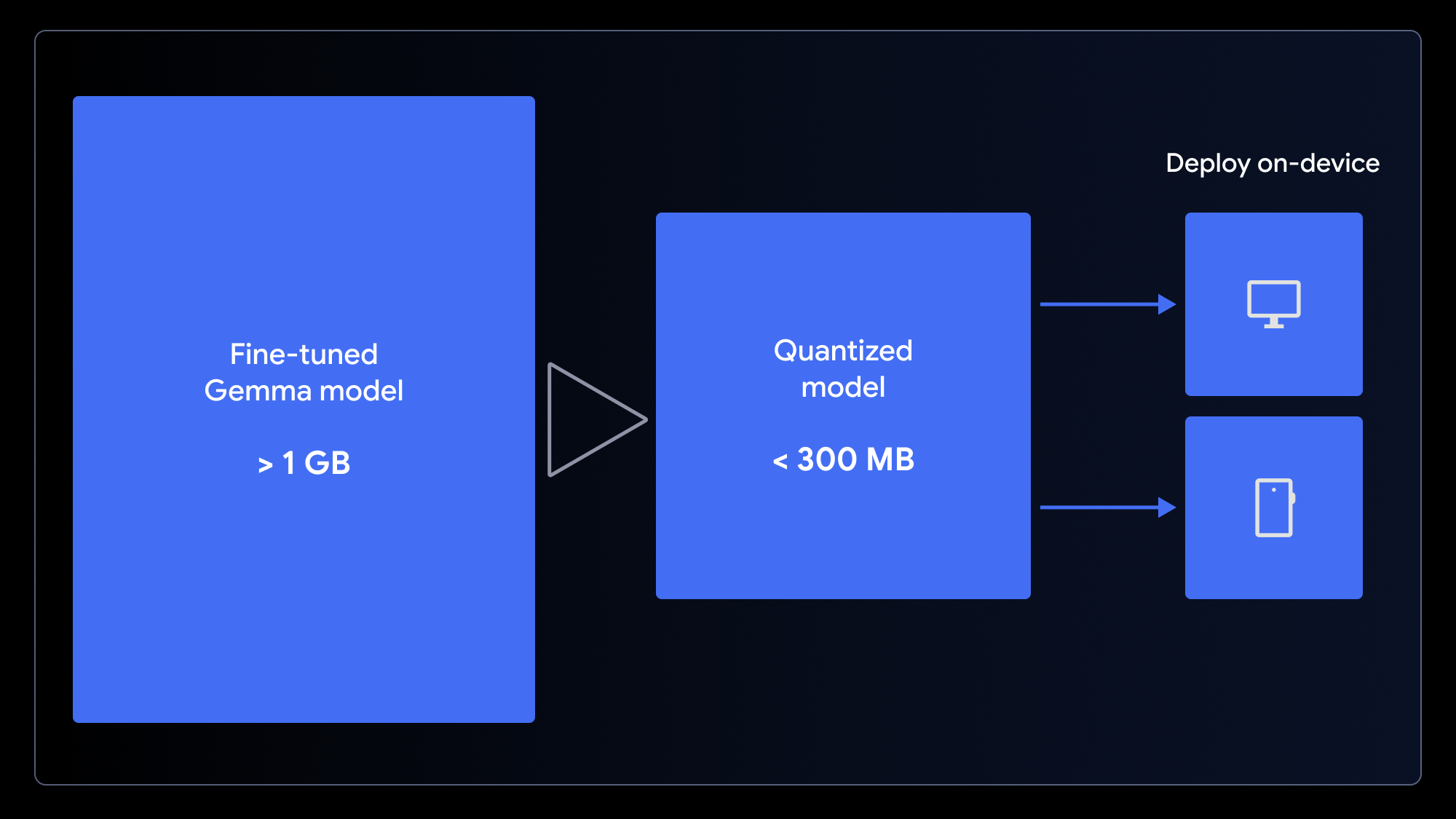
Para preparar seu modelo para um app da Web, faça a quantização e converta-o em uma única etapa usando o notebook de conversão para LiteRT para uso com o MediaPipe ou o notebook de conversão para ONNX para uso com o Transformers.js. Esses frameworks permitem a execução de LLMs no lado do cliente no navegador ao utilizarem a WebGPU, uma API da Web moderna que fornece aos apps acesso ao hardware de um dispositivo local para computação, eliminando a necessidade de configurações complexas do servidor e os custos de inferência por chamada.
Agora você pode executar o modelo personalizado diretamente no navegador! Faça o download de nosso app da Web de exemplo e altere uma linha de código para conectar seu novo modelo.
Tanto o MediaPipe quanto o Transformers.js tornam isso muito direto. Veja a seguir um exemplo da tarefa de inferência em execução dentro do worker MediaPipe:
// Initialize the MediaPipe Task
const genai = await FilesetResolver.forGenAiTasks('https://cdn.jsdelivr.net/npm/@mediapipe/tasks-genai@latest/wasm');
llmInference = await LlmInference.createFromOptions(genai, {
baseOptions: { modelAssetPath: 'path/to/yourmodel.task' }
});
// Format the prompt and generate a response
const prompt = `Translate this text to emoji: what a fun party!`;
const response = await llmInference.generateResponse(prompt);Depois que o modelo é armazenado em cache no dispositivo do usuário, as solicitações subsequentes são executadas localmente com baixa latência, os dados do usuário permanecem completamente privados e o app funciona mesmo que esteja off-line.
Gostou do seu app? Compartilhe-o fazendo upload para o Hugging Face Spaces (exatamente como na demonstração).
Você não precisa ser especialista em IA nem cientista de dados para criar um modelo de IA especializado. Você pode melhorar o desempenho do modelo Gemma usando conjuntos de dados relativamente pequenos em questão de minutos, e não de horas.
Esperamos que você se inspire para criar suas próprias variações do modelo. Ao usar essas técnicas, você pode criar aplicativos de IA poderosos que não são apenas personalizados para suas necessidades, mas também oferecem uma experiência de usuário superior: rápida, privada e acessível a qualquer pessoa, em qualquer lugar.
O código-fonte completo e os recursos deste projeto estão disponíveis para ajudar você a começar:

Google AI Edge Gallery: agora com áudio e no Google Play

Announcing the Agent Development Kit for Go: Build Powerful AI Agents with Your Favorite Languages

Announcing User Simulation in ADK Evaluation

IA generativa no dispositivo no Chrome, Chromebook Plus e Pixel Watch com o LiteRT-LM