

Gemma は、Google の Gemini モデルと同じテクノロジーで構築された、軽量で最先端のオープンモデルのファミリーです。幅広いサイズが用意されており、誰でも自身のインフラストラクチャに合わせて実行できます。このようなパフォーマンスと利用しやすさの両立により、ダウンロード数は 2 億 5,000 万回を突破し、幅広いタスクとドメイン向けに開発者コミュニティで 85,000 種類以上のバリエーションが公開されました。
高価なハードウェアがなくても、高度に専門化されたカスタムモデルを作成できます。Gemma 3 270M はサイズがコンパクトなので、新しいユースケースに合わせて素早くファインチューニングして、デバイス上にデプロイできます。これにより、モデル開発を柔軟に行い、強力なツールを完全に制御することが可能になります。
Gemma 3 270M を使ったモデル開発の手軽さを示すために、この投稿では、テキストを絵文字に翻訳する独自のモデルをトレーニングして、ウェブアプリでテストする例をご説明します。ご自身が実生活で使用する特定の絵文字を学習させ、個人用の絵文字生成ツールを作成することもできます。ライブデモでお試しください。
タスク特化型モデルを 1 時間以内に作成するエンドツーエンドのプロセスをご説明します。以下の手順を解説します。
最初の状態から、LLM は何でも屋です。Gemma にテキストを絵文字に翻訳するようリクエストすると、会話のつなぎの言葉など、要求した以上の回答が返ってくる可能性があります。
プロンプト:
次のテキストを 3~5 つの絵文字のクリエイティブな組み合わせに変換して。「楽しいパーティー」
モデルの出力(例):
わかりました!こちらの絵文字をどうぞ。 🥳🎉🎈
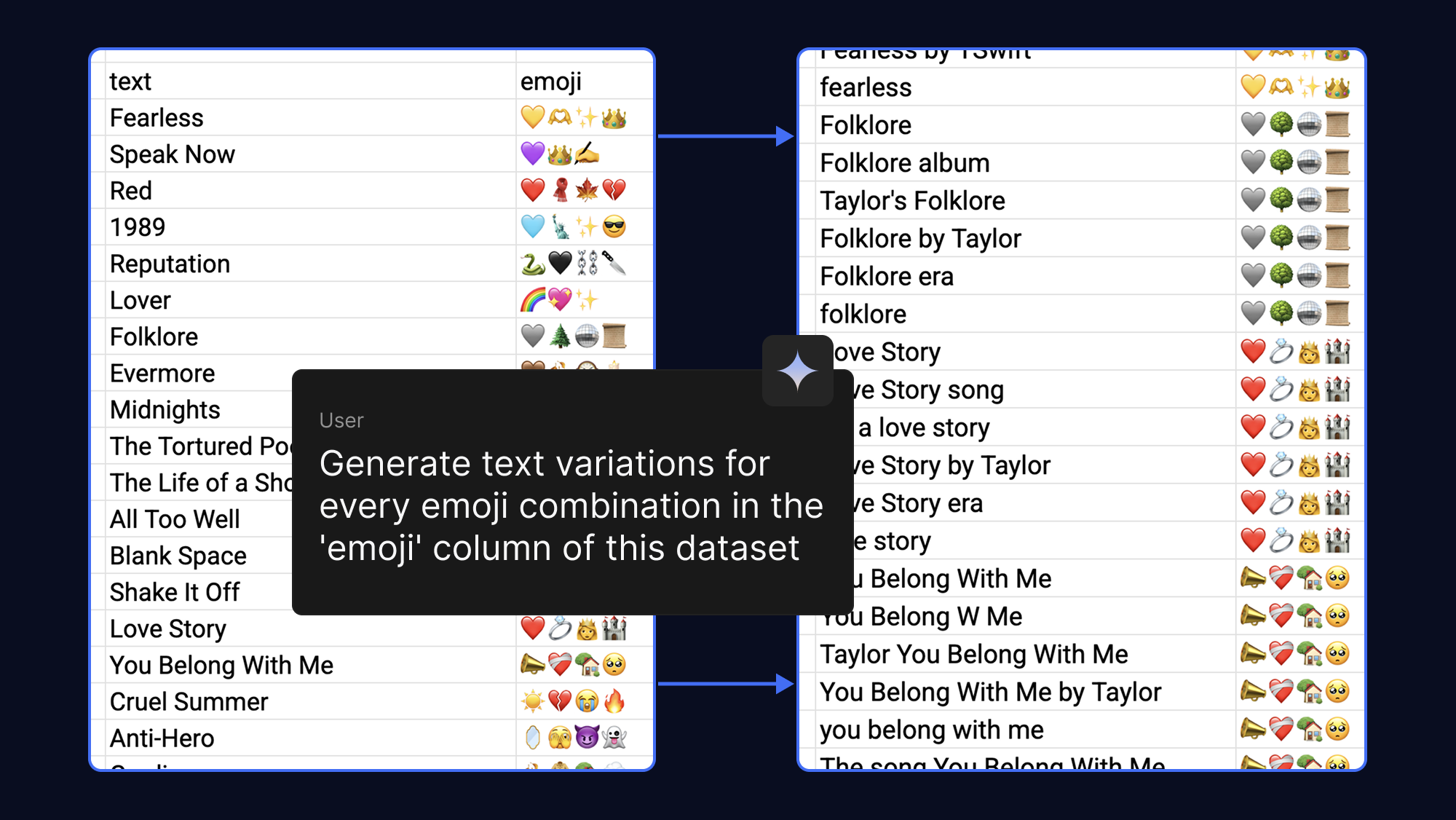
今回作るアプリでは、Gemma は絵文字だけを出力する必要があります。複雑なプロンプト エンジニアリングを試すことはできますが、特定の出力フォーマットを適用し、モデルに新しい知識を教えるための最も信頼できる方法は、サンプルデータを使ってファインチューニングすることです。したがって、特定の絵文字を使用するようにモデルに教えるには、テキストと絵文字の例を含むデータセットでトレーニングします。
モデルは、より多くの例を提供するほどより深く学習できるため、1 つの絵文字の出力に対して異なるテキスト フレーズを生成するよう AI に指示することで、簡単にデータセットを堅牢にすることができます。遊び心を込めて、以下のようにポップソングやファンダムから連想される絵文字を使ってこれを行ってみました。
これまで、モデルをファインチューニングするには大容量の VRAM が必要でした。しかし、パラメータ効率の高いファインチューニング(PEFT)技術である量子化低ランク適応(QLoRA)では、少数の重みのみを更新します。これにより、メモリ要件が大幅に削減され、Google Colab で無料の T4 GPU による高速化を使用している場合、Gemma 3 270M を数分でファインチューニングできます。
サンプル データセットを使用するか、テンプレートに使用したい絵文字を入力します。その後、ファインチューニング ノートブックを実行してデータセットを読み込み、モデルをトレーニングし、元のモデルと比較して新しいモデルのパフォーマンスをテストできます。
カスタムモデルができたので、これを使って何かしてみましょう。通常、絵文字はモバイル デバイスやパソコンで使用するため、オンデバイス アプリにモデルをデプロイするのがよさそうです。
元のモデルのサイズは小さいとはいえ 1 GB を超えています。高速で読み込めるユーザー エクスペリエンスを確保するために、サイズを小さくする必要があります。そのために使用できるのが、モデルの重みの精度を(たとえば、16 ビットから 4 ビットの整数へというように)落とすプロセスである量子化です。これにより、多くのタスクのパフォーマンスへの影響を最小限に抑えながら、ファイルサイズを大幅に縮小できます。
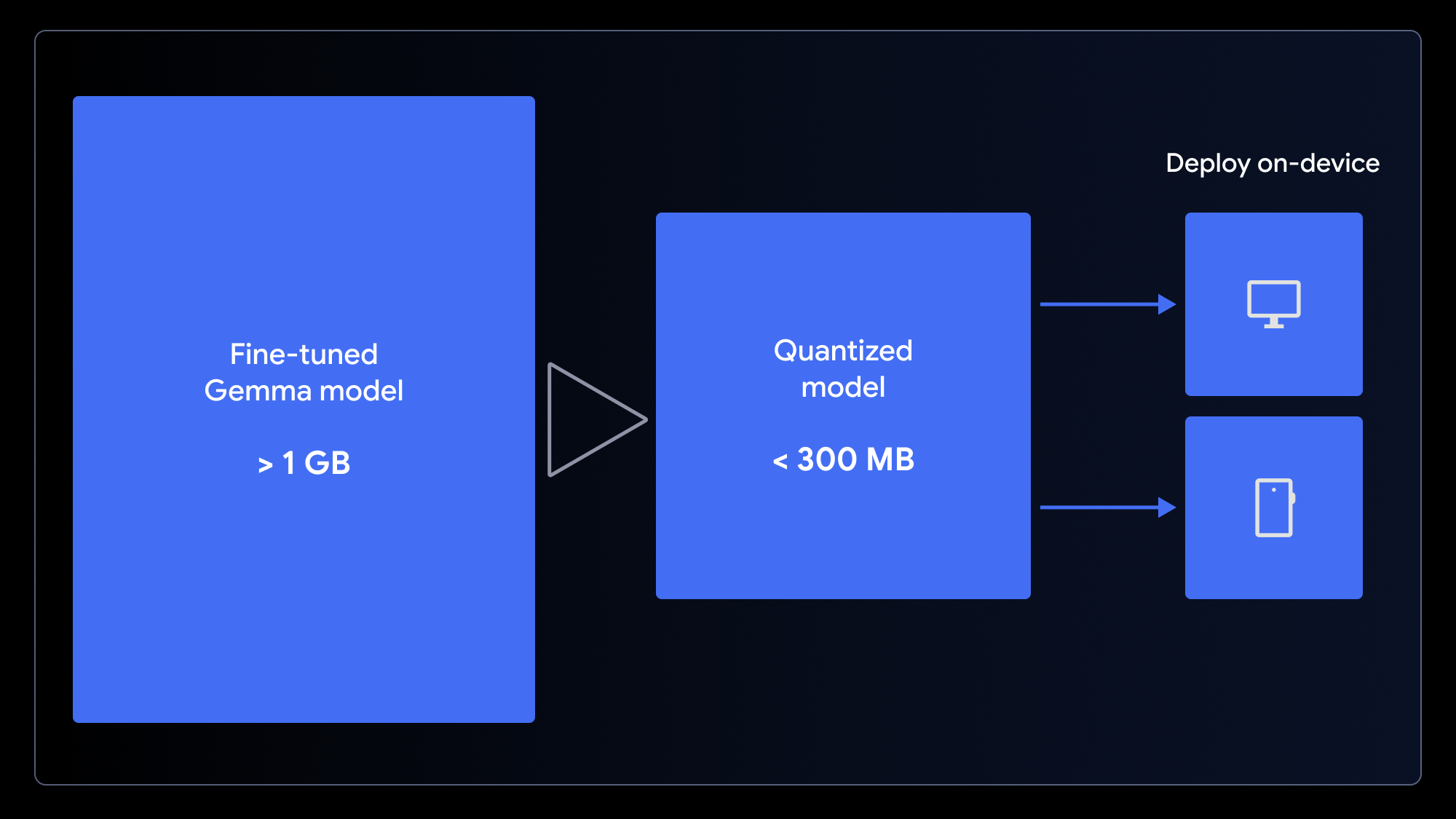
ウェブアプリ向けにモデルを準備するには、MediaPipe で使用する LiteRT 変換ノートブックまたは Transformers.js で使用する ONNX 変換ノートブックを使用して、1 ステップで量子化して変換します。これらのフレームワークにより、WebGPU を活用してブラウザのクライアントサイドで LLM を実行することが可能になります。WebGPU は、アプリケーションが計算のためにローカル デバイスのハードウェアにアクセスできるようにする最新のウェブ API であり、これにより複雑なサーバー設定やリクエストごとの推論コストを不要にできます。
カスタマイズしたモデルをブラウザで直接実行できるようになりました。サンプル ウェブアプリをダウンロードし、コードを 1 行だけ変更して、新しいモデルをプラグインしましょう。
この作業は、MediaPipe でも Transformers.js でも簡単に行えます。MediaPipe ワーカー内で実行されている推論タスクの例を次に示します。
// Initialize the MediaPipe Task
const genai = await FilesetResolver.forGenAiTasks('https://cdn.jsdelivr.net/npm/@mediapipe/tasks-genai@latest/wasm');
llmInference = await LlmInference.createFromOptions(genai, {
baseOptions: { modelAssetPath: 'path/to/yourmodel.task' }
});
// Format the prompt and generate a response
const prompt = `Translate this text to emoji: what a fun party!`;
const response = await llmInference.generateResponse(prompt);モデルがユーザーのデバイスにキャッシュされると、その後のリクエストはローカルで低遅延で実行され、ユーザーデータは完全にプライベートに保たれ、アプリはオフラインでも機能するようになります。
アプリが気に入った場合は、(前述のデモのように) Hugging Face Spaces にアップロードして共有しましょう。
AI の専門家やデータ サイエンティストでなくても、タスク特化型の AI モデルを作成できます。比較的小さなデータセットでも Gemma モデルのパフォーマンスを向上させることが可能です。しかも、数時間ではなく数分で行えます。
皆さんが独自のモデルのバリエーションを作成してくれることを願っています。ご紹介した手法を使用することで、ニーズに合わせてカスタマイズされているだけでなく、誰でもどこでもアクセスできる高速でプライベートな優れたユーザー エクスペリエンスを提供する強力な AI アプリケーションを構築できます。
このプロジェクトの完全なソースコードとリソースを使用して、作業を開始できます。

Google AI Edge Gallery: 音声サポートが追加され Google Play で利用可能に

Announcing User Simulation in ADK Evaluation

LiteRT-LM を活用した Chrome、Chromebook Plus、Google Pixel Watch でのオンデバイス生成 AI

Announcing the Agent Development Kit for Go: Build Powerful AI Agents with Your Favorite Languages