

Gemma adalah koleksi model terbuka yang ringan dan termutakhir yang dibuat dari teknologi yang sama dengan yang mendukung model Gemini kami. Tersedia dalam berbagai ukuran, siapa pun bisa mengadaptasi dan menjalankannya di infrastruktur mereka sendiri. Kombinasi performa dan aksesibilitas ini telah menghasilkan lebih dari 250 juta download dan 85.000 variasi komunitas yang dipublikasikan untuk berbagai macam tugas dan domain.
Anda tidak memerlukan hardware yang mahal untuk membuat model khusus yang sangat terspesialisasi. Ukuran ringkas Gemma 3 270M memungkinkan Anda dengan cepat menyesuaikannya untuk kasus penggunaan baru kemudian menerapkannya di perangkat, sehingga Anda memiliki fleksibilitas dalam pengembangan model dan kontrol penuh atas alat yang mumpuni.
Untuk menunjukkan betapa sederhananya hal ini, postingan ini akan membahas contoh melatih model Anda sendiri untuk menerjemahkan teks ke emoji dan mengujinya di aplikasi web. Anda bahkan bisa mengajarinya emoji khusus yang Anda gunakan dalam kehidupan nyata, sehingga menghasilkan generator emoji personal. Cobalah di demo langsung.
Kami akan memandu Anda melalui proses menyeluruh dalam membuat model khusus tugas dalam waktu kurang dari satu jam. Anda akan mempelajari cara:
Pada dasarnya, LLM adalah model serba guna. Jika Anda meminta Gemma untuk menerjemahkan teks ke emoji, Anda mungkin akan mendapatkan lebih dari yang Anda minta, seperti pengisi percakapan.
Prompt:
Terjemahkan teks berikut ini ke dalam kombinasi kreatif 3-5 emoji: “pesta yang menyenangkan”
Output model (contoh):
Tentu! Ini emoji Anda: 🥳🎉🎈
Untuk aplikasi kami, Gemma hanya perlu menghasilkan output emoji. Meskipun Anda bisa mencoba prompt engineering yang kompleks, cara yang paling andal untuk menerapkan format output tertentu dan mengajarkan pengetahuan baru kepada model adalah dengan menyesuaikannya pada data contoh. Jadi, untuk mengajari model menggunakan emoji tertentu, Anda perlu melatihnya pada set data yang berisi contoh teks dan emoji.
Model akan belajar lebih baik dengan lebih banyak contoh yang Anda berikan, sehingga Anda bisa dengan mudah membuat set data Anda lebih kuat dengan meminta AI untuk menghasilkan frasa teks yang berbeda untuk output emoji yang sama. Untuk seru-seruan, kami melakukan hal ini dengan emoji yang kami asosiasikan dengan lagu-lagu pop dan fandom:
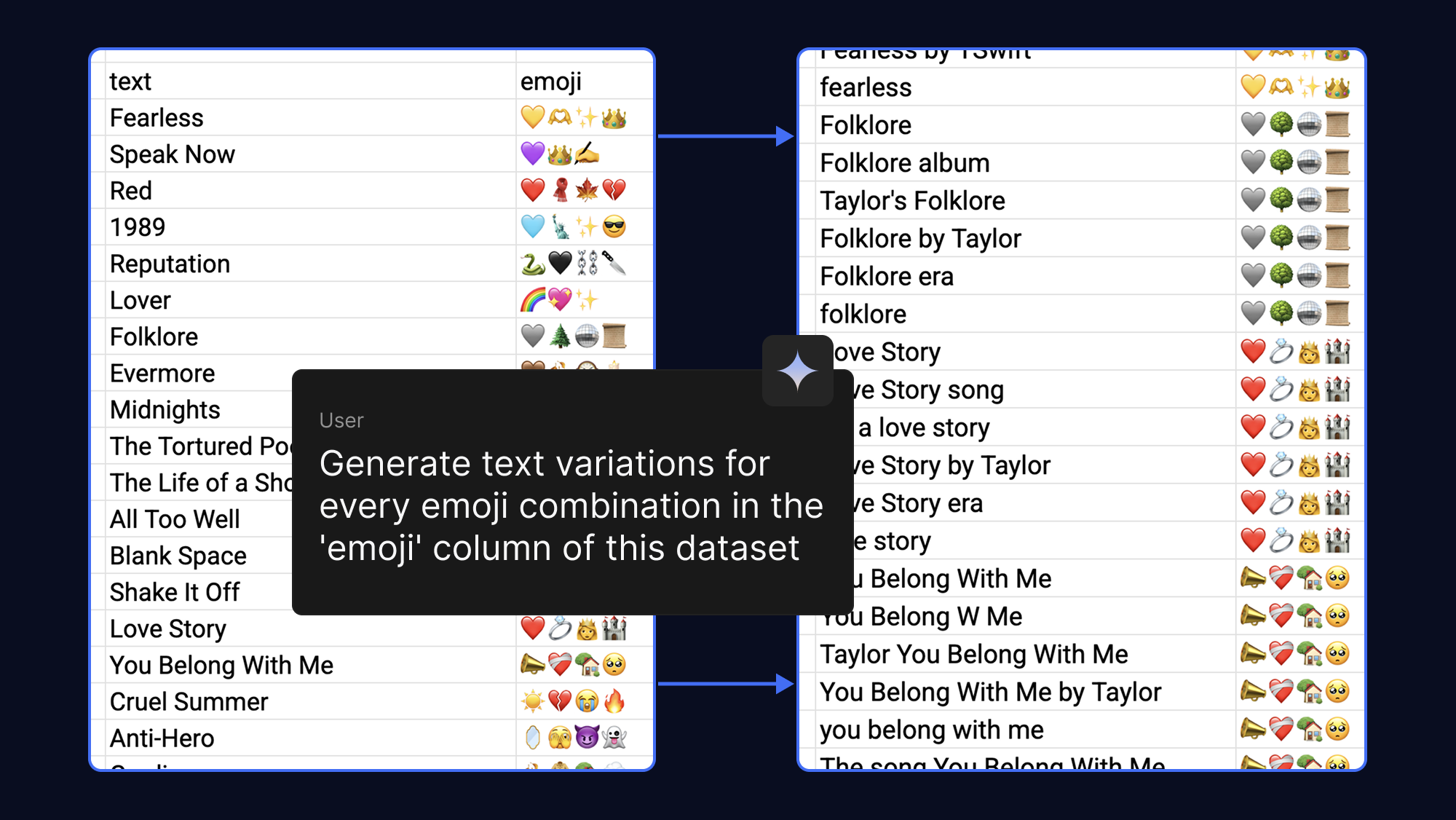
Menyesuaikan model yang digunakan biasanya membutuhkan VRAM yang sangat besar. Namun, dengan Quantized Low-Rank Adaptation (QLoRA), teknik Parameter-Efficient Fine-Tuning (PEFT), kami hanya memperbarui sejumlah kecil bobot. Hal ini secara drastis mengurangi kebutuhan memori, sehingga Anda dapat menyesuaikan Gemma 3 270M dalam hitungan menit saat menggunakan akselerasi GPU T4 tanpa biaya di Google Colab.
Mulailah dengan set data contoh atau mengisi template dengan emoji Anda sendiri. Anda kemudian bisa menjalankan penyesuaian notebook untuk memuat set data, melatih model, dan menguji performa model baru Anda terhadap model asli.
Kini, setelah Anda memiliki model khusus, apa yang bisa Anda lakukan dengannya? Karena kita biasanya menggunakan emoji di perangkat seluler atau komputer, sangatlah masuk akal menerapkan model Anda dalam aplikasi di perangkat.
Model aslinya, meskipun kecil, tetapi ukurannya masih lebih dari 1GB. Untuk memastikan pengalaman pengguna yang cepat saat dimuat, kita perlu mengecilkannya. Kita bisa melakukannya dengan menggunakan kuantisasi, sebuah proses yang mengurangi presisi bobot model (mis., dari integer 16-bit menjadi 4-bit). Hal ini secara signifikan mengecilkan ukuran file dengan dampak minimal pada performa untuk banyak tugas.
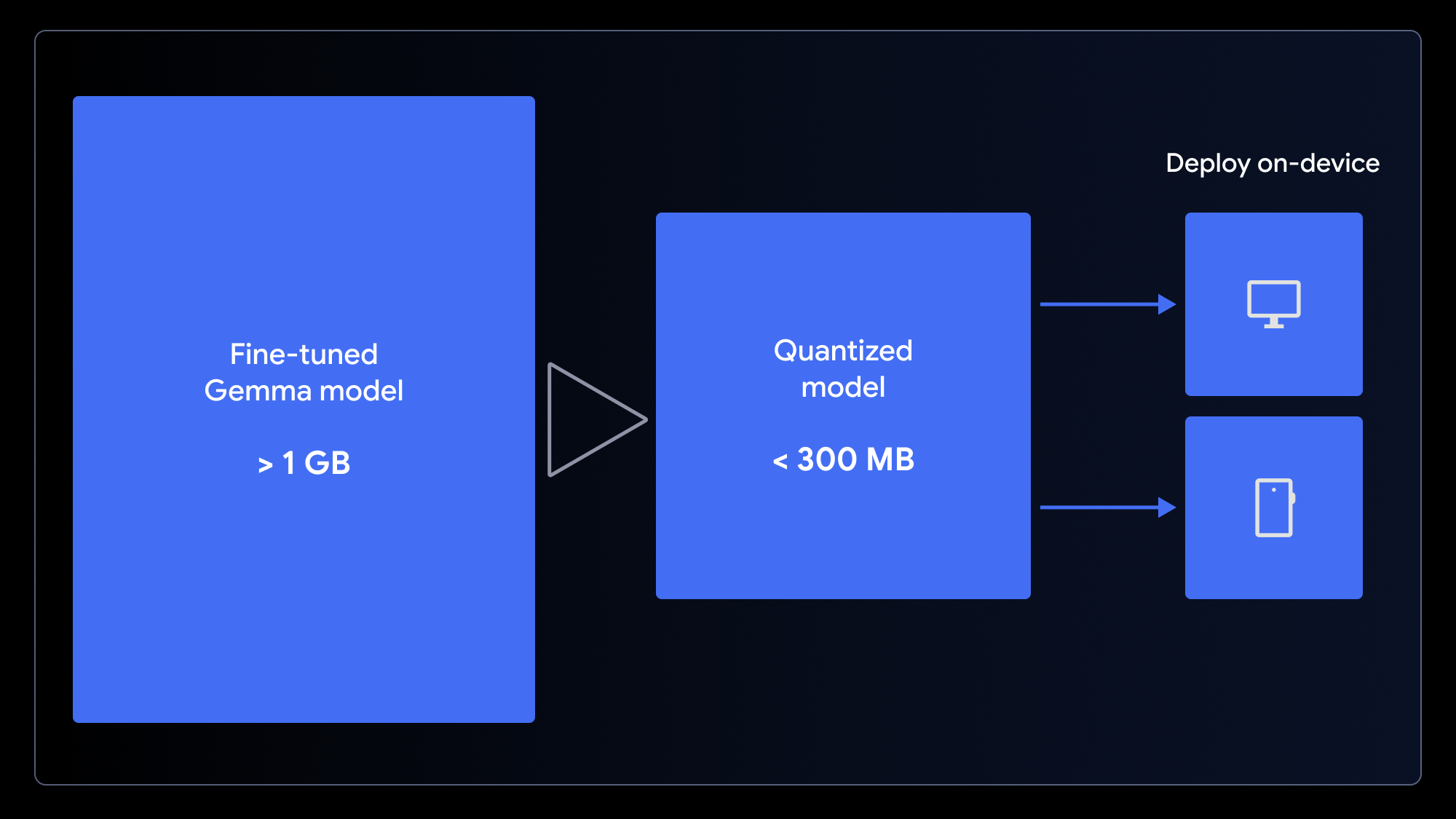
Untuk menyiapkan model Anda untuk aplikasi web, kuantisasi dan konversikan dalam satu langkah menggunakan notebook konversi LiteRT untuk digunakan dengan MediaPipe atau notebook konversi ONNX untuk digunakan dengan Transformers.js. Framework ini memungkinkan kita menjalankan sisi klien LLM di browser dengan memanfaatkan WebGPU, API web modern yang memberikan akses aplikasi ke hardware perangkat lokal untuk komputasi, mengeliminasi perlunya pengaturan server yang rumit dan biaya inferensi per panggilan.
Sekarang Anda bisa menjalankan model yang telah disesuaikan secara langsung di browser! Download contoh aplikasi web dan ubah satu baris kode untuk menyambungkan model baru Anda.
MediaPipe dan Transformers.js membuat hal ini semakin mudah. Inilah contoh tugas inferensi yang berjalan di dalam worker MediaPipe:
// Initialize the MediaPipe Task
const genai = await FilesetResolver.forGenAiTasks('https://cdn.jsdelivr.net/npm/@mediapipe/tasks-genai@latest/wasm');
llmInference = await LlmInference.createFromOptions(genai, {
baseOptions: { modelAssetPath: 'path/to/yourmodel.task' }
});
// Format the prompt and generate a response
const prompt = `Translate this text to emoji: what a fun party!`;
const response = await llmInference.generateResponse(prompt);Setelah model di-cache di perangkat pengguna, permintaan berikutnya berjalan secara lokal dengan latensi rendah, data pengguna sepenuhnya tetap pribadi, dan aplikasi Anda tetap berfungsi meskipun sedang offline.
Suka dengan aplikasi Anda? Bagikan dengan menguploadnya ke Hugging Face Spaces (sama seperti demo).
Anda tidak perlu menjadi pakar AI atau data scientist untuk membuat model AI khusus. Anda bisa meningkatkan performa model Gemma dengan menggunakan set data yang relatif kecil—dan hanya membutuhkan waktu beberapa menit, bukan jam.
Kami harap Anda terinspirasi untuk membuat variasi model Anda sendiri. Dengan menggunakan teknik-teknik ini, Anda bisa membangun aplikasi AI tangguh yang tidak hanya disesuaikan untuk kebutuhan Anda, tetapi juga memberikan pengalaman pengguna yang superior: cepat, privat, dan dapat diakses oleh siapa pun, di mana pun.
Kode sumber dan sumber daya lengkap untuk project ini tersedia untuk membantu Anda memulai:

GenAI di perangkat pada Chrome, Chromebook Plus, dan Pixel Watch dengan LiteRT-LM

Announcing User Simulation in ADK Evaluation

Google AI Edge Gallery: Kini dengan Audio dan di Google Play

Announcing the Agent Development Kit for Go: Build Powerful AI Agents with Your Favorite Languages