

Gemma는 Gemini 모델을 구동하는 것과 동일한 기술로 개발된 경량의 최첨단 개방형 모델 컬렉션입니다. 다양한 크기로 제공되어 누구나 자신의 인프라에서 적용하고 실행할 수 있습니다. 이러한 성능과 접근성의 결합 덕분에 2억 5천만 건 이상의 다운로드와 8만 5천 건 이상의 변형 모델이 커뮤니티에 공개되었으며, 이는 다양한 작업과 도메인에서 활용되고 있습니다.
고도로 전문화된 맞춤형 모델을 만드는 데 고가의 하드웨어는 필요 없습니다. Gemma 3 270M는 콤팩트한 크기 덕분에 새로운 사용 사례에 맞게 신속하게 파인 튜닝하고 온디바이스에 배포할 수 있으므로 유연하게 모델을 개발할 수 있고 강력한 도구를 온전히 제어할 수 있습니다.
이것이 얼마나 간단한지 보여드리고자, 본 게시물에서는 텍스트를 이모티콘으로 변환하는 자체 모델을 학습하고 이를 웹 앱에서 테스트하는 예시를 상세히 소개합니다. 실생활에서 사용하는 특정 이모티콘을 모델에 학습시켜 개인 맞춤형 이모티콘 생성기를 만들 수도 있습니다. 라이브 데모에서 직접 체험해 보세요.
한 시간 이내에 작업별 모델을 생성하는 전 과정을 안내해 드리겠습니다. 여러분이 배울 내용은 다음과 같습니다.
기본적으로 LLM은 범용 모델입니다. Gemma에 텍스트를 이모티콘으로 변화해달라고 요청하면 요청한 변환 이외에 대화체 표현 등이 함께 생성될 수도 있습니다.
프롬프트:
다음 텍스트를 3~5개의 이모티콘을 창의적으로 조합한 형태로 변환해 주세요. "정말 재미있는 파티야"
모델 출력(예):
물론이죠! 이모티콘으로 이렇게 변환했어요. 🥳🎉🎈
앱의 경우 Gemma는 이모티콘만 출력해야 합니다. 복잡한 프롬프트 엔지니어링을 시도할 수 있지만, 특정 출력 형식을 적용하고 모델에 새로운 지식을 가르치는 가장 확실한 방법은 예시 데이터를 기반으로 모델을 파인 튜닝하는 것입니다. 따라서 모델이 특정 이모티콘을 사용하도록 가르치려면 텍스트와 이모티콘 예시가 포함된 데이터 세트를 사용해 모델을 학습시켜야 합니다.
더 많은 예시를 제공할수록 모델은 더 잘 학습합니다. 따라서 동일한 이모티콘 출력을 위해 AI가 다양한 텍스트 구문을 생성하도록 요청하면 손쉽게 데이터 세트를 더 탄탄하게 만들 수 있습니다. 재미 삼아 팝송과 팬덤과 관련된 이모티콘으로 이 작업을 수행했습니다.
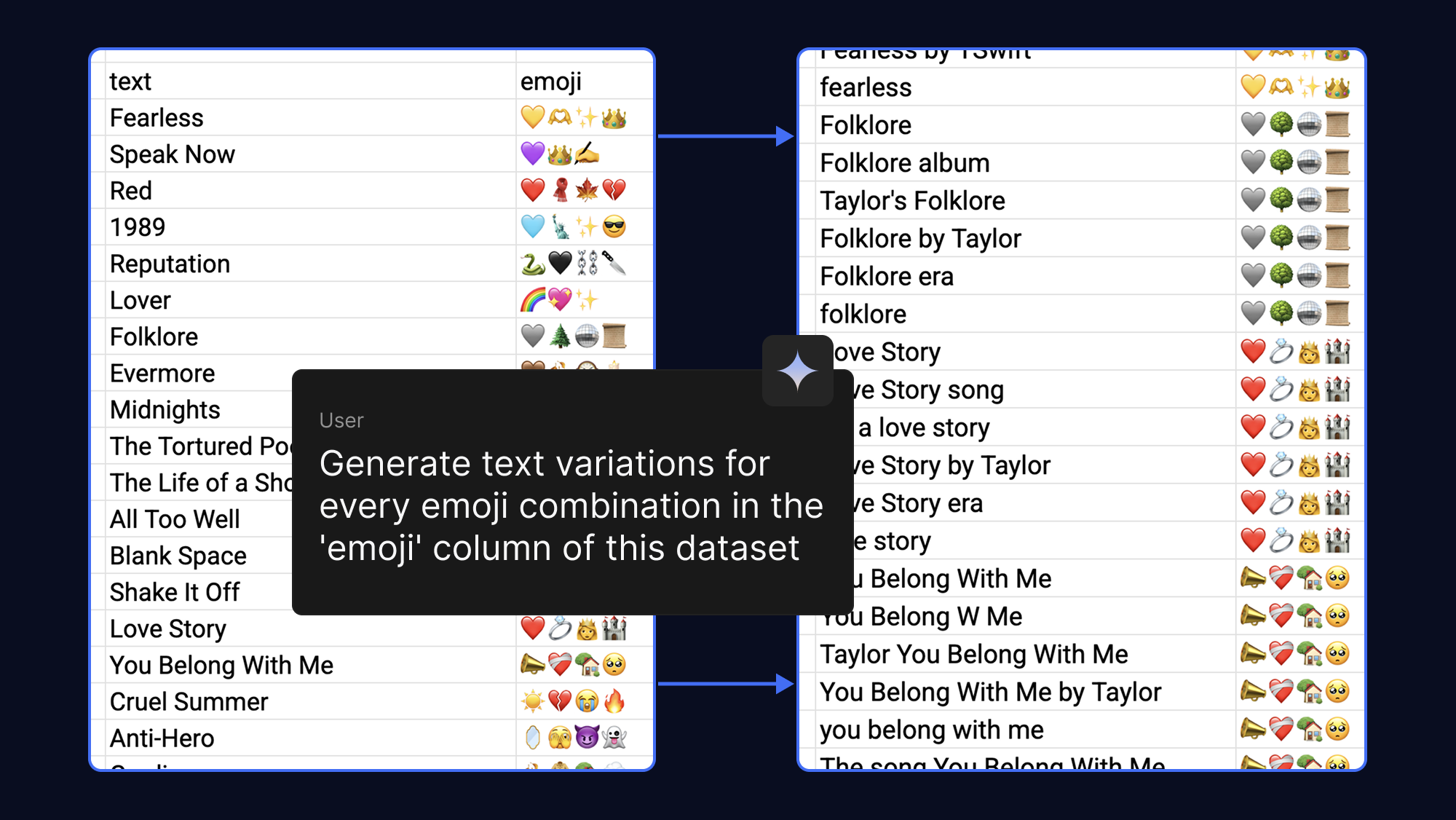
모델 파인 튜닝에는 막대한 양의 VRAM이 필요했습니다. 그러나 PEFT(Parameter-Efficient Fine-Tuning: 매개변수 효율적 미세 조정) 기술인 QLoRA(Quantized Low-Rank Adaptation: 양자화된 저순위 적응)를 사용하면 소수의 가중치만 업데이트하면 됩니다. 덕분에 메모리 요구사항이 크게 줄어들어 Google Colab에서 무료 T4 GPU 가속 사용 시 몇 분 만에 Gemma 3 270M을 파인 튜닝할 수 있습니다.
예시 데이터 세트로 시작하거나 템플릿을 자신만의 이모티콘으로 채우세요. 그러면 파인 튜닝 노트북을 실행하여 데이터 세트를 로드하고 모델을 학습시키며 새 모델의 성능을 원래 모델의 성능과 비교하여 테스트할 수 있습니다.
이제 맞춤형 모델이 확보되었으니 무엇을 할 수 있을까요? 보통 휴대기기나 컴퓨터에서 이모티콘을 사용하므로 모델을 온디바이스 앱에 배포하는 것이 좋습니다.
원래 모델은 작지만 여전히 1GB가 넘습니다. 사용자에게 빠른 로딩 경험을 보장하기 위해서는 모델을 더 작게 만들어야 합니다. 이를 위해 모델의 가중치 정밀도를 (예를 들어 16비트에서 4비트 정수로) 낮추는 과정인 양자화를 사용할 수 있습니다. 이렇게 하면 많은 작업에서 성능 저하를 최소화하면서 파일 크기를 크게 줄일 수 있습니다.
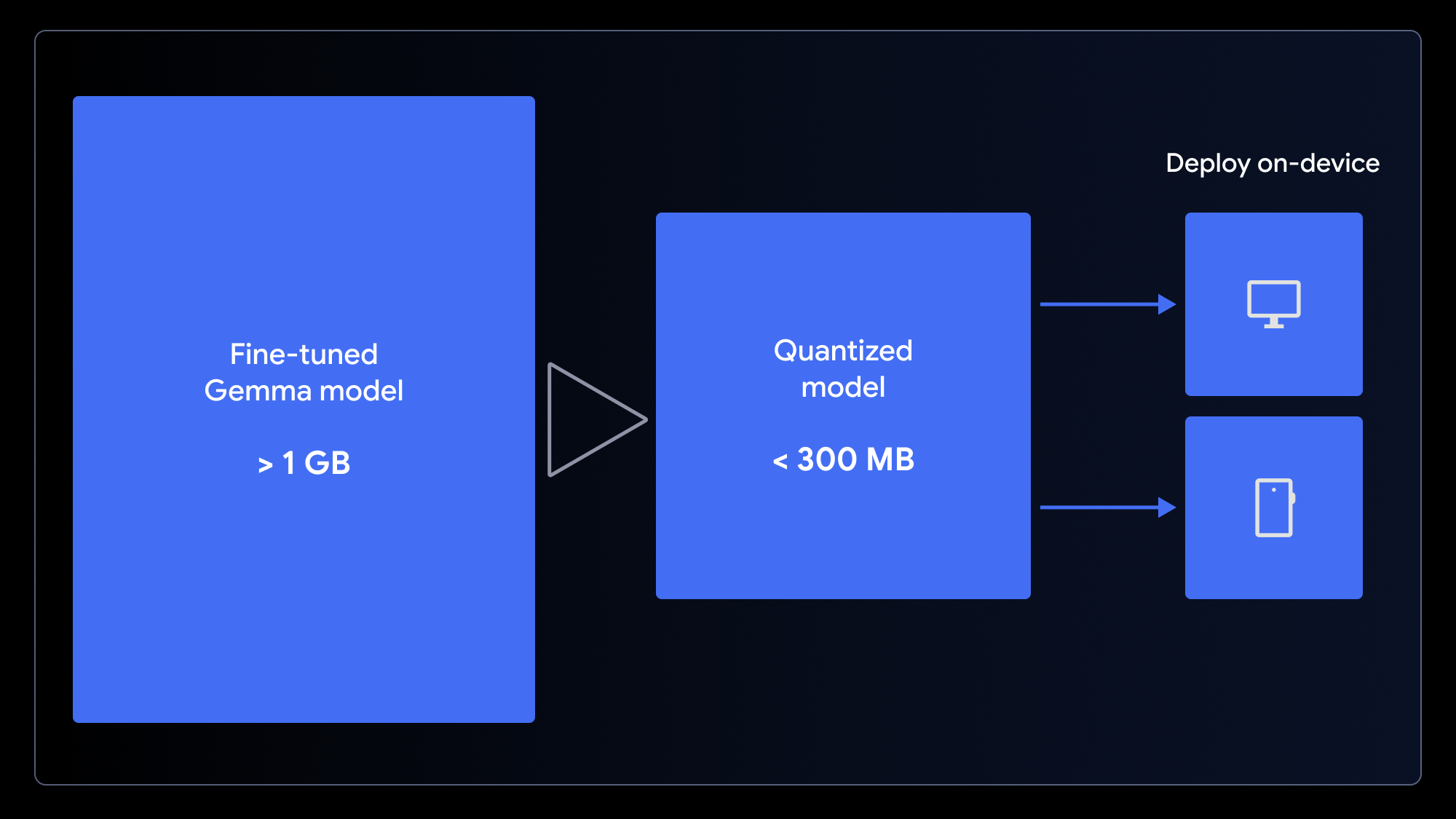
모델을 웹 앱에서 사용할 수 있도록 준비하려면 LiteRT 변환 노트북(MediaPipe용)이나 ONNX 변환 노트북(Transformers.js용) 중 하나를 사용하여 한 번의 단계로 모델을 양자화하고 변환하면 됩니다. 이러한 프레임워크는 WebGPU를 활용하여 브라우저에서 LLM을 클라이언트 측에서 실행할 수 있도록 합니다. WebGPU는 앱이 연산을 위해 로컬 기기의 하드웨어에 액세스할 수 있도록 하는 최신 웹 API로, 복잡한 서버 설정이나 호출당 추론 비용 없이도 모델을 구동할 수 있게 합니다.
이제 브라우저에서 직접 맞춤형 모델을 실행할 수 있습니다! 예시 웹 앱을 다운로드하고 코드 한 줄만 변경하면 새 모델을 연결할 수 있습니다.
MediaPipe와 Transformers.js을 사용하면 이 작업이 간단해집니다. 아래에 MediaPipe 작업자 내에서 실행되는 추론 작업의 예가 나와 있습니다.
// Initialize the MediaPipe Task
const genai = await FilesetResolver.forGenAiTasks('https://cdn.jsdelivr.net/npm/@mediapipe/tasks-genai@latest/wasm');
llmInference = await LlmInference.createFromOptions(genai, {
baseOptions: { modelAssetPath: 'path/to/yourmodel.task' }
});
// Format the prompt and generate a response
const prompt = `Translate this text to emoji: what a fun party!`;
const response = await llmInference.generateResponse(prompt);모델이 사용자의 기기에 캐시되면 후속 요청이 짧은 지연 시간으로 로컬에서 실행되고, 사용자 데이터는 완전히 비공개로 유지되며, 오프라인 상태에서도 앱이 작동합니다.
앱이 마음에 드시나요? Hugging Face Spaces에 업로드하여 공유해 주세요. (데모처럼요.)
특화된 AI 모델을 만들기 위해 AI 전문가나 데이터 과학자가 될 필요는 없습니다. 비교적 작은 데이터 세트를 사용하여 Gemma 모델 성능을 향상시킬 수 있으며, 몇 시간이 아니라 몇 분 정도만 있으면 됩니다.
여러분만의 변형 모델을 만드는 데 도움이 되길 바랍니다. 이러한 기법을 사용하면 필요에 맞게 사용자 설정할 수 있을 뿐만 아니라 빠르고 개인적이며 누구든 어디서나 액세스할 수 있는 우수한 사용자 경험도 제공하는 강력한 AI 애플리케이션을 개발할 수 있습니다.
시작하는 데 이 프로젝트의 전체 소스 코드와 리소스가 도움이 될 것입니다.

LiteRT-LM이 탑재된 Chrome, Chromebook Plus, Pixel Watch의 온디바이스 생성형 AI

Announcing the Agent Development Kit for Go: Build Powerful AI Agents with Your Favorite Languages

Google AI Edge Gallery: 이제 오디오와 Google Play에서 사용 가능

Announcing User Simulation in ADK Evaluation