

Gemma 2 is the latest version in Google's family of lightweight, state-of-the-art open models built from the same research and technology used to create the Gemini models. Large language models (LLMs) like Gemma are remarkably versatile, opening up many potential integrations for business processes. This blog explores how you can use Gemma to gauge the sentiment of a conversation, summarize that conversation's content, and assist with creating a reply for a difficult conversation that can then be approved by a person. One of the key requirements is that customers who have expressed a negative sentiment have their needs addressed in near real-time, which means that we will need to make use of a streaming data pipeline that leverages LLM's with minimal latency.
You can also see the complete code for this pipeline and run the example in Google Colab. See Use Gemma to gauge sentiment and summarize conversations.
Gemma 2 offers unmatched performance at size. Gemma models have been shown to achieve exceptional benchmark results , even outperforming some larger models. The small size of the models enables architectures where the model is deployed or embedded directly onto the streaming data processing pipeline, allowing for the benefits, such as:
Dataflow provides a scalable, unified batch and streaming processing platform. With Dataflow, you can use the Apache Beam Python SDK to develop streaming data, event processing pipelines. Dataflow provides the following benefits:
The following example shows how to embed the Gemma model within the streaming data pipeline for running inference using Dataflow.
This scenario revolves around a bustling food chain grappling with analyzing and storing a high volume of customer support requests through various chat channels. These interactions include both chats generated by automated chatbots and more nuanced conversations that require the attention of live support staff. In response to this challenge, we've set ambitious goals:
The solution uses a pipeline that processes completed chat messages in near real time. Gemma is used in the first instance to carry out analysis work monitoring the sentiment of these chats. All chats are then summarized, with positive or neutral sentiment chats sent directly to a data platform, BigQuery, by using the out-of-the-box I/Os with Dataflow. For chats that report a negative sentiment, we use Gemma to ask the model to craft a contextually appropriate response for the dissatisfied customer. This response is then sent to a human for review, allowing support staff to refine the message before it reaches a potentially dissatisfied customer.
With this use case, we explore some interesting aspects of using an LLM within a pipeline. For example, there are challenges with having to process the responses in code, given the non-deterministic responses that can be accepted. For example, we ask our LLM to respond in JSON, which it is not guaranteed to do. This request requires us to parse and validate the response, which is a similar process to how you would normally process data from sources that may not have correctly structured data.
With this solution, customers can experience faster response times and receive personalized attention when issues arise. The automation of positive chat summarization frees up time for support staff, allowing them to focus on more complex interactions. Additionally, the in-depth analysis of chat data can drive data-driven decision-making while the system's scalability lets it effortlessly adapt to increasing chat volumes without compromising response quality.
The pipeline flow can be seen below:
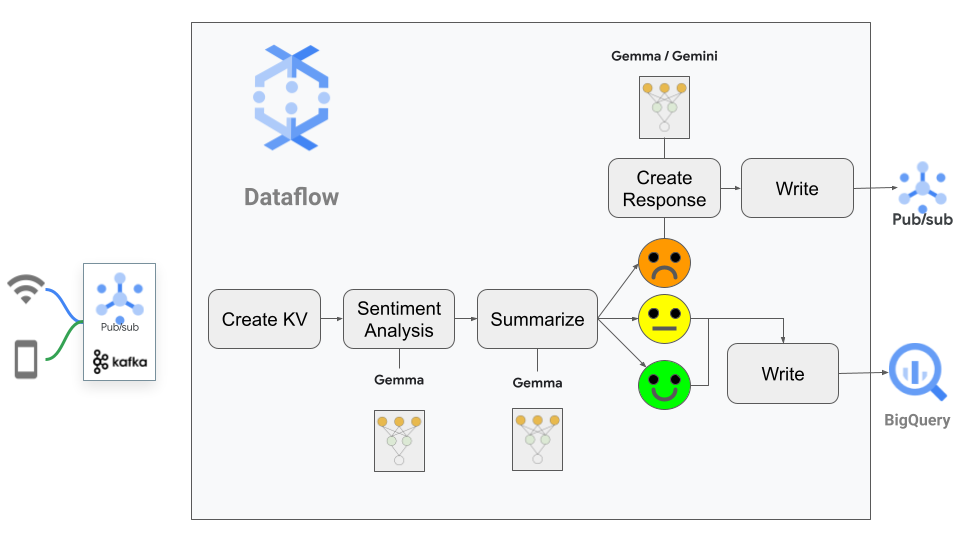
The high-level pipeline can be described with a few lines:
2. The pipeline passes the text from this message to Gemma with a prompt. The pipeline requests that two tasks be completed.
3. Next, the pipeline branches, depending on the sentiment score:
In our example, we use Gemma through the KerasNLP, and we use Kaggle's 'Instruction tuned' gemma2_keras_gemma2_instruct_2b_en variant. You must download the model and store it in a location that the pipeline can access.
Although it's possible to use CPUs for testing and development, given the inference times, for a production system we need to use GPUs on the Dataflow ML service. The use of GPUs with Dataflow is facilitated by a custom container. Details for this setup are available at Dataflow GPU support. We recommend that you follow the local development guide for development, which allows for rapid testing of the pipeline. You can also reference the guide for using Gemma on Dataflow, which includes links to an example Docker file.
The RunInference transform in Apache Beam is at the heart of this solution, making use of a model handler for configuration and abstracting the user from the boilerplate code needed for productionization. Most model types can be supported with configuration only using Beam's built in model handlers, but for Gemma, this blog makes use of a custom model handler, which gives us full control of our interactions with the model while still using all the machinery that RunInference provides for processing. The pipeline custom_model_gemma.py has an example GemmModelHandler that you can use. Please note the use of the max_length value used in the model.generate() call from that GemmModelHandler. This value controls the maximum length of Gemma's response to queries and will need to be changed to match the needs of the use case, for this blog we used the value 512.
Tip: For this blog, we found that using the jax keras backend performed significantly better. To enable this, the DockerFile must contain the instruction ENV KERAS_BACKEND="jax". This must be set in your container before the worker starts up Beam (which imports Keras)
The first step in the pipeline is standard for event processing systems: we need to read the JSON messages that our upstream systems have created, which package chat messages into a simple structure that includes the chat ID.
chats = ( pipeline | "Read Topic" >>
beam.io.ReadFromPubSub(subscription=args.messages_subscription)
| "Decode" >> beam.Map(lambda x: x.decode("utf-8")
)The following example shows one of these JSON messages, as well as a very important discussion about pineapple and pizza, with ID 221 being our customer.
{
"id": 1,
"user_id": 221,
"chat_message": "\\nid 221: Hay I am really annoyed that your menu includes a pizza with pineapple on it! \\nid 331: Sorry to hear that , but pineapple is nice on pizza\\nid 221: What a terrible thing to say! Its never ok, so unhappy right now! \\n"
}We now have a PCollection of python chat objects. In the next step, we extract the needed values from these chat messages and incorporate them into a prompt to pass to our instruction tuned LLM. To do this step, we create a prompt template that provides instructions for the model.
prompt_template = """
<prompt>
Provide the results of doing these two tasks on the chat history provided below for the user {}
task 1 : assess if the tone is happy = 1 , neutral = 0 or angry = -1
task 2 : summarize the text with a maximum of 512 characters
Output the results as a json with fields [sentiment, summary]
@@@{}@@@
<answer>
"""The following is a example of a prompt being sent to the model:
<prompt>
Provide the results of doing these two tasks on the chat history provided below for the user 221
task 1 : assess if the tone is happy = 1 , neutral = 0 or angry = -1
task 2 : summarize the text with a maximum of 512 characters
Output the results as a json with fields [sentiment, summary]
@@@"\\nid 221: Hay I am really annoyed that your menu includes a pizza with pineapple on it! \\nid 331: Sorry to hear that , but pineapple is nice on pizza\\nid 221: What a terrible thing to say! Its never ok, so unhappy right now! \\n"@@@
<answer>Some notes about the prompt:
2. With smaller, less powerful models, you might get better responses by simplifying the instructions to a single task and making multiple calls against the model.
3. We limited chat message summaries to a maximum of 512 characters. Match this value with the value that is provided in the max_length config to the Gemma generate call.
4. The three ampersands, '@@@' are used as a trick to allow us to extract the original chats from the message after processing. Other ways we can do this task include:
5. As we need to process the response in code, we ask the LLM to create a JSON representation of its answer with two fields: sentiment and summary.
To create the prompt, we need to parse the information from our source JSON message and then insert it into the template. We encapsulate this process in a Beam DoFN and use it in our pipeline. In our yield statement, we construct a key-value structure, with the chat ID being the key. This structure allows us to match the chat to the inference when we call the model.
# Create the prompt using the information from the chat
class CreatePrompt(beam.DoFn):
def process(self, element, *args, **kwargs):
user_chat = json.loads(element)
chat_id = user_chat['id']
user_id = user_chat['user_id']
messages = user_chat['chat_message']
yield (chat_id, prompt_template.format(user_id, messages))
prompts = chats | "Create Prompt" >> beam.ParDo(CreatePrompt())We are now ready to call our model. Thanks to the RunInference machinery, this step is straightforward. We wrap the GemmaModelHandler within a KeyedModelhandler, which tells RunInference to accept the incoming data as a key-value pair tuple. During development and testing, the model is stored in the gemma2 directory. When running the model on the Dataflow ML service, the model is stored in Google Cloud Storage, with the URI format gs://<your_bucket>/gemma-directory.
keyed_model_handler = KeyedModelHandler(GemmaModelHandler('gemma2'))
results = prompts | "RunInference-Gemma" >> RunInference(keyed_model_handler)The results collection now contains results from the LLM call. Here things get a little interesting: although the LLM call is code, unlike calling just another function, the results are not deterministic! This includes that final bit of our prompt request "Output the results as a JSON with fields [sentiment, summary]". In general, the response matches that shape, but it’s not guaranteed. We need to be a little defensive here and validate our input. If it fails the validation, we output the results to an error collection. In this sample, we leave those values there. For a production pipeline, you might want to let the LLM try a second time and run the error collection results in RunInference again and then flatten the response with the results collection. Because Beam pipelines are Directed Acyclic Graphs, we can’t create a loop here.
We now take the results collection and process the LLM output. To process the results of RunInference, we create a new DoFn SentimentAnalysis and function extract_model_reply This step returns an object of type PredictionResult:
def extract_model_reply(model_inference):
match = re.search(r"(\{[\s\S]*?\})", model_inference)
json_str = match.group(1)
result = json.loads(json_str)
if all(key in result for key in ['sentiment', 'summary']):
return result
raise Exception('Malformed model reply')class SentimentAnalysis(beam.DoFn):
def process(self, element):
key = element[0]
match = re.search(r"@@@([\s\S]*?)@@@", element[1].example)
chats = match.group(1)
try:
# The result will contain the prompt, replace the prompt with ""
result = extract_model_reply(element[1].inference.replace(element[1].example, ""))
processed_result = (key, chats, result['sentiment'], result['summary'])
if (result['sentiment'] <0):
output = beam.TaggedOutput('negative', processed_result)
else:
output = beam.TaggedOutput('main', processed_result)
except Exception as err:
print("ERROR!" + str(err))
output = beam.TaggedOutput('error', element)
yield outputIt's worth spending a few minutes on the need for extract_model_reply(). Because the model is self-hosted, we cannot guarantee that the text will be a JSON output. To ensure that we get a JSON output, we need to run a couple of checks. One benefit of using the Gemini API is that it includes a feature that ensures the output is always JSON, known as constrained decoding.
Let’s now use these functions in our pipeline:
filtered_results = (results | "Process Results" >> beam.ParDo(SentimentAnalysis()).with_outputs('main','negative','error'))Using with_outputs creates multiple accessible collections in filtered_results. The main collection has sentiments and summaries for positive and neutral reviews, while error contains any unparsable responses from the LLM. You can send these collections to other sources, such as BigQuery, with a write transform. This example doesn’t demonstrate this step, however, the negative collection is something that we want to do more within this pipeline.
Making sure customers are happy is critical for retention. While we have used a light-hearted example with our pineapple on pizza debate, the direct interactions with a customer should always strive for empathy and positive responses from all parts of an organization. At this stage, we pass on this chat to one of the trained support representatives, but we can still see if the LLM is able to assist that support person in reducing the time to resolution.
For this step, we make a call to the model and ask it to formulate a response. We again use the Gemma 2B model for this call in the code.
generated_responses = (results.negative
| "Generate Response" >> beam.Map(lambda x: ((x[0], x[3]), "<prompt>Generate an apology response for the user in this chat text: " + x[1] + "<answer>"))
| "Gemma-Response" >> RunInference(keyed_model_handler)In general, you wrap the prompt creation code in a DoFn, but it is also possible to use a simple lambda in the pipeline code itself. Here we generate a prompt that contains the original chat message, which was extracted in the SentimentAnalysis function.
For local running and testing we can make use of some simple print statements to see the outputs on the various PCollections:
generated_responses | "Print Response" >> beam.Map(print)
filtered_results.main | "Print Main" >> beam.Map(print)
filtered_results.error | "Print Errors" >> beam.Map(print)Of course for the real usage, these outputs will be sent to various sinks such as Pub/Sub and BigQuery.
Lets see how the model does with the previous JSON message:
Step 1: Sentiment analysis and summarization
"sentiment": -1,
"summary": "User 221 is very unhappy about the presence of pineapple on pizza."
The responses that the 2B model generated aren’t bad. The sentiment is correct, and because the results of the summary are more subjective, the correctness of the response depends on the downstream uses of this information.
Step 2: Generated response
"I understand that you're upset about the pineapple pizza. It's a very personal preference, and I apologize that it might have caused you some frustration. We strive to offer a diverse menu to cater to a wide range of tastes, and we're always open to feedback. Would you like to share your thoughts on the pizza with pineapple?"
Are these responses acceptable? At this stage, we intend to send the whole data package to a support representative for analysis and if they are happy with it they can send it as is, or they can make some edits and adjustments.
Maybe at this stage we want to make use of a model with more parameters, such as Gemma2 9B or 27B. We could also use a model that is large enough that it requires an API call to an external service call, such as Gemini, instead of being loaded onto a worker. After all, we reduced the work needed to send to these larger models by using the smaller model as a filter. Making these choices is not just a technical decision, but also a business decision. The costs and benefits need to be measured. We can again make use of Dataflow to more easily set up A/B testing.
You also may choose to finetune a model custom to your use case. This is one way of changing the “voice” of the model to suit your needs.
In our generate step, we passed all incoming negative chats to our 2B model. If we wanted to send a portion of the collection to another model, we can use the Partition function in Beam with the filtered_responses.negative collection. By directing some customer messages to different models and having support staff rate the generated responses before sending them, we can collect valuable feedback on response quality and improvement margins.
With those few lines of code, we built a system capable of processing customer sentiment data at high velocity and variability. By using the Gemma 2 open model, with its 'unmatched performance for its size', we were able to incorporate this powerful LLM within a stream processing use case that helps create a better experience for customers.

Scaling Agentic RL: High-Throughput Agentic Training with Tunix

Introducing EmbeddingGemma: The Best-in-Class Open Model for On-Device Embeddings

Introducing Gemma 3 270M: The compact model for hyper-efficient AI

Run Ray on TPU, Part 1: The foundations
Run Ray on TPU, Part 2: Ray AI libraries