

Gemma 2 は、Google の最先端軽量オープンモデル ファミリーの最新バージョンで、Gemini モデルと同じ研究技術で構築されています。Gemma のような大規模言語モデル(LLM)は非常に汎用性が高く、さまざまなビジネス プロセスに組み込める可能性を秘めています。このブログでは、Gemma を使って会話の感情を測定し、その会話の内容を要約して、難しい会話への応答作りを手伝って、人間の承認を得る方法について説明します。重要な要件の 1 つが、ネガティブな感情を表した顧客のニーズに対し、ほぼリアルタイムに対処することです。つまり、ストリーミング データ パイプラインを利用し、LLM を最小限のレイテンシで活用する必要があります。
Gemma 2 は、サイズを超えた比類のないパフォーマンスを発揮します。Gemma モデルは、圧倒的なベンチマーク結果を出しており、さらに大きなモデルを凌駕する場合もあります。サイズが小さいので、モデルをストリーミング データ処理パイプラインに直接デプロイしたり、埋め込んだりするアーキテクチャを実現できます。これは次のような利点をもたらします。
Dataflow はスケーラブルな統合型バッチおよびストリーミング処理プラットフォームです。Dataflow を利用すると、Apache Beam Python SDK を使ってデータのストリーミングやイベント処理パイプラインを開発できます。Dataflow には次の利点があります。
以降の例は、Gemma モデルをストリーミング データ パイプラインに埋め込み、Dataflow を使って推論を行う方法を示しています。
このシナリオの中心にあるのは、にぎやかなフードチェーンです。ここでは、さまざまなチャット チャンネルを通じて寄せられる大量のカスタマー サポート リクエストを分析、保存しています。その中には、自動チャットボットによって生成されたチャットも、担当者が慎重に対応している注意が必要な会話もあります。この課題に対応するため、次のような野心的な目標を設定しました。
このソリューションでは、完了したチャット メッセージをほぼリアルタイムに処理するパイプラインを使います。まず、Gemma を使って分析を行い、チャットの感情を監視します。その後、すべてのチャットを要約し、ポジティブまたはニュートラルな感情のチャットは、データ プラットフォームである BigQuery に直接送信します。このとき、Dataflow に標準搭載されている I/O 機能を利用します。ネガティブな感情のチャットについては、Gemma に依頼して、不満を持った利用者向けに、文脈に応じた適切な応答を生成します。その後、応答を人間に送信して確認してもらいます。これにより、サポート担当者がメッセージを見直してから、不満を抱いているかもしれない顧客に届けることができます。
このユースケースでは、パイプラインで LLM を使うにあたり、注意すべき点について検討します。たとえば、どんな応答を受け取るかは予測できないので、応答をコードで処理しなければならないという課題があります。つまり、LLM に JSON で応答するように依頼しても、必ずそうなるとは限らないので、応答を解析して検証しなければなりません。これは、正しく構造化されていない可能性があるデータを処理するプロセスに似ています。
このソリューションを使うと、顧客は待つことがなくなり、問題が発生したときに個人に合わせた対応を受けることになります。ポジティブなチャットを自動的に要約することで、サポート担当者の手間を省いて、複雑な対応に集中できるようにします。また、チャットデータを詳しく分析することで、データ主導型意思決定を推進できるようになります。さらに、システムはスケーラブルなので、チャットの量が増加しても応答品質を損なうことなく、簡単に対応できます。
パイプラインのフローは以下のとおりです。
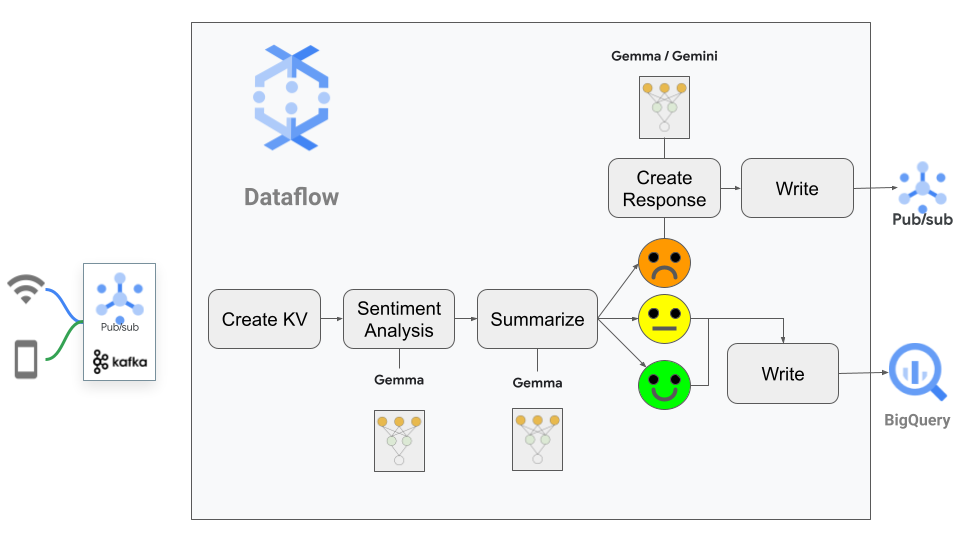
パイプラインの概要は、数行で説明できます。
2. このメッセージのテキストからプロンプトを生成し、Gemma に渡します。その際に、2 つのタスクを行うことをリクエストします。
3. 次に、パイプラインは、感情スコアに応じて分岐します。
この例では、KerasNLP を通して Gemma を使います。今回利用するのは、Kaggle の「インストラクション チューニング版」gemma2_keras_gemma2_instruct_2b_en バリアントです。このモデルをダウンロードし、パイプラインからアクセスできる場所に保存します。
CPU を使ってテストや開発を行うこともできますが、推論にかかる時間を考慮すると、本番システムでは Dataflow ML サービスの GPU を使う必要があります。カスタム コンテナを使うと、Dataflow で GPU を利用しやすくなります。詳しい設定の手順は、Dataflow GPU サポートで公開されています。ローカル開発の開発ガイドに従い、パイプラインをすばやくテストできるようにすることをおすすめします。Dataflow で Gemma を使うためのガイドもご覧ください。サンプルの Docker ファイルへのリンクもこの中にあります。
このソリューションの中心となるのが、Apache Beam の RunInference 変換です。モデルハンドラを使って設定を行うと、本番環境に必要なボイラープレート コードは不要になります。ほとんどのタイプのモデルでは、Beam の組み込みモデルハンドラだけを使った設定がサポートされています。ただし、このブログでは、Gemma 用にカスタムのモデルハンドラを使っています。こうすることで、モデルとのインタラクションを完全に制御しつつ、RunInference が提供するすべての処理機構を利用できるようになります。パイプライン custom_model_gemma.py には、GemmModelHandler の例があるので、これを利用することもできます。GemmModelHandler から model.generate() を呼び出すときに使っている max_length 値に注意してください。この値は、問い合わせに対する Gemma の応答の最大長を制御するもので、ユースケースのニーズに合わせて変更する必要があります。このブログでは、値 512 を使いました。
ヒント: このブログでは、jax keras バックエンドを使うと、パフォーマンスが大幅に向上することがわかりました。これを有効にするには、DockerFile に ENV KERAS_BACKEND="jax" 命令を含めます。これは、ワーカーが Beam を起動する(これにより、Keras がインポートされます)前にコンテナに設定する必要があります。
パイプラインの最初のステップは、イベント処理システムとして一般的なもので、上流システムが生成した JSON メッセージを読み取ります。このメッセージでは、チャット メッセージをチャット ID を含むシンプルな構造にパッケージ化しています。
chats = ( pipeline | "Read Topic" >>
beam.io.ReadFromPubSub(subscription=args.messages_subscription)
| "Decode" >> beam.Map(lambda x: x.decode("utf-8")
)次に示すのは、この JSON メッセージの例です。パイナップルとピザに関するとても重要なディスカッションが行われています。ID 221 は顧客を示します。
{
"id": 1,
"user_id": 221,
"chat_message": "\\nid 221: Hay I am really annoyed that your menu includes a pizza with pineapple on it! \\nid 331: Sorry to hear that , but pineapple is nice on pizza\\nid 221: What a terrible thing to say! Its never ok, so unhappy right now! \\n"
}これで、Python チャット オブジェクトの PCollection が利用できるようになりました。次の手順では、チャット メッセージから必要な値を抽出し、それをプロンプトに組み込んで、インストラクション チューニング版の LLM に渡します。この手順を実行するために、モデルへの指示に使うプロンプト テンプレートを作ります。
prompt_template = """
<prompt>
Provide the results of doing these two tasks on the chat history provided below for the user {}
task 1 : assess if the tone is happy = 1 , neutral = 0 or angry = -1
task 2 : summarize the text with a maximum of 512 characters
Output the results as a json with fields [sentiment, summary]
@@@{}@@@
<answer>
"""次に、モデルにプロンプトを送信する例を示します。
<prompt>
Provide the results of doing these two tasks on the chat history provided below for the user 221
task 1 : assess if the tone is happy = 1 , neutral = 0 or angry = -1
task 2 : summarize the text with a maximum of 512 characters
Output the results as a json with fields [sentiment, summary]
@@@"\\nid 221: Hay I am really annoyed that your menu includes a pizza with pineapple on it! \\nid 331: Sorry to hear that , but pineapple is nice on pizza\\nid 221: What a terrible thing to say! Its never ok, so unhappy right now! \\n"@@@
<answer>プロンプトに関する注意事項:
2. 小さくて能力が低いモデルの場合は、指示を 1 つのタスクにとどめ、複数回モデルを呼び出すことで、結果が改善されるかもしれません。
3. チャット メッセージの要約は、最大 512 文字に制限しました。Gemma の generate を呼び出す際は、この値と max_length 設定で指定する値を合わせるようにします。
4. 3つのアットマーク「@@@」は、処理後のメッセージから元のチャットを抽出できるようにするための仕掛けです。他の方法として次のようなものが考えられます。
5. 応答をコードで処理する必要があるため、感情(sentiment)と概要(summary)の 2 つのフィールドがある JSON 表現を作成するよう LLM に依頼します。
プロンプトを作成するには、ソース JSON メッセージの情報を解析してテンプレートに挿入する必要があります。このプロセスを Beam の DoFN にカプセル化し、パイプラインで利用します。yield 文では、チャット ID をキーとして、キーと値の構造を作成します。この構造により、モデルを呼び出すときにチャットと推論の対応付けを行うことができます。
# チャットの情報をもとにプロンプトを生成する
class CreatePrompt(beam.DoFn):
def process(self, element, *args, **kwargs):
user_chat = json.loads(element)
chat_id = user_chat['id']
user_id = user_chat['user_id']
messages = user_chat['chat_message']
yield (chat_id, prompt_template.format(user_id, messages))
prompts = chats | "Create Prompt" >> beam.ParDo(CreatePrompt())これで、モデルを呼び出す準備ができました。RunInference 機構のおかげで、このステップは簡単です。GemmaModelHandler を KeyedModelhandler にラップします。これは、キーと値のペアのタプルを入力データとすることを RunInference に指示するものです。開発およびテストしているときは、モデルを gemma2 ディレクトリに格納します。Dataflow ML サービスでモデルを実行するときは、モデルを Google Cloud Storage に格納します。URI のフォーマットは、gs://<your_bucket>/gemma-directory となります。
keyed_model_handler = KeyedModelHandler(GemmaModelHandler('gemma2'))
results = prompts | "RunInference-Gemma" >> RunInference(keyed_model_handler)これにより、結果のコレクションに LLM を呼び出した結果が入ります。ここで少し興味深い点があります。LLM の呼び出しはコードですが、単なる別の関数呼び出しとは違い、結果が決まるわけではありません。リクエストのプロンプトの最後の部分 "Output the results as a JSON with fields [sentiment, summary]" で、結果を 2 つのフィールドがある JSON で出力することを指示していますが、これが守られない場合もあるということです。通常はこの形式の応答となりますが、それが保証されているわけではありません。ここでは、確実を期すため、入力を検証します。検証に失敗した場合、結果を error コレクションに出力します。この例では、値をそこに残しておきます。本番環境パイプラインの場合は、LLM に再試行させ、error コレクションの結果に対して再度 RunInference を実行してから、応答を結果コレクションに組み入れることができます。Beam のパイプラインは有向非循環グラフであるため、ここでループを作成することはできません。
次に、結果コレクションを受け取り、LLM の出力を処理します。RunInference の結果を処理するために、新しい DoFn SentimentAnalysis と関数 extract_model_reply を作成します。この手順では、PredictionResult 型のオブジェクトが返されます。
def extract_model_reply(model_inference):
match = re.search(r"(\{[\s\S]*?\})", model_inference)
json_str = match.group(1)
result = json.loads(json_str)
if all(key in result for key in ['sentiment', 'summary']):
return result
raise Exception('Malformed model reply')class SentimentAnalysis(beam.DoFn):
def process(self, element):
key = element[0]
match = re.search(r"@@@([\s\S]*?)@@@", element[1].example)
chats = match.group(1)
try:
# The result will contain the prompt, replace the prompt with ""
result = extract_model_reply(element[1].inference.replace(element[1].example, ""))
processed_result = (key, chats, result['sentiment'], result['summary'])
if (result['sentiment'] <0):
output = beam.TaggedOutput('negative', processed_result)
else:
output = beam.TaggedOutput('main', processed_result)
except Exception as err:
print("ERROR!" + str(err))
output = beam.TaggedOutput('error', element)
yield outputここでしばらく、extract_model_reply() が必要な理由について考えてみましょう。モデルはセルフホストであるため、テキストが JSON 出力になることは保証できません。JSON 出力を確実に取得するには、いくつかのチェックを行う必要があります。Gemini API を使う利点の 1 つは、出力が必ず JSON になることを保証する機能があることです。これは、制約付きデコードと呼ばれます。
では、パイプラインで上の関数を使ってみましょう。
filtered_results = (results | "Process Results" >> beam.ParDo(SentimentAnalysis()).with_outputs('main','negative','error'))with_outputs を使うと、アクセス可能な複数のコレクションが filtered_results に生成されます。main コレクションにはポジティブとニュートラルのレビューに対する感情と要約が、error には LLM から返された解析不可能な回答が含まれます。これらのコレクションは、書き込み変換を使って、BigQuery などの別のソースに送信できます。ただし、この例ではこの手順は省略します。このパイプラインで重点的に行いたいのは、negative コレクションの処理です。
顧客を維持するためには、確実に満足してもらうことが重要です。ここでは、パイナップルを乗せたピザについての軽いディスカッションを例に挙げましたが、顧客と直接やり取りする場合、組織のあらゆる部門で共感と前向きな対応を心がける必要があります。この段階では、訓練を受けたサポート担当者にチャットを渡しますが、LLM を活用してサポート担当者を支援し、解決までの時間を短縮することができるはずです。
この手順では、モデルを呼び出して応答を作成してもらいます。ここでも、コードから Gemma 2B モデルを呼び出します。
generated_responses = (results.negative
| "Generate Response" >> beam.Map(lambda x: ((x[0], x[3]), "<prompt>Generate an apology response for the user in this chat text: " + x[1] + "<answer>"))
| "Gemma-Response" >> RunInference(keyed_model_handler)通常、プロンプト作成コードは DoFn でラップしますが、パイプラインのコード自体で単純なラムダを使うこともできます。ここでは、SentimentAnalysis 機能で抽出した元のチャット メッセージを含むプロンプトを生成します。
ローカルで実行してテストする場合、いくつかの簡単な print 文で、さまざまな PCollections の出力を確認できます。
generated_responses | "Print Response" >> beam.Map(print)
filtered_results.main | "Print Main" >> beam.Map(print)
filtered_results.error | "Print Errors" >> beam.Map(print)当然ながら、実際に利用する場合は、出力を Pub/Sub や BigQuery などのさまざまなシンクに送信できます。
先ほどの JSON メッセージを使って、モデルがどのように動作するか見てみましょう。
手順 1: 感情の分析と要約
"sentiment": -1,
"summary": "User 221 is very unhappy about the presence of pineapple on pizza."
2B モデルが生成した応答は悪くありません。感情は正確で、要約の結果は主観性が増しています。この応答が正しいかどうかは、下流でこの情報をどう使うかによって変わってきます。
手順 2: 応答の生成
"I understand that you're upset about the pineapple pizza. It's a very personal preference, and I apologize that it might have caused you some frustration. We strive to offer a diverse menu to cater to a wide range of tastes, and we're always open to feedback. Would you like to share your thoughts on the pizza with pineapple?"
この回答は許容できるでしょうか?この段階では、データ パッケージ全体をサポート担当者に送信することを意図しています。担当者が確認を行ったうえで、満足すればそのまま送信し、そうでなければ編集や調整を行うことができます。
おそらくこの段階では、Gemma 2 9B や 27B など、パラメータ数が多いモデルを使いたいと思うはずです。また、ワーカーに読み込むのではなく、Gemini のように、外部サービスの API 呼び出しが必要になるほどの大きさを持つモデルを使うこともできます。最終的には、小さなモデルをフィルタとして使い、大きなモデルに送信するために必要となる作業を削減しました。この選択には、技術的な理由だけではなく、ビジネス上の理由もあります。コストとメリットの測定も必要です。Dataflow を使うと、ここでも簡単に A/B テストを設定できます。
また、ユースケースに合わせてモデルをファイン チューニングすることもできます。これは、ニーズに合わせてモデルの「声」を変更する方法の 1 つです。
今回の生成ステップでは、受け取ったすべてのネガティブなチャットを 2B モデルに渡しました。コレクションの一部を別のモデルに送信したい場合は、Beam の Partition 機能と filtered_responses.negative コレクションを使うことができます。一部の顧客のメッセージを別のモデルに転送し、サポート担当者が生成された回答を送信前に評価することで、回答の品質や改善の余地に関する貴重なフィードバックを収集できます。
以上のわずかなコードで、顧客感情データを高速かつ柔軟に処理できるシステムを構築しました。「サイズを超えた比類のないパフォーマンスを発揮する」Gemma 2 オープンモデルで、ストリーム処理のユースケースに強力な LLM を組み込み、顧客エクスペリエンスを向上させることができました。

Announcing User Simulation in ADK Evaluation

EmbeddingGemma の概要: オンデバイス埋め込み処理向けの最高水準オープンモデル

Building with Gemini 3 in Jules

Gemma 3 270M の概要: 超高効率 AI のためのコンパクト モデル

Announcing the Data Commons Gemini CLI extension

Announcing the Agent Development Kit for Go: Build Powerful AI Agents with Your Favorite Languages