

Gemma 2는 Gemini 모델을 만드는 데 사용된 것과 동일한 연구 및 기술로 개발된 Google의 최첨단 경량 개방형 모델 제품군의 최신 버전입니다. Gemma 같은 대형 언어 모델(LLM)은 놀라울 정도로 다양한 용도로 활용할 수 있어 비즈니스 프로세스에 있어 수많은 통합의 가능성을 열어줍니다. 이 블로그에서는 Gemma를 사용해 대화에 담긴 감정을 측정하고 대화의 내용을 요약하며 사람이 승인할 수 있는 어려운 대화에 대한 회신 작성을 지원하는 방법을 살펴봅니다. 핵심 요건 중 하나는 부정적인 감정을 표현한 고객의 요구 사항을 거의 실시간으로 해결해야 한다는 점인데, 이는 곧 지연 시간을 최소화하면서 LLM을 활용하는 스트리밍 데이터 파이프라인을 활용해야 한다는 뜻입니다.
Gemma 2는 규모에 비해 타의 추종을 불허하는 성능을 제공합니다. Gemma 모델은 뛰어난 벤치마크 결과를 달성하는 것으로 나타났습니다. 일부 더 큰 모델의 성능을 뛰어넘기도 했습니다. 모델의 크기가 작아 모델이 스트리밍 데이터 처리 파이프라인에 직접 배포되거나 임베드되는 아키텍처를 지원하므로 다음과 같은 장점이 있습니다.
Dataflow는 확장 가능하고 통합된 배치 및 스트리밍 처리 플랫폼을 제공합니다. Dataflow를 통해 Apache Beam Python SDK를 사용하여 스트리밍 데이터, 이벤트 처리 파이프라인을 개발할 수 있습니다. Dataflow는 다음과 같은 이점을 제공합니다.
다음 예에서는 Dataflow를 사용하여 추론을 실행하기 위해 스트리밍 데이터 파이프라인 내에 Gemma 모델을 임베딩하는 방법을 보여줍니다.
이 시나리오는 다양한 채팅 채널을 통해 쏟아지는 대량의 고객 지원 요청을 분석하고 저장하는 문제를 해결하고자 하는 어느 분주한 식품 체인점을 중심으로 진행됩니다. 이 상호작용에는 자동화된 챗봇에서 생성된 채팅과 실시간 지원 담당 직원이 더 세심하게 신경 써야 하는 보다 미묘한 뉘앙스의 대화가 모두 포함됩니다. 이 문제를 해결하기 위해 우선 야심 찬 목표를 설정했습니다.
이 솔루션에서는 완료된 채팅 메시지를 거의 실시간으로 처리하는 파이프라인을 사용합니다. 첫 번째 인스턴스에서 Gemma를 사용하여 이러한 채팅의 감정을 모니터링하는 분석 작업을 수행합니다. 그런 다음 Dataflow로 별도의 구성이 필요 없는 I/O를 사용하여 데이터 플랫폼인 BigQuery로 직접 전송되는 긍정적 또는 중립적 감정의 모든 채팅을 요약합니다. 부정적인 감정을 보고하는 채팅의 경우, Gemma를 사용하여 불만족 고객에게 맞는 문맥에 적절한 답변을 작성하도록 모델에 요청합니다. 이 답변은 검토를 위해 담당자(사람)에게 전송되고 지원 담당자가 메시지를 더 다듬어 잠재적 불만족 고객에게 전달되도록 합니다.
이 사용 사례를 통해 파이프라인 내에서 LLM을 사용하는 몇 가지 흥미로운 측면을 살펴봅니다. 예를 들어, 허용될 수 있는 비확정적 응답이라는 점을 고려할 때, 답변을 코드로 처리해야 한다는 난제가 있습니다. 예컨대, LLM에 JSON으로 응답하도록 요청하더라도 꼭 그렇게 처리된다는 보장이 없습니다. 이 요청에 따라 응답을 파싱하고 입증해야 하는데, 이는 보통 올바르게 구조화된 데이터가 부재할 수도 있는 소스의 데이터를 처리하는 방식과 유사한 프로세스입니다.
고객은 문제가 발생했을 때 이 솔루션을 통해 더 빠른 응답 시간을 경험하고 맞춤형 응답과 관리를 받을 수 있습니다. 긍정적인 채팅 요약의 자동화로 지원 담당자가 더 복잡한 상호작용에 집중할 시간을 확보할 수 있습니다. 또한 채팅 데이터에 대한 심층 분석을 통해 데이터 기반 의사 결정을 내릴 수 있으며, 시스템의 확장성을 통해 응답 품질의 저하 없이 증가하는 채팅의 양에 쉽게 적응할 수 있습니다.
파이프라인 흐름은 아래에서 확인할 수 있습니다.
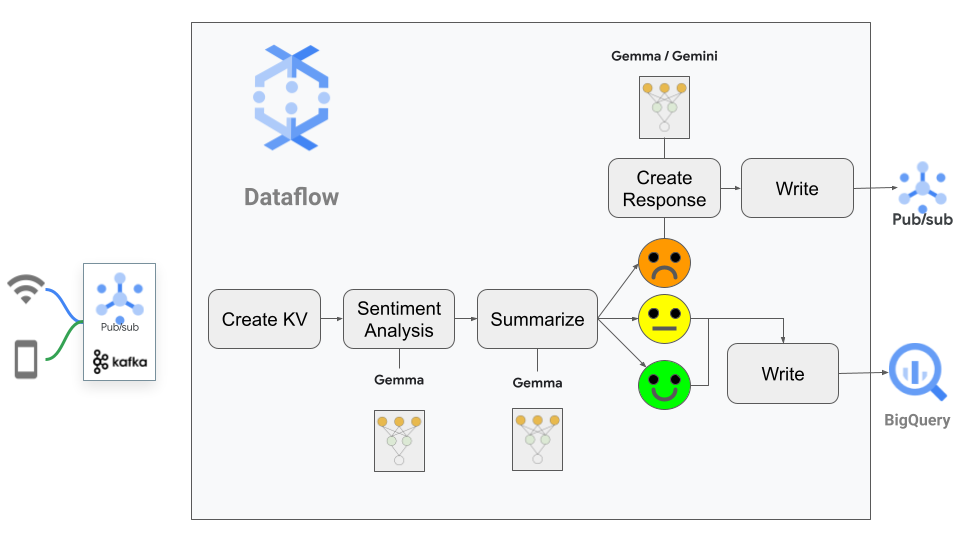
고수준 파이프라인의 개요는 몇 줄로 설명 가능합니다.
2. 파이프라인은 이 메시지의 텍스트를 프롬프트와 함께 Gemma에 전달합니다. 파이프라인은 2가지 작업을 완료하도록 요청합니다.
3. 다음으로, 감정 점수에 따라 파이프라인이 나뉩니다.
이 예에서는 KerasNLP를 통해 Gemma를 사용하고 Kaggle의 '명령 튜닝' gemma2_keras_gemma2_instruct_2b_en 변형을 사용합니다. 모델을 다운로드하여 파이프라인이 액세스할 수 있는 위치에 저장해야 합니다.
테스트와 개발에 CPU를 사용할 수 있지만, 추론 시간을 고려할 때 프로덕션 시스템의 경우 Dataflow ML 서비스에서 GPU를 사용해야 합니다. 사용자 설정 컨테이너로 GPU와 Dataflow의 사용을 촉진합니다. 이 설정에 대한 세부 정보는 Dataflow GPU 지원에서 확인할 수 있습니다. 개발을 위해서 현지 개발 가이드를 따르도록 권장합니다. 이를 통해 파이프라인을 신속하게 테스트할 수 있습니다. Docker 파일 예제에 대한 링크가 포함된 Dataflow에서 Gemma를 사용하기 위한 가이드를 참조할 수도 있습니다.
이 솔루션의 핵심은 Apache Beam의 RunInference 변환입니다. 이를 통해 프로덕션화에 필요한 상용구 코드에서 사용자를 추상화할 수 있고, 구성을 위해 모델 핸들러를 사용할 수 있습니다. 대부분의 모델 유형은 Beam의 내장 모델 핸들러를 사용하는 구성에서만 지원 가능하지만, Gemma의 경우 이 블로그에서는 사용자 설정 모델 핸들러를 사용합니다. 이를 통해 RunInference가 처리를 위해 제공하는 모든 기계를 사용하는 동시에 모델과의 상호작용을 완벽히 제어할 수 있습니다. 파이프라인 custom_model_gemma.py에 여러분이 사용할 수 있는 예제 GemmModelHandler가 있습니다. 해당 GemmModelHandler에서 model.generate() 호출에 사용된 max_length 값의 사용에 유의하세요. 이 값이 쿼리에 대한 Gemma 응답의 최대 길이를 제어합니다. 또한 이 값은 사용 사례의 필요에 맞게 변경되어야 합니다. 이 블로그에서는 512의 값을 사용했습니다.
팁: 이 블로그에 나오는 예의 경우 jax keras 백엔드 사용 시 성능이 훨씬 더 뛰어나다는 사실을 확인했습니다. 이 백엔드를 사용하려면 DockerFile에 ENV KERAS_BACKEND="jax" 명령이 포함되어야 합니다. 작업자가 (Keras를 가져오는) Beam을 시작하기 전에 컨테이너에 이를 설정해야 합니다.
파이프라인의 첫 번째 단계는 이벤트 처리 시스템의 기준입니다. 업스트림 시스템에서 생성한 JSON 메시지를 읽어야 하는데, 이 시스템은 채팅 ID를 포함하는 간단한 구조로 채팅 메시지를 패키징합니다.
chats = ( pipeline | "Read Topic" >>
beam.io.ReadFromPubSub(subscription=args.messages_subscription)
| "Decode" >> beam.Map(lambda x: x.decode("utf-8")
)다음 예는 이런 JSON 메시지 중 하나로, 파인애플과 피자에 대한 매우 중요한 대화입니다. ID 221이 응대해야 할 고객입니다.
{
"id": 1,
"user_id": 221,
"chat_message": "\\nid 221: 이봐요, 파인애플이 들어간 피자가 메뉴에 포함되어 있어 정말 짜증이 나는군요!\\\ nid 331: 죄송하지만 파인애플은 피자에 잘 어울리는 토핑입니다.\\ nid 221: 정말 끔찍한 말이군요! 있을 수 없는 일이에요. 정말 기분이 나쁩니다! \\n"
}현재 Python 채팅 객체의 PCollection이 있습니다. 다음 단계에서는 이러한 채팅 메시지에서 필요한 값을 추출하여 명령 튜닝 LLM으로 전달하는 프롬프트에 통합합니다. 이 단계를 수행하기 위해 모델에 대한 명령을 제공하는 프롬프트 템플릿을 만듭니다.
prompt_template = """
<prompt>
사용자에 대해 아래에 제공된 채팅 기록에서 이 두 작업을 수행한 결과를 제공합니다 {}
작업 1: 만족스러운 어조 = 1, 중립 = 0, 불만족 = -1인지 평가합니다
작업 2: 최대 512자로 텍스트를 요약합니다
[sentiment, summary] 필드가 있는 json으로 결과를 출력합니다
@@@{}@@@
<answer>
"""다음은 모델로 전송되는 프롬프트의 예입니다.
<prompt>
사용자 221을 위해 아래에 제공된 채팅 기록에서 이 두 작업을 수행한 결과를 제공합니다
작업 1: 만족스러운 어조 = 1, 중립 = 0, 불만족 = -1인지 평가합니다1
작업 2: 최대 512자로 텍스트를 요약합니다
[sentiment, summary] 필드가 있는 json으로 결과를 출력합니다
@@@"\\nid 221: 이봐요, 파인애플이 들어간 피자가 메뉴에 포함되어 있어 정말 짜증이 나는군요!\\\ nid 331: 죄송하지만 파인애플은 피자에 잘 어울리는 토핑입니다.\\ nid 221: 정말 끔찍한 말이군요! 있을 수 없는 일이에요. 정말 기분이 나쁩니다! \\n"@@@
<answer>프롬프트에 대한 몇 가지 참고 사항:
2. 더 작고 덜 강력한 모델을 사용하면 단일 작업에 대한 명령을 단순화하고 모델을 여러 번 호출하여 더 나은 응답을 얻을 수 있습니다.
3. 채팅 메시지 요약을 최대 512자로 제한했습니다. 이 값을 Gemma 생성 호출을 위해 max_length config에 제공된 값과 일치시킵니다.
4. 처리 후 메시지에서 원래 채팅을 추출할 수 있도록 3개의 앰퍼샌드 '@@@'를 트릭으로 사용합니다. 이 작업을 수행할 수 있는 다른 방법은 다음과 같습니다.
5. 응답을 코드로 처리해야 하므로 LLM에 두 개의 필드(감정 및 요약)로 답변의 JSON 표현을 생성하도록 요청합니다.
프롬프트를 만들려면 소스 JSON 메시지에서 정보를 파싱한 다음 템플릿에 삽입해야 합니다. 이 프로세스를 Beam DoFN에 캡슐화하여 파이프라인에 사용합니다. Yield 문에서 채팅 ID를 키로 사용하는 키-값 구조를 구성합니다. 이 구조를 사용하면 모델을 호출할 때 채팅을 추론과 일치시킬 수 있습니다.
# 채팅 클래스 CreatePrompt(beam.DoFn)의 정보를 사용하여
프롬프트를 생성합니다.
def process(self, element, *args, **kwargs):
user_chat = json.loads(element)
chat_id = user_chat['id']
user_id = user_chat['user_id']
messages = user_chat['chat_message']
yield (chat_id, prompt_template.format(user_id, messages))
prompts = chats | "Create Prompt" >> beam.ParDo(CreatePrompt())이제 모델을 호출할 준비가 되었습니다. RunInference 기계 덕분에 이 단계는 간단합니다. GemmaModelHandler를 KeyedModelhandler 내에 래핑하여 RunInference가 수신 데이터를 '키-값' 쌍 튜플로 수락하도록 지시합니다. 개발 및 테스트 중에 모델은 gemma2 디렉터리에 저장됩니다. Dataflow ML 서비스에서 모델을 실행할 때 모델은 URI 형식 gs://<your_bucket>/gemma-directory로 Google Cloud Storage에 저장됩니다.
keyed_model_handler = KeyedModelHandler(GemmaModelHandler('gemma2'))
results = prompts | "RunInference-Gemma" >> RunInference(keyed_model_handler)이제는 결과 컬렉션에 LLM 호출 결과가 포함됩니다. 여기서부터 조금씩 흥미로워집니다. LLM 호출은 코드이지만 다른 함수 호출과는 달리 그 결과가 확정적이지 않습니다! 여기에는 "[sentiment, summary] 필드를 사용하여 결과를 JSON으로 출력"이라는 프롬프트 요청의 마지막 비트가 포함됩니다. 응답은 전반적으로 이 형식과 일치하지만 반드시 그것이 보장되지는 않습니다. 여기서는 조금 방어적인 자세를 취하면서 입력 데이터의 유효성을 입증해야 합니다. 유효성 입증에 실패하면 결과를 오류 컬렉션으로 출력합니다. 이 샘플에서는 해당 값을 그대로 둡니다. 프로덕션 파이프라인의 경우, LLM이 다시 한번 시도하고 RunInference에서 오류 컬렉션 결과를 다시 실행한 다음 결과 컬렉션으로 응답을 평탄화하도록 할 수 있습니다. Beam 파이프라인은 방향성 비순환 그래프이므로 여기에서는 루프를 만들 수 없습니다.
이제 결과 컬렉션을 받아 LLM 출력을 처리합니다. RunInference의 결과를 처리하기 위해 새 DoFn SentimentAnalysis와 함수 extract_model_reply를 만듭니다. 이 단계는 PredictionResult 유형의 객체를 반환합니다.
def extract_model_reply(model_inference):
match = re.search(r"(\{[\s\S]*?\})", model_inference)
json_str = match.group(1)
result = json.loads(json_str)
if all(key in result for key in ['sentiment', 'summary']):
return result
raise Exception('Malformed model reply')class SentimentAnalysis(beam.DoFn):
def process(self, element):
key = element[0]
match = re.search(r"@@@([\s\S]*?)@@@", element[1].example)
chats = match.group(1)
try:
# 결과에는 프롬프트가 포함되며 프롬프트를 다음으로 바꿉니다. ""
result = extract_model_reply(element[1].inference.replace(element[1].example, ""))
processed_result = (key, chats, result['sentiment'], result['summary'])
if (result['sentiment'] <0):
output = beam.TaggedOutput('negative', processed_result)
else:
output = beam.TaggedOutput('main', processed_result)
except Exception as err:
print("ERROR!" + str(err))
output = beam.TaggedOutput('error', element)
yield outputextract_model_reply()의 필요성에 대해 잠시 잘 살펴볼 필요가 있습니다. 모델이 자체적으로 호스팅되므로 텍스트가 JSON 출력이 될 것이라고 보장할 수 없기에 JSON 출력을 얻기 위해서는 몇 가지 검사를 실행해야 합니다. Gemini API를 사용할 때의 한 가지 이점은 출력이 항상 JSON임을 보장하는 기능이 포함되는데, 이 기능은 제한된 디코딩으로 알려져 있습니다.
이제 파이프라인에서 다음 함수를 사용하겠습니다.
filtered_results = (results | "Process Results" >> beam.ParDo(SentimentAnalysis()).with_outputs('main','negative','error'))with_outputs를 사용하면 filtered_results에 액세스 가능한 컬렉션이 여러 개 생성됩니다. 기본 컬렉션에는 긍정적이고 중립적인 리뷰에 대한 감정과 요약이 있으며, 오류에는 LLM의 파싱할 수 없는 응답이 포함됩니다. 쓰기 변환으로 이러한 컬렉션을 BigQuery 등 다른 소스로 보낼 수 있습니다. 이 예에서는 이 단계를 설명하지 않습니다. 하지만 저희는 부정적인 컬렉션에 대해 이 파이프라인에서 더 많은 작업을 수행하고자 합니다.
고객 만족도 보장은 고객 유지에 매우 중요합니다. 피자에 파인애플을 넣는 문제와 관련된 논쟁처럼 가벼운 예를 들었지만, 고객과의 직접적인 상호작용 시 항상 조직의 모든 부분에서 공감과 긍정적인 반응을 보일 수 있도록 노력해야 합니다. 이 단계에서는 이런 채팅을 숙련된 지원 담당자에게 전달하지만, 그래도 해당 지원 담당자가 문제 해결 시간을 단축하는 데 LLM이 도움이 되는지는 확인할 수 있습니다.
이 단계에서는 모델을 호출하고 응답을 공식화하도록 요청합니다. 코드에서 이 호출에 Gemma 2B 모델을 다시 사용합니다.
generated_responses = (results.negative
| "Generate Response" >> beam.Map(lambda x: ((x[0], x[3]), "<prompt>Generate an apology response for the user in this chat text: " + x[1] + "<answer>"))
| "Gemma-Response" >> RunInference(keyed_model_handler)일반적으로 프롬프트 생성 코드를 DoFn으로 래핑하지만 파이프라인 코드 자체에 간단한 람다를 사용할 수도 있습니다. 여기에서 SentimentAnalysis 함수에 추출된 원본 채팅 메시지가 포함된 프롬프트를 생성합니다.
로컬 실행과 테스트를 위해 몇 가지 간단한 print 문을 사용하여 다양한 PCollection의 출력을 확인할 수 있습니다.
generated_responses | "Print Response" >> beam.Map(print)
filtered_results.main | "Print Main" >> beam.Map(print)
filtered_results.error | "Print Errors" >> beam.Map(print)물론 실제 사용을 위해 이러한 출력은 Pub/Sub 및 BigQuery와 같은 다양한 싱크로 전송됩니다.
모델이 이전 JSON 메시지와 어떻게 작동하는지 살펴보겠습니다.
1단계: 감정 분석 및 요약
"sentiment": -1,
"summary": "사용자 221이 피자에 올라간 파인애플 토핑에 대해 매우 불만이 많습니다."
2B 모델이 생성한 응답이 나쁘지는 않습니다. 감정이 정확하게 묘사되어 있으며, 요약 결과는 더 주관적이므로 응답의 정확성은 이 정보를 다운스트림에서 어떻게 사용하느냐에 따라 달라집니다.
2단계: 응답 생성
“파인애플 피자가 불만이시군요. 잘 알겠습니다. 매우 개인적인 취향이긴 하지만 그 점으로 인해 불편을 겪으셨다면 죄송합니다. 저희는 다양한 입맛에 맞는 여러 가지 메뉴를 제공하고자 노력하고 있으며, 언제나 고객들이 보내주시는 의견에 열려 있습니다. 파인애플 피자에 대한 생각을 나누고 싶으신지요?"
이러한 응답이 허용 가능할까요? 이 단계에서는 분석을 위해 전체 데이터 패키지를 지원 담당자에게 보낼 계획입니다. 지원 담당자가 이 패키지에 만족할 경우 이대로 보낼 수도 있고 아니라면 일부 내용을 수정 및 조정할 수도 있습니다.
아마도 이 단계에서는 Gemma2 9B 또는 27B처럼 더 많은 매개변수를 갖춘 모델을 사용하고 싶을 것입니다. 또한 작업자에 로드되는 대신 Gemini 같은 외부 서비스 호출에 대한 API 호출이 필요할 정도로 큰 모델을 사용할 수도 있습니다. 결국, 더 작은 모델을 필터로 사용함으로써 이 같은 더 큰 모델로 보내는 데 필요한 작업을 줄였습니다. 이러한 선택은 단순한 기술적 결정이 아니라 비즈니스적 결정이기도 하기에 비용과 편익을 측정해야 합니다. A/B 테스트를 보다 쉽게 설정하기 위해 다시 한번 더 Dataflow를 사용할 수 있습니다.
사용 사례에 맞게 모델 사용자 설정을 미세 조정하는 방법을 선택할 수도 있습니다. 이는 필요에 맞게 모델의 '음성'을 변경하는 한 가지 방법입니다.
생성 단계에서는 수신되는 모든 부정적인 채팅을 2B 모델로 전달했습니다. 컬렉션의 일부를 다른 모델로 보내려면 filtered_responses.negative 컬렉션과 함께 Beam의 Partition 함수를 사용할 수 있습니다. 고객 메시지 일부를 다른 모델로 전달하고 지원 담당자가 생성된 응답을 평가한 후 보내도록 함으로써 응답 품질과 개선 여지에 대한 귀중한 의견을 수집할 수 있습니다.
저희는 이러한 몇 줄의 코드를 사용해 빠른 속도와 변동성으로 고객 감정 데이터를 처리할 수 있는 시스템을 만들었습니다. '규모에 비해 타의 추종을 불허하는 성능'을 갖춘 Gemma 2 개방형 모델을 사용함으로써 더 나은 고객 경험을 창출하는 데 도움이 되는 스트림 처리 사용 사례 내에 이 강력한 LLM을 통합할 수 있었습니다.

Announcing the Data Commons Gemini CLI extension

EmbeddingGemma 출시: 온디바이스 임베딩을 위한 동급 최고의 개방형 모델

Announcing the Agent Development Kit for Go: Build Powerful AI Agents with Your Favorite Languages

Gemma 3 270M 소개: 초효율적인 AI를 위한 콤팩트 모델

Building with Gemini 3 in Jules

Announcing User Simulation in ADK Evaluation