

Large language models (LLMs) like Gemma are powerful and versatile. They can translate languages, write different kinds of text content, and answer your questions in an informative way. However, deploying these LLMs to production, especially for streaming use cases, can be a significant challenge.
This blog post will explore how to use two state-of-the-art tools, vLLM and Dataflow, to efficiently deploy LLMs at scale with minimal code. First, we will lay out how vLLM uses continuous batching to serve LLMs more efficiently. Second, we will describe how Dataflow's model manager makes deploying vLLM and other large model frameworks simple.
vLLM is an open-source library specifically designed for high-throughput and low-latency LLM inference. It optimizes the serving of LLMs by employing several specialized techniques, including continuous batching.
To understand how continuous batching works, let's first look at how models traditionally batch inputs. GPUs excel at parallel processing, where multiple computations are performed simultaneously. Batching allows the GPU to utilize all of its available cores to work on an entire batch of data at once, rather than processing each input individually. This significantly speeds up the inference process; often, performing inference on 8 input records at once uses similar resources as performing inference on a single record.
You can think of batching as being similar to a restaurant kitchen: instead of preparing each dish individually, the chef can group similar orders and cook them together, saving time and resources. If you have 8 stovetops, it takes a similar amount of time and effort to make either a single omelet or 8 omelets.
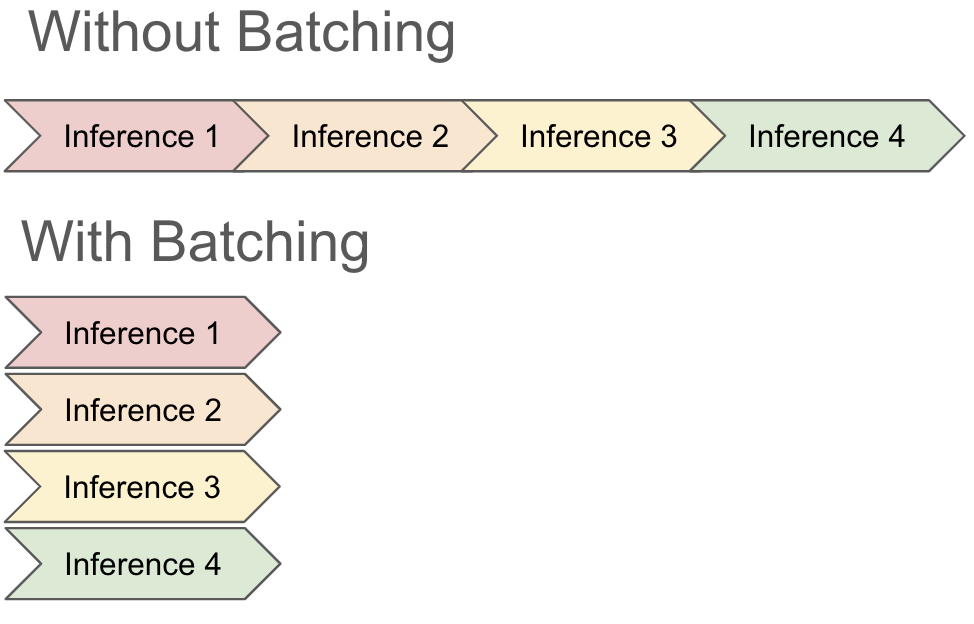
There are some downsides, however, to traditional batching. Most importantly in this context, batching does not work as well when it takes different amounts of time to perform inference. Since most frameworks don't have access to or knowledge about the underlying mechanisms for performing inference, they typically just wait for all requests to complete before taking on a new batch. This means that a single slow record can consume all of a GPUs capacity even if the other records in the batch have completed, leading to slower and more costly jobs.

When running inference with a Large Language Model (LLM), waiting for a whole batch to complete can be prohibitively slow and expensive. This is because the amount of time it takes to generate an inference for a record has a 1:1 correlation to the length of the record. For example, imagine that we batch the following 2 requests to an LLM:
2. What are some of the cultural differences and similarities between Mexico and the United States?
We'd expect a short answer to question (1) and a long answer to question (2). Because it takes much longer to answer question (2), though, we have to wait for that question to complete while it monopolizes our GPU before we can return any of the results from the batch.

Continuous batching allows vLLM to update batches while the request is still running. It achieves this by leveraging how LLMs perform inference: a looping process of repeatedly generating the next token in their response. So really, when generating the sentence "The capital of Mexico is Mexico City", we're running inference 7 times (once per output word). Rather than batching inputs once, vLLM's continuous batching technique allows it to recompute a batch every time the LLM runs generates a set of tokens for a batch. It can add requests to the batch on the fly and return early results when one record from a batch is completely done.

vLLM's dynamic batching and other optimizations have been shown to improve inference throughput by 2-4x for popular LLMs in some cases, making it a very useful tool for model serving. For more information about vLLM, check out this white paper.
Deploying a vLLM instance within a streaming pipeline can be complex. Traditionally, you would need to:
This involves a lot of multiprocessing, which can be time-consuming, error-prone, and requires specialized expertise. It also requires a deep understanding of the underlying topology. This topology can often change if you want to try different machine configurations as well (for example to compare performance on an 8 core machine and a 16 core machine).
Fortunately, Dataflow simplifies this process with its model manager. This feature abstracts away the complexities of managing and deploying models within a pipeline. By default, Dataflow provisions one worker process per available core on its worker machines. These processes are responsible for handling I/O into and out of the worker as well as any transformations which are performed on the data, and they operate entirely independently. For most pipelines, including data prep pipelines for ML use cases, this is the optimal topology.
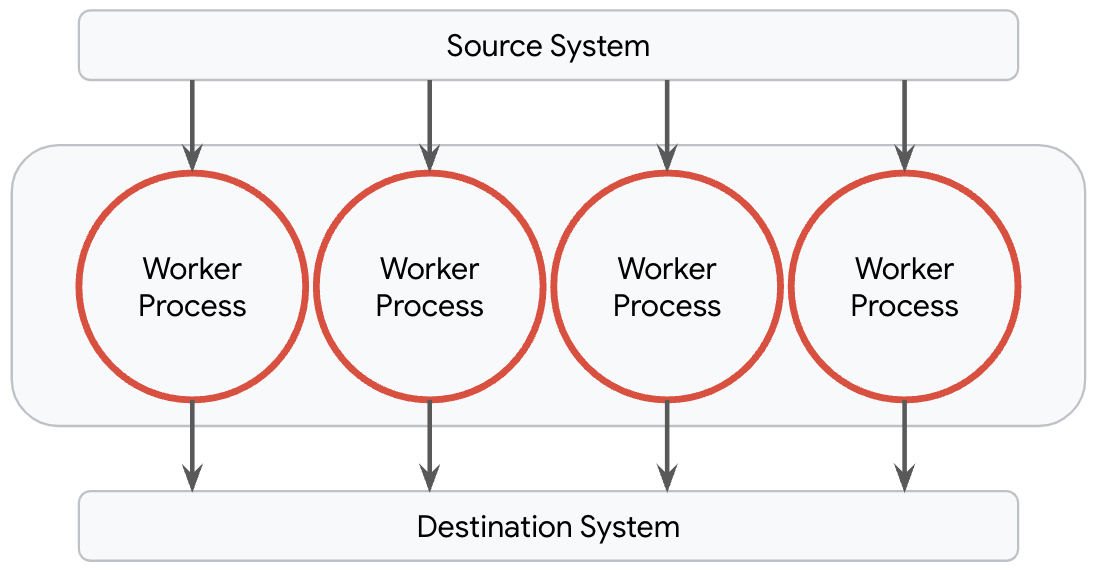
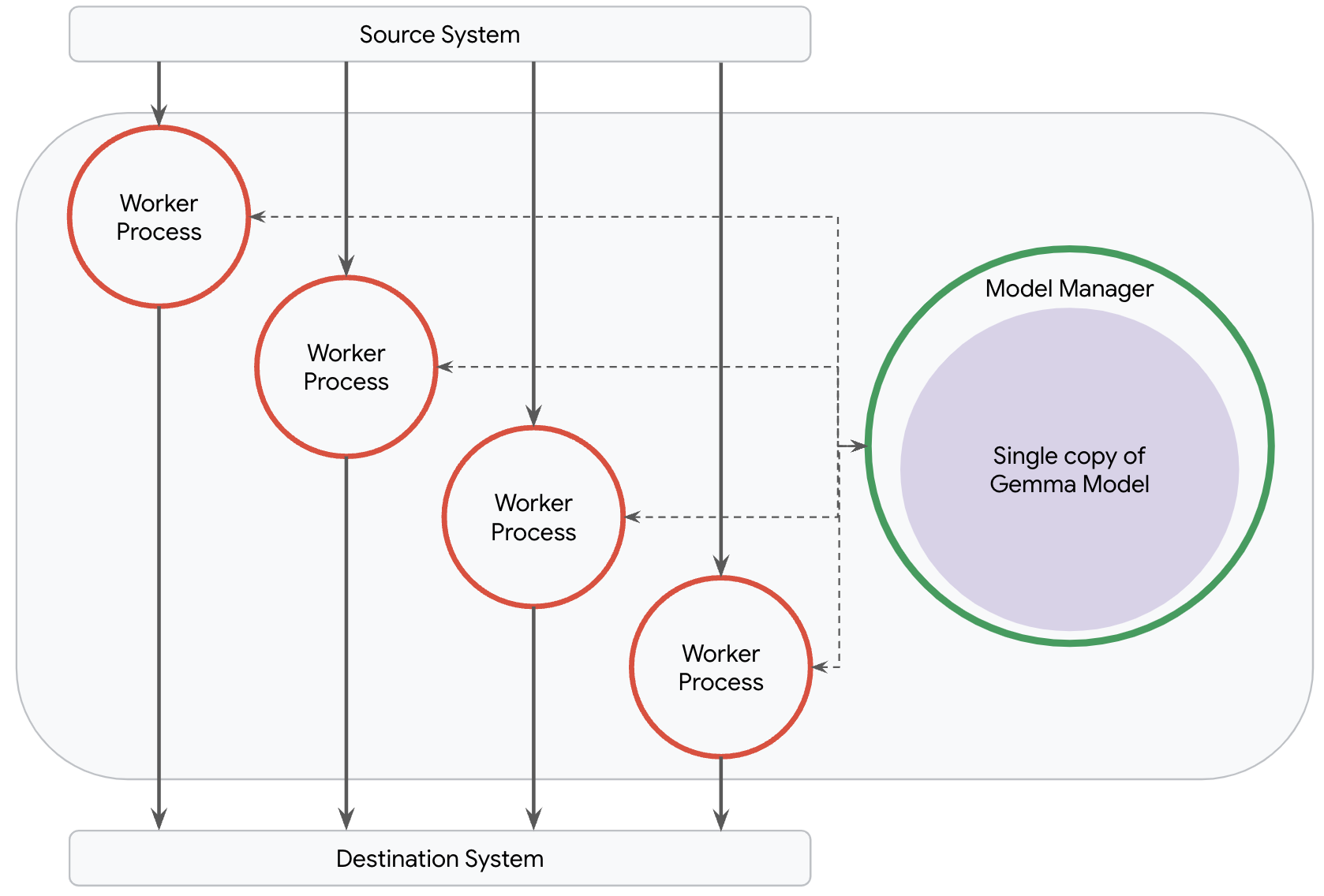
This breaks down, however, for pipelines which need to serve large models like one of the Gemma models. It is neither cost efficient nor performant to load a copy of large models into every process because pipelines will most likely run into out of memory issues. The ideal topology for most such pipelines is to load only a single copy of the large model.
Dataflow's model manager was built to allow users to control the exact number of copies of a model which are deployed in their pipeline, regardless of network topology. When you apply the RunInference transform, Dataflow is able to understand your intent so that it can create the ideal topology for your pipeline and deploy the optimal number of models. All you need to do is supply some configuration parameters.
When using vLLM, instead of loading a model, Dataflow's model manager spins up a single vLLM instance in a dedicated inference process. Worker processes can then efficiently send records to this instance for inference.
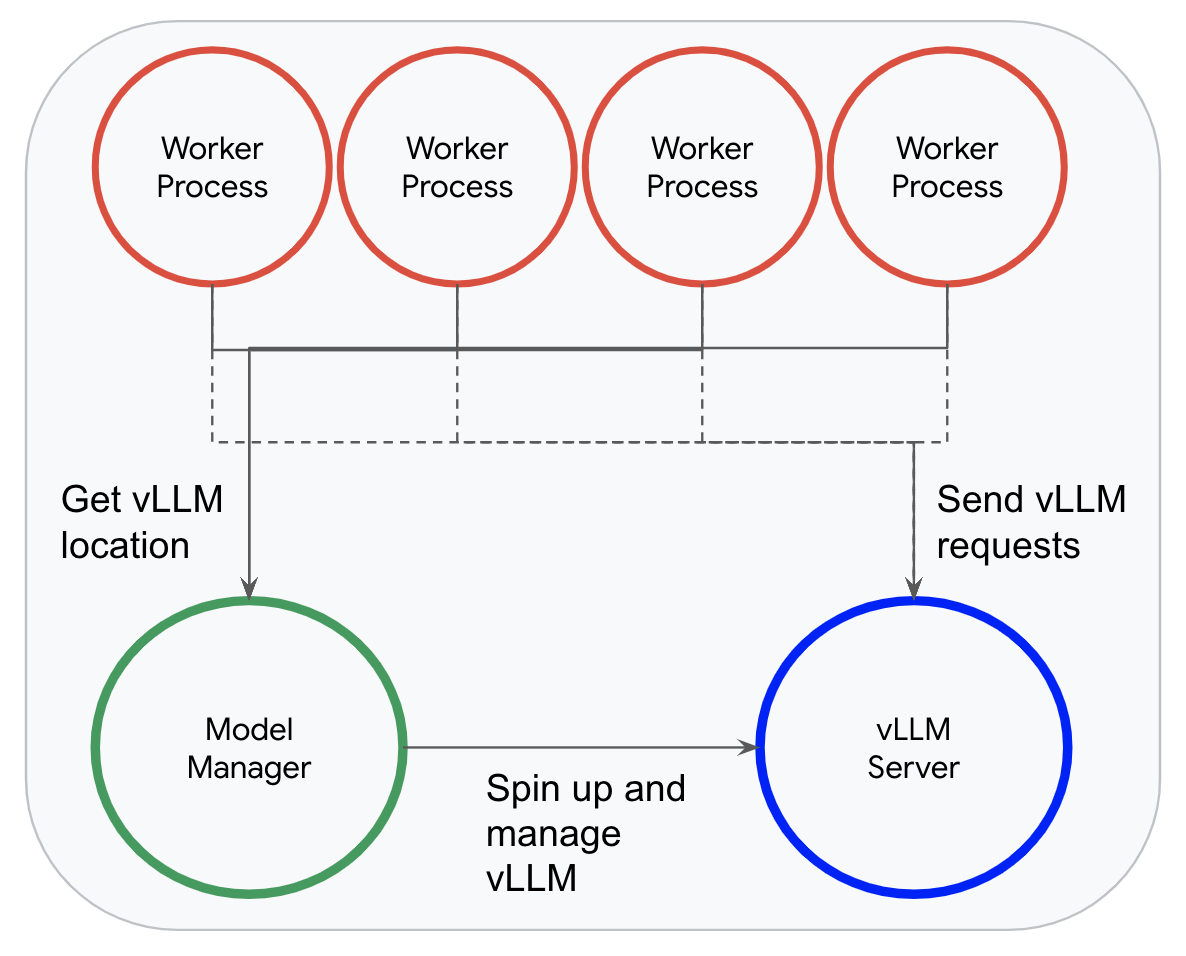
This model manager allows Dataflow to fully take advantage of vLLM's continuous batching; when a worker receives an incoming request, it asynchronously appends it to vLLMs queue of requests and waits for the response, allowing vLLM to dynamically batch as many requests as it is able to.
Dataflow's model manager and RunInference transform make it incredibly easy to incorporate vLLM into your pipeline. You only need to specify some configuration details and a few lines of code. Because Dataflow is able to understand your underlying intent, it configures the whole rest of the pipeline topology for you. In 5 lines of code, you can write a full end to end pipeline to read your data, run it through vLLM, and output it to a sink.
model_handler = VLLMCompletionsModelHandler('google/gemma-2b')
with beam.Pipeline() as p:
_ = (p | beam.ReadFromSource(<config>)
| RunInference(model_handler) # Send the prompts to vLLM and get responses.
| beam.WriteToSink(<config>))You can find a complete pipeline and run it yourself here: https://cloud.google.com/dataflow/docs/notebooks/run_inference_vllm
vLLM significantly boosts the performance of LLM inference in Dataflow pipelines. To compare vLLM's performance against a naive pipeline using fixed size batches, we ran 2 pipelines with a single worker with T4 GPUs. Each pipeline read in prompts from the P3 dataset, ran them against the google/gemma-2b model, and logged the result.
When using a naive (default) batching strategy, it took 59.137 vCPU hours to process 10,000 prompts. When using vLLM with continuous batching, it took only 2.481 vCPU hours to process the same 10,000 prompts. That is an over 23x improvement!
There are some caveats here: specifically, no tuning was done on either pipeline, and the naive pipeline likely would've performed significantly better if tuned to use larger or more uniform batches. With that said, that is part of the magic of vLLM; with less than 20 lines of code and no tuning work, we are able to produce a highly performant LLM serving pipeline! If we wanted to compare another model, we could do so in a performant manner by changing a single string in our model handler!
By combining the power of vLLM and Dataflow, you can efficiently deploy and scale LLMs for your streaming applications with ease. To learn more about how you can do this, try running through this example notebook: https://cloud.google.com/dataflow/docs/notebooks/run_inference_vllm.
To learn more about Gemma models and some of the things you can do with them, check out the Gemma docs: https://ai.google.dev/gemma/docs
To learn more about vLLM and some of the other mechanisms it uses to optimize serving, visit the vLLM docs: https://docs.vllm.ai/en/latest/

Scaling Agentic RL: High-Throughput Agentic Training with Tunix

Run Ray on TPU, Part 2: Ray AI libraries

Introducing EmbeddingGemma: The Best-in-Class Open Model for On-Device Embeddings

Introducing Gemma 3 270M: The compact model for hyper-efficient AI
Run Ray on TPU, Part 1: The foundations