

Gemma 같은 대형 언어 모델(LLM)은 강력하고 용도가 다양합니다. LLM은 언어를 번역하고, 다양한 종류의 텍스트 콘텐츠를 작성하며, 정보를 제공하는 방식으로 질문에 답변할 수 있습니다. 그러나 이러한 LLM을 프로덕션 환경에 배포하는 일은 상당히 어려울 수 있으며, 특히 스트리밍 사용 사례의 경우 더욱 그렇습니다.
이 블로그 게시물에서는 두 가지 최첨단 도구인 vLLM과 Dataflow를 어떻게 사용하여 최소한의 코드로 LLM을 대규모로 효율적으로 배포하는지 살펴보겠습니다. 먼저, vLLM이 LLM을 보다 효율적으로 제공하기 위해 연속 일괄 처리를 사용하는 방법부터 알아봅니다. 다음으로, Dataflow의 모델 관리자가 vLLM 및 기타 대형 모델 프레임워크를 간단하게 배포하는 방법을 설명하겠습니다.
vLLM은 많은 처리량과 짧은 지연 시간 LLM 추론을 위해 특별히 설계된 오픈소스 라이브러리입니다. vLLM은 연속 일괄 처리를 포함한 여러 전문 기법을 사용하여 LLM 제공을 최적화합니다.
연속 일괄 처리의 작동 방식을 이해하기 위해, 먼저 모델이 전통적으로 입력 데이터를 일괄 처리하는 방식을 살펴보겠습니다. GPU는 여러 계산이 동시에 수행되는 병렬 처리에 탁월합니다. 일괄 처리를 사용하면 GPU가 사용 가능한 모든 코어를 활용해서 각 입력 데이터를 개별적으로 처리하는 대신, 전체 데이터 배치에서 한 번에 작업할 수 있습니다. 덕분에 추론 프로세스 속도가 상당히 빨라집니다. 입력 레코드 8개에 대한 추론을 한 번에 수행할 경우 단일 레코드에 대한 추론을 수행하는 것과 유사한 리소스를 주로 사용합니다.
일괄 처리를 식당의 주방에 빗대어 이해할 수 있습니다. 즉, 요리사가 각각의 요리를 따로 준비하는 대신 유사한 주문을 묶어서 함께 요리하면 시간과 자원을 절약할 수 있는 이치와 같습니다. 이런 식으로 요리할 경우, 예컨대 조리대가 8개라면 오믈렛 1인분을 만들든 8인분을 만들든 소요되는 시간과 노력의 양은 유사합니다.
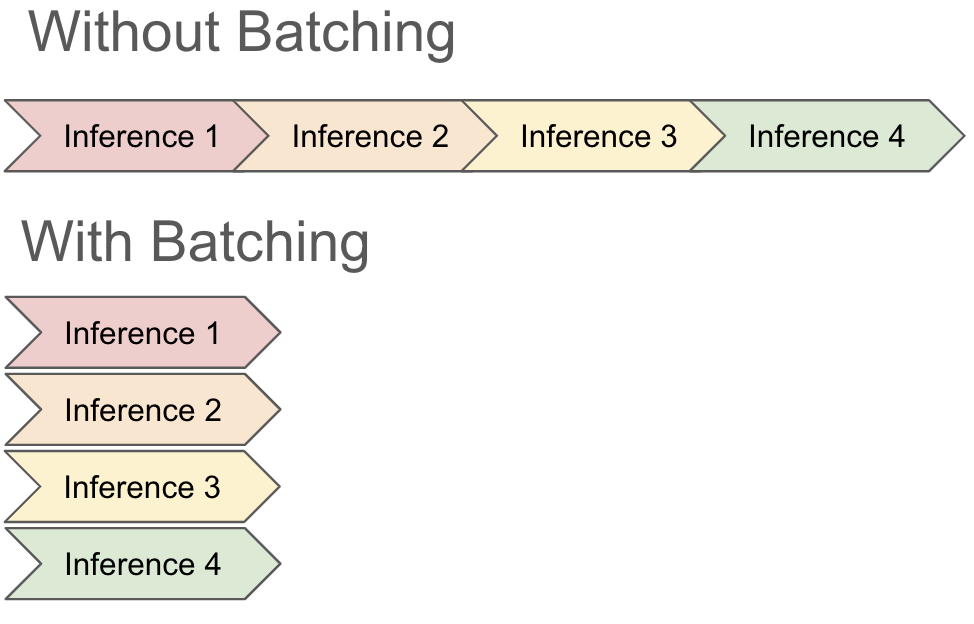
그러나 전통적인 일괄 처리에는 몇 가지 단점이 있습니다. 이 맥락에서 가장 중요한 것은 추론을 수행하는 데 걸리는 시간이 제각기 다른 경우에는 일괄 처리 방식이 잘 작동하지 않는다는 점입니다. 대부분의 프레임워크는 추론을 수행하기 위한 기본 메커니즘에 대한 액세스 권한이나 지식이 없으므로 일반적으로 새 일괄 처리를 수행하기 전에 모든 요청이 완료되기를 기다립니다. 즉, 일괄 처리 작업의 다른 레코드가 모두 완료되었더라도 속도가 느린 단 하나의 레코드가 모든 GPU 용량을 잡아먹는 바람에 속도가 느려지고 작업에 드는 비용이 증가할 수 있습니다.

대형 언어 모델(LLM)로 추론을 실행할 때 전체 일괄 처리 작업이 완료되기를 기다리는 일은 엄청나게 많은 시간과 비용이 들 수 있습니다. 이는 레코드에 대한 추론을 생성하는 데 걸리는 시간이 레코드 길이와 1:1 상관관계가 있기 때문입니다. 예를 들어, LLM에 다음 2가지 요청을 일괄 처리한다고 생각해 보겠습니다.
2. 멕시코와 미국의 문화적 차이점과 유사점은 무엇인가요?
질문 (1)에 대해서는 간단한 답변을, 질문 (2)에 대해서는 상세한 답변을 기대할 것입니다. 하지만 질문 (2)에 답변하는 시간이 훨씬 더 오래 걸리므로 일괄 처리에서 결과를 반환할 때까지 이 요청이 GPU를 독점하고 그동안 질문(2)가 완료되기를 기다려야 합니다.

요청이 계속 실행되는 동안 vLLM은 연속 일괄 처리를 통해 일괄 처리를 업데이트할 수 있습니다. vLLM은 LLM이 추론을 수행하는 방식, 즉 응답에서 다음 토큰을 반복적으로 생성하는 루핑 프로세스를 활용하여 업데이트합니다. 그래서 실제로는 "멕시코의 수도는 멕시코시티입니다"라는 문장을 생성할 때 (출력 단어 당 한 번씩) 총 7회 추론을 실행합니다. 입력을 한 번에 일괄 처리하는 대신, vLLM의 연속 일괄 처리 기법을 사용하면 일괄 처리에 대한 토큰 세트를 생성하도록 LLM이 실행될 때마다 일괄 처리를 다시 계산할 수 있습니다. vLLM은 실행 중에 일괄 처리에 요청을 추가하고 일괄 처리에서 하나의 레코드가 완전히 완료되면 초기 결과를 반환할 수 있습니다.

vLLM의 동적 일괄 처리와 기타 최적화는 경우에 따라 인기 있는 LLM의 추론 처리량을 2~4배 향상시키는 것으로 나타나 vLLM이 모델에 사용하기에 매우 유용한 도구임을 보여주었습니다. vLLM에 대한 자세한 내용은 이 백서를 참조하세요.
스트리밍 파이프라인 내에 vLLM 인스턴스를 배포하는 작업은 복잡할 수 있습니다. 일반적으로 다음을 수행해야 합니다.
이 작업에는 많은 다중 처리가 포함되는데 이는 시간이 오래 걸리고 쉽게 오류가 발생할 수 있으며 전문 지식을 필요로 합니다. 또한 기본 토폴로지에 대한 깊은 이해도 필요합니다. 다른 시스템 구성을 시도하려는 경우에도(예: 8 코어 시스템과 16 코어 시스템에서의 성능 비교) 이 토폴로지는 종종 변경될 수 있습니다.
다행히 Dataflow는 모델 관리자로 이 프로세스를 단순화합니다. 이 기능은 추상화를 통해 파이프라인 내에서 모델을 관리하고 배포하는 복잡성을 줄여줍니다. 기본적으로, Dataflow는 작업자 시스템에서 사용 가능한 코어당 하나의 작업자 프로세스를 프로비저닝합니다. 이러한 프로세스는 데이터에서 수행되는 모든 변환뿐만 아니라 작업자 안팎의 I/O를 처리하는 역할을 하며 완전히 독립적으로 작동합니다. ML 사용 사례에 대한 데이터 준비 파이프라인을 포함한 대다수의 파이프라인에 있어 이것이 최적의 토폴로지입니다.
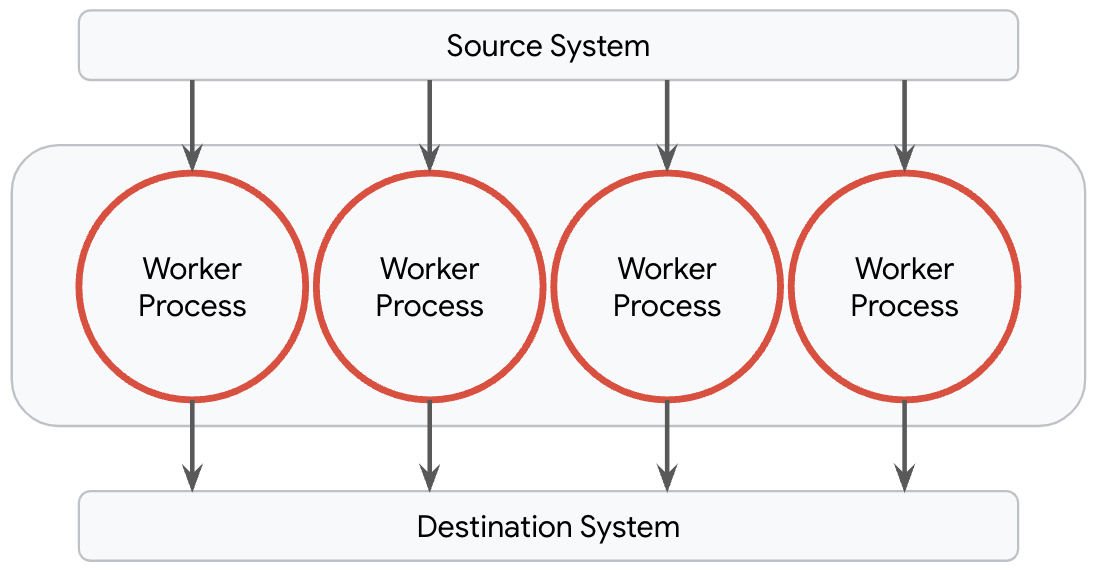
그러나 이 토폴로지는 Gemma 모델 중 하나 같은 대형 모델을 제공해야 하는 파이프라인에는 맞지 않습니다. 대형 모델의 복사본을 모든 프로세스에 로드하는 것은 비용 효율적이지도 않고 성능이 좋지도 않은데, 이는 파이프라인에 메모리 부족 문제가 발생할 가능성이 크기 때문입니다. 이러한 파이프라인 대부분에 이상적인 토폴로지는 대형 모델의 단일 복사본만 로드하는 것입니다.
Dataflow의 모델 관리자는 네트워크 토폴로지에 관계없이 사용자가 파이프라인에 배포되는 모델의 정확한 복사본 수를 제어할 수 있도록 개발되었습니다. RunInference 변환을 적용하면 Dataflow가 인텐트를 이해하여 파이프라인에 이상적인 토폴로지를 만들고 최적 개수의 모델을 배포할 수 있습니다. 몇 가지 구성 매개변수만 제공하면 됩니다.
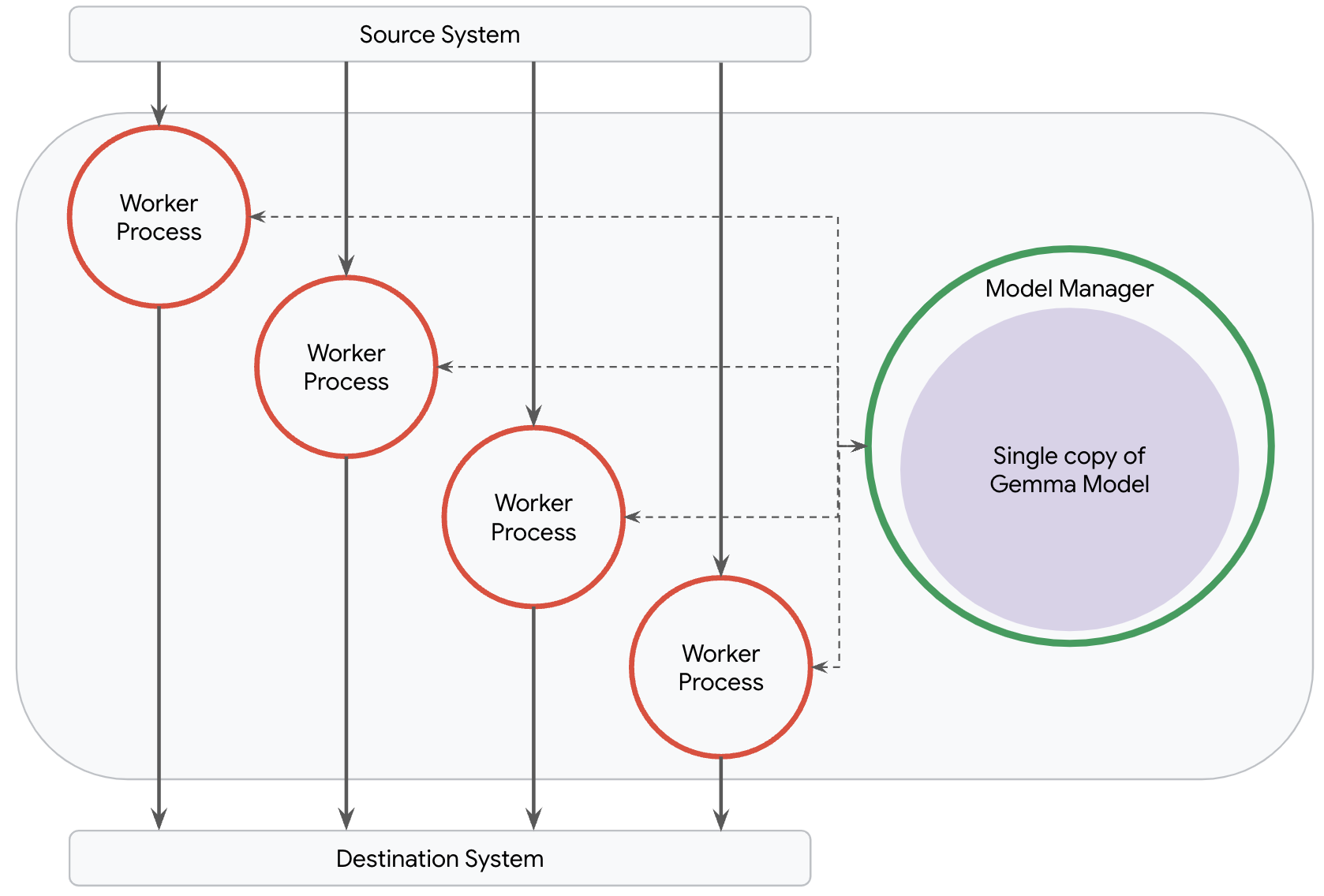
Dataflow의 모델 관리자는 vLLM을 사용할 때 모델을 로드하는 대신 전용 추론 프로세스에서 단일 vLLM 인스턴스를 가동합니다. 그러면 작업자 프로세스에서 추론을 위해 레코드를 이 인스턴스에 효율적으로 보낼 수 있습니다.
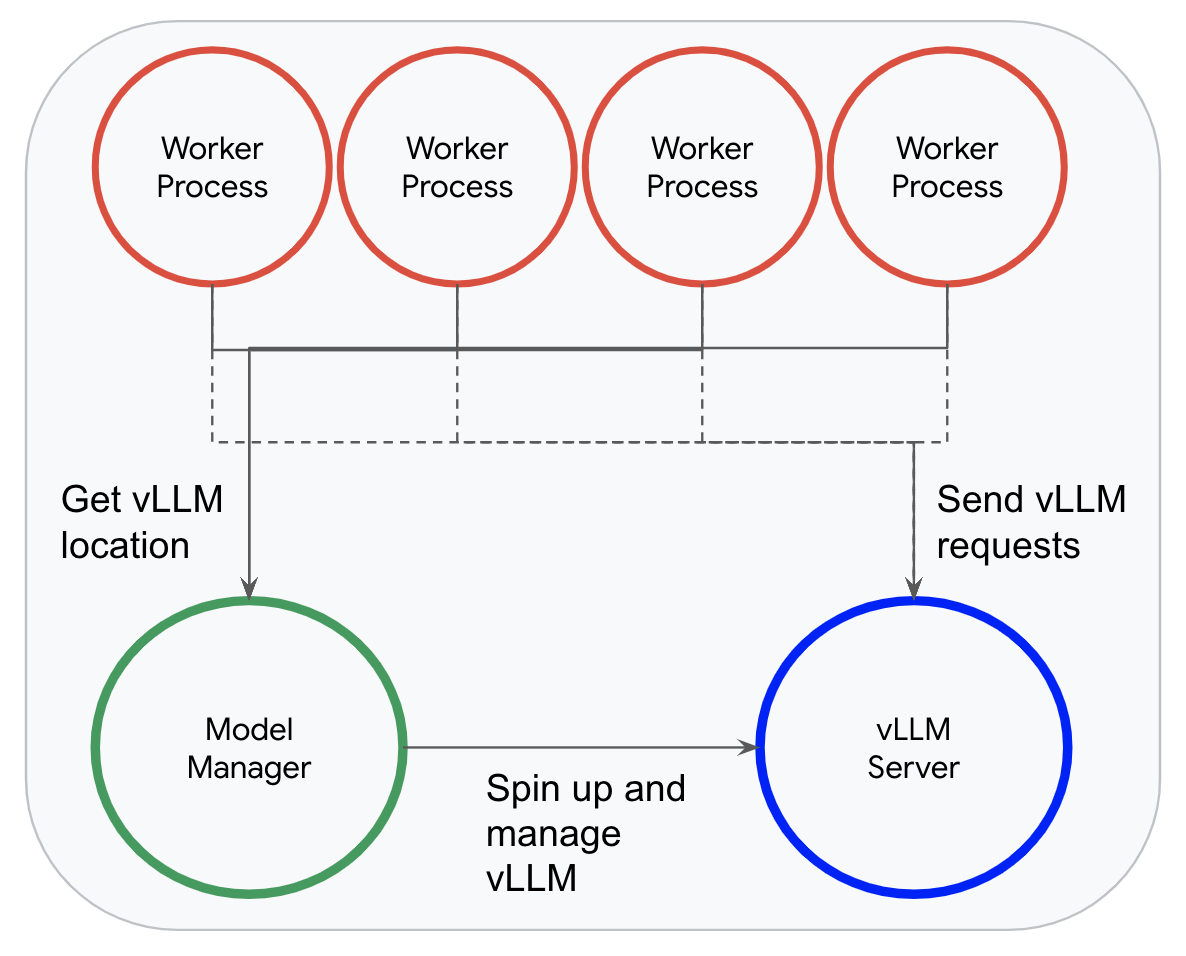
이 모델 관리자는 Dataflow가 vLLM의 연속 일괄 처리를 완전히 활용할 수 있도록 합니다. 작업자가 들어오는 요청을 받으면 vLLM의 요청 큐에 요청을 비동기식으로 추가하고 응답을 기다리므로 vLLM이 가능한 한 많은 요청을 동적으로 일괄 처리할 수 있습니다.
Dataflow의 모델 관리자와 RunInference 변환을 사용하면 vLLM을 파이프라인에 놀랍도록 쉽게 통합할 수 있습니다. 몇 가지 세부적인 구성 사항과 코드 몇 줄만 지정하면 됩니다. Dataflow는 기본적인 인텐트를 이해할 수 있기 때문에 나머지 파이프라인 토폴로지 전체를 구성합니다. 5줄의 코드에서 데이터를 읽을 전체 엔드투엔드 파이프라인을 작성하고 vLLM을 통해 실행하고 싱크에 출력할 수 있습니다.
model_handler = VLLMCompletionsModelHandler('google/gemma-2b')
with beam.Pipeline() as p:
_ = (p | beam.ReadFromSource(<config>)
| RunInference(model_handler) # 프롬프트를 vLLM으로 보내고 응답을 받습니다.
| beam.WriteToSink(<config>))다음 링크에서 전체 파이프라인을 찾아 직접 실행할 수 있습니다. https://cloud.google.com/dataflow/docs/notebooks/run_inference_vllm
vLLM은 Dataflow 파이프라인에서 LLM 추론의 성능을 크게 향상시킵니다. 고정된 크기의 일괄 처리를 사용하는 단순한 파이프라인에 대한 vLLM의 성능을 비교하기 위해 T4 GPU를 사용하는 단일 작업자와 함께 2개의 파이프라인을 실행했습니다. 각 파이프라인은 P3 데이터 세트에서 프롬프트를 읽고 google/gemma-2b 모델에 대해 실행하고 그 결과를 기록했습니다.
단순한 (기본) 일괄 처리 전략을 사용하는 경우 10,000개의 프롬프트를 처리하는 데 59.137 vCPU 시간이 걸렸습니다. 연속 일괄 처리와 함께 vLLM을 사용하는 경우 동일한 프롬프트 10,000개를 처리하는 데 2.481 vCPU 시간이 걸렸습니다. 즉, 성능이 23배 이상 향상되었습니다!
여기에는 몇 가지 주의 사항이 있습니다. 구체적으로 말하자면, 어느 파이프라인에서도 조정이 수행되지 않았으며, 만약 더 크거나 더 균일한 일괄 처리를 사용하도록 조정되었다면 단순한 파이프라인이 훨씬 더 잘 수행되었을 것입니다. 덧붙이자면, 그것이 바로 vLLM의 놀라운 점 중 하나로, 코드가 20줄 미만이고 조정 작업이 없어도 고성능 LLM 서비스를 제공하는 파이프라인 생성이 가능합니다! 다른 모델을 비교하려면 모델 핸들러에서 단일 문자열을 변경하여 성능 기준에 맞는 방식으로 비교할 수도 있습니다!
vLLM과 Dataflow의 강력한 성능을 결합하면 스트리밍 앱을 위한 LLM을 효율적으로 배포하고 손쉽게 확장할 수 있습니다. 수행 방법에 대해 자세히 알아보려면 다음 예제 노트북을 통해 실행해 보세요. https://cloud.google.com/dataflow/docs/notebooks/run_inference_vllm
Gemma 모델과 이 모델로 할 수 있는 몇 가지 작업에 대해 자세히 알아보려면 다음 Gemma 문서를 확인해 보세요. https://ai.google.dev/gemma/docs
vLLM과 서비스 최적화에 사용하는 다른 메커니즘에 대해 자세히 알아보려면 다음 vLLM 문서를 확인해 보세요. https://docs.vllm.ai/en/latest/

Announcing the Data Commons Gemini CLI extension

EmbeddingGemma 출시: 온디바이스 임베딩을 위한 동급 최고의 개방형 모델

Announcing the Agent Development Kit for Go: Build Powerful AI Agents with Your Favorite Languages

Gemma 3 270M 소개: 초효율적인 AI를 위한 콤팩트 모델

Building with Gemini 3 in Jules

Announcing User Simulation in ADK Evaluation