

Gemma のような大規模言語モデル(LLM)は強力かつ柔軟です。こういった LLM は、言語を翻訳したり、さまざまな種類のテキスト コンテンツを書いたり、質問に対して有益な回答を提示したりします。しかし、特にストリーミングのユースケースでは、本番環境へのデプロイが非常に難しい場合があります。
このブログ投稿では、vLLM と Dataflow という 2 つの最先端ツールを使い、最小限のコードで大規模かつ効率的に LLM をデプロイする方法について説明します。最初は連続バッチ処理を使って LLM の提供を効率化する vLLM について、続いて vLLM やその他の大規模モデル フレームワークのデプロイを簡単にする Dataflow のモデル マネージャーについて説明します。
vLLM はオープンソース ライブラリであり、高スループットで低遅延な LLM 推論を実現するために特別に設計されています。連続バッチ処理などの特殊な手法が採用されているので、LLM を最適な形で提供することができます。
連続バッチ処理の動作を理解するため、まず従来の方法でモデルが入力をバッチ処理する仕組みを確認してみましょう。GPU は、複数の計算を同時に実行する並列処理に優れています。バッチ処理では、GPU が各入力を個別に処理するのではなく、利用できるすべてのコアを利用してデータのバッチ全体を一度に処理します。そのため、推論プロセスが大幅に高速になります。多くの場合、8 つの入力レコードをまとめて推論しても、使うリソースは 1 つのレコードで推論を実行するのと同等です。
バッチ処理はレストランの厨房のようなものだと考えることができます。シェフがそれぞれの料理を個別に準備するのではなく、似たような注文をまとめて一緒に調理することで、時間とリソースを節約できます。コンロが 8 つある場合、1 つのオムレツを作っても 8 つのオムレツを作っても、かかる時間と労力は同じくらいです。
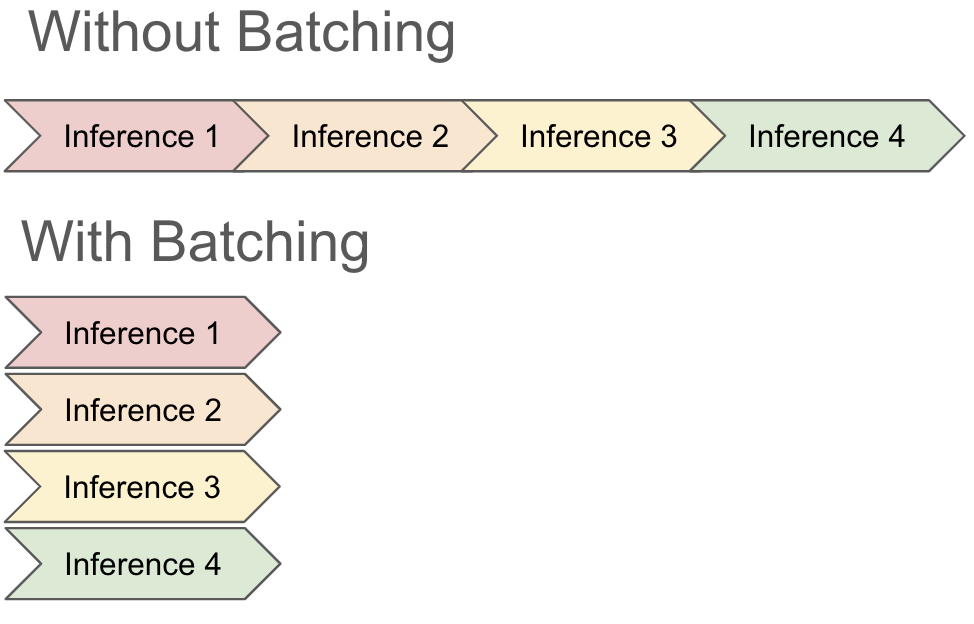
しかし、従来のバッチ処理にはいくつかの欠点があります。この状況で最も重要なのは、推論にかかる時間が異なる場合、バッチ処理がうまく動作しないことです。ほとんどのフレームワークは、推論の土台となるメカニズムにはアクセスできず、それに関する知識も持っていないため、通常はすべてのリクエストが終わるのを待ってから、新しいバッチを開始するしかありません。つまり、1 つでも遅いレコードがあると、バッチの他のレコードが完了していても、GPU 容量がすべて消費され続ける可能性があります。そのため、ジョブの時間とコストが増大します。

大規模言語モデル(LLM)の推論では、バッチ全体の完了を待つと、時間とコストがかかりすぎる場合があります。これは、レコードの推論時間とレコード長には、1 対 1 の相関関係があるためです。たとえば、LLM で次の 2 つのリクエストをバッチ処理するとします。
2. メキシコと米国の文化には、どのような違いや類似点がありますか?
質問(1)には短い回答が、質問(2)には長い回答が想定されます。ただし、質問(2)の回答には時間がかかるため、この質問が完了するまで GPU が独占され続け、バッチの結果が返ることはありません。

vLLM で連続バッチ処理を使うと、リクエストの実行中でもバッチを更新できます。これは、LLM の推論の仕組みをうまく活用することによって実現しています。LLM の推論は、回答の次のトークンを生成する操作を繰り返すループ処理によって行います。実際には、「The capital of Mexico is Mexico City」(メキシコの首都はメキシコシティです)という文を生成するときには、推論を 7 回実行しています(出力単語ごとに 1 回)。vLLM の連続バッチ処理手法を使うと、入力を一度にバッチ処理するのではなく、LLM を実行するたびにバッチを再計算し、バッチのトークンセットを生成することができます。こうすることで、リクエストをその場でバッチに追加し、レコードの処理が終わった時点で結果を返すことができます。

一般的な LLM では、vLLM の動的バッチ処理などの最適化によって、推論のスループットが 2~4 倍に向上する場合があることが示されています。そのため、これはモデルを提供するうえで非常に有用なツールだと言うことができます。vLLM の詳細については、こちらのホワイト ペーパーをご覧ください。
ストリーミング パイプラインに vLLM インスタンスをデプロイするのは、複雑な作業になる場合があります。これまでは、次のことを行う必要がありました。
これには多くのマルチプロセッシングが必要で、時間がかかり、エラーが発生しやすく、専門知識が必要になる可能性があります。また、ベースとなるトポロジを深く理解する必要もあります。異なるマシン設定も試したい場合、このトポロジが頻繁に変更される可能性があります(たとえば、8 コアマシンと 16 コアマシンのパフォーマンスを比較したい場合など)。
うれしいことに、Dataflow はモデル マネージャーを使ってこのプロセスを簡単にしています。この機能を使えば、パイプラインのモデルの管理やデプロイといった複雑な作業は不要になります。デフォルトで Dataflow は、ワーカーマシンで利用できるコアごとに 1 つのワーカー プロセスをプロビジョニングします。このプロセスは完全に独立して動作し、ワーカーの I/O やデータの変換を行います。このトポロジは、ML ユースケースのデータ準備パイプラインなど、ほとんどのパイプラインに最適です。
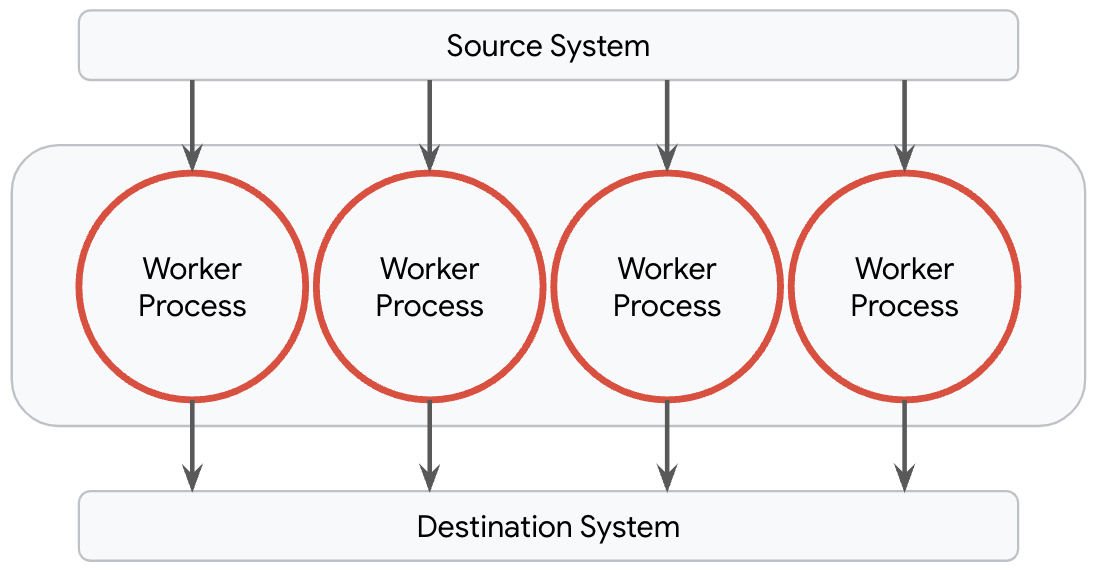
ただし、Gemma モデルのような大規模モデルを提供するパイプラインでは、この仕組みはうまくいきません。すべてのプロセスが大規模モデルを読み込むと、パイプラインでメモリ不足の問題が起きる可能性が高まるので、コスト効率もパフォーマンスもよくありません。ほとんどのパイプラインでは、大規模モデルを 1 つだけ読み込むトポロジの方が理想的です。
Dataflow のモデル マネージャーは、ネットワーク トポロジに関係なく、パイプラインにデプロイされているモデルの正確なコピーの数をユーザーがコントロールできるように作られています。RunInference 変換を適用すると、Dataflow は皆さんの意図を理解し、パイプラインにとって理想的なトポロジを作成し、最適な数のモデルをデプロイできるようにします。必要なのは、いくつかの設定パラメータを指定することだけです。
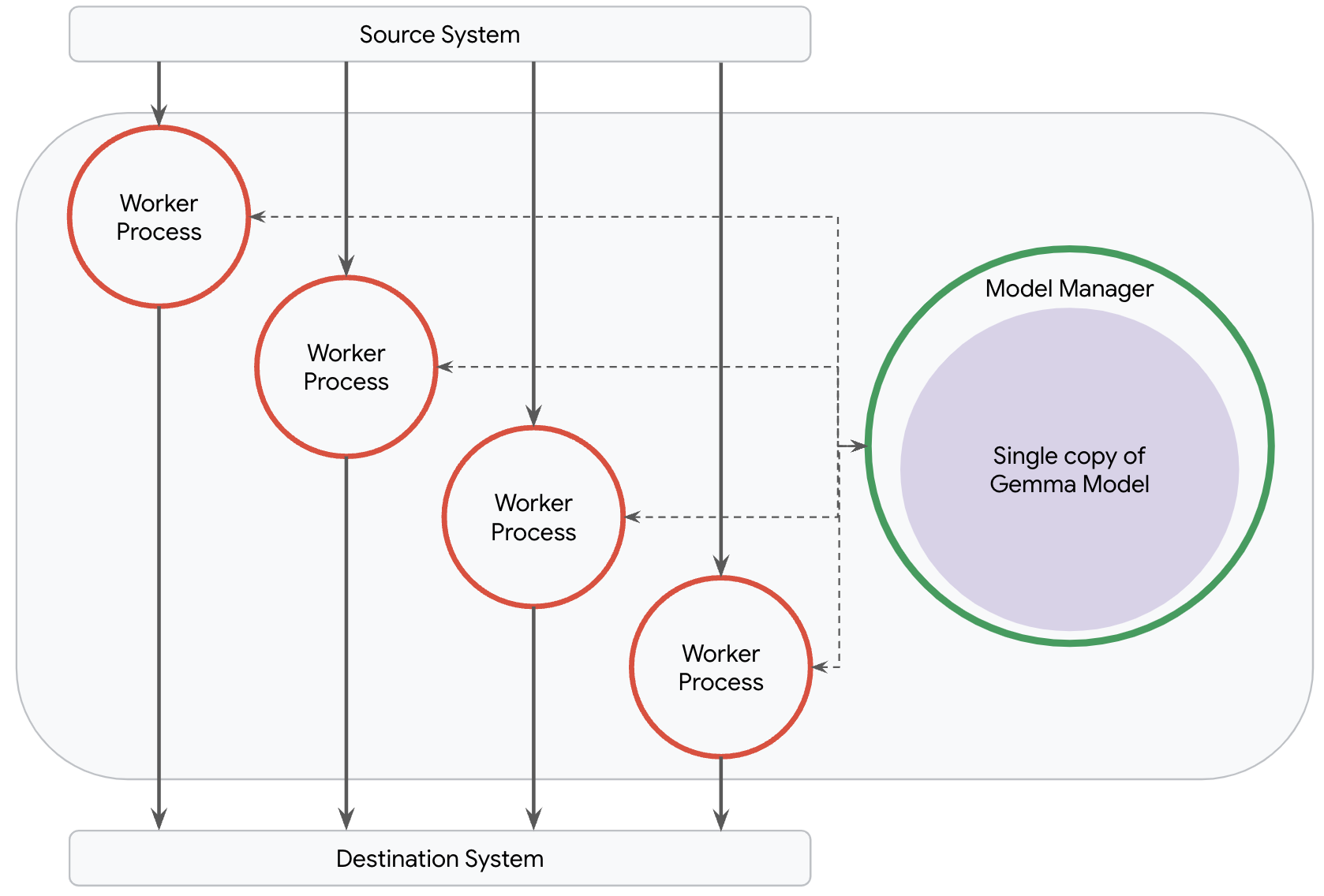
vLLM を使う場合、モデルを読み込むのではなく、Dataflow のモデル マネージャーが専用の推論プロセスで 1 つだけ vLLM インスタンスを起動します。そのため、ワーカー プロセスはこのインスタンスにレコードを効率的に送信し、推論を行うことができます。
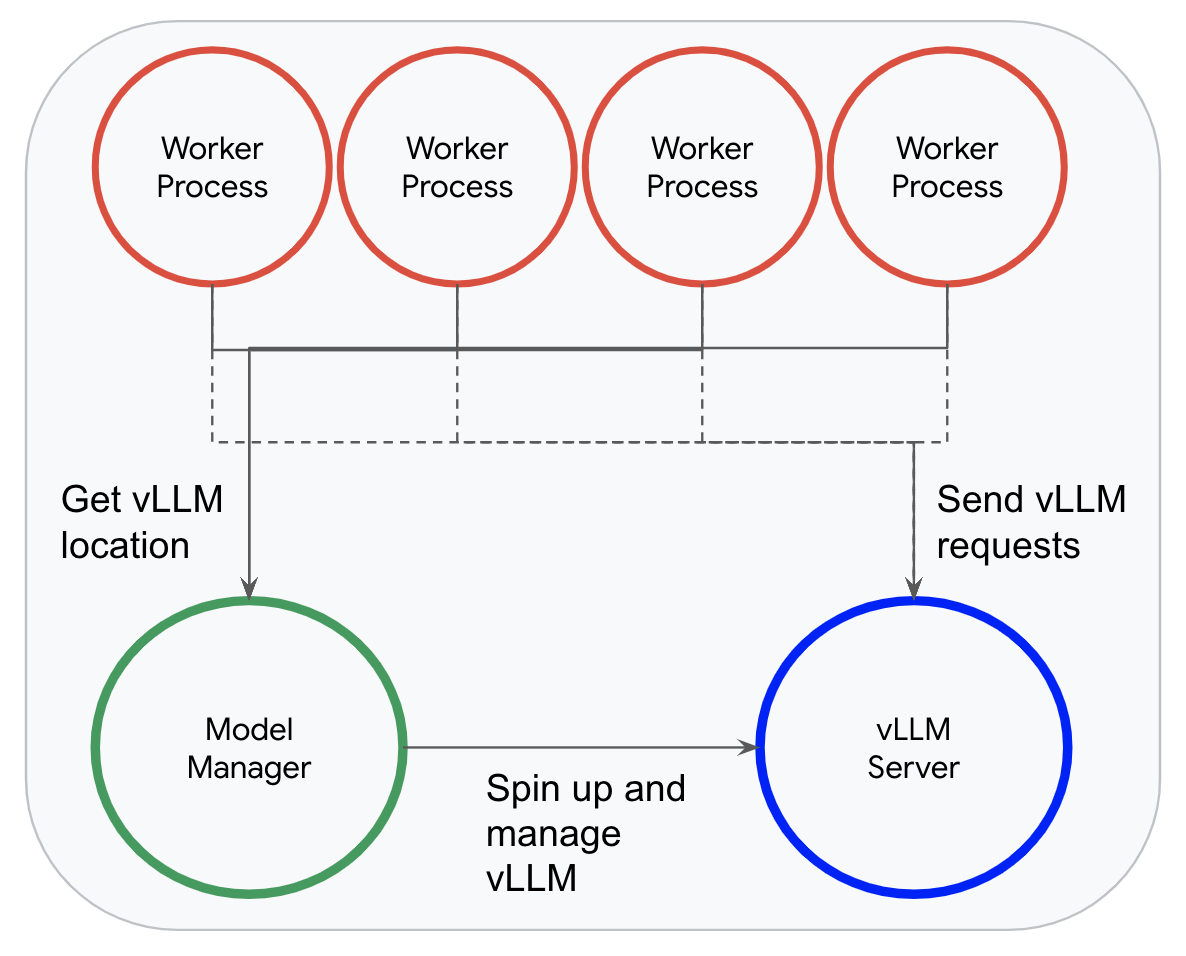
このモデル マネージャーのおかげで、Dataflow が vLLM の連続バッチ処理をフル活用できるようになります。ワーカーは、受信したリクエストを非同期的に vLLM のリクエスト キューに追加し、レスポンスを待ちます。vLLM ができる限り多くのリクエストを動的にバッチ処理できるのは、この仕組みのためです。
Dataflow のモデル マネージャーと RunInference 変換のおかげで、驚くほど簡単に vLLM をパイプラインに組み込むことができます。必要なのは、いくつかの細かい設定と数行のコードを指定することだけです。Dataflow は皆さんの基本的な意図を理解できるので、残りのパイプライン トポロジ全体を設定してくれます。5 行のコードだけで、データを読み取り、vLLM で実行し、シンクに出力するという完全なエンドツーエンドのパイプラインを記述できます。
model_handler = VLLMCompletionsModelHandler('google/gemma-2b')
with beam.Pipeline() as p:
_ = (p | beam.ReadFromSource(<config>)
| RunInference(model_handler) # Send the prompts to vLLM and get responses.
| beam.WriteToSink(<config>))実際に実行できる完全なパイプラインは、こちらにあります。https://cloud.google.com/dataflow/docs/notebooks/run_inference_vllm
vLLM によって、Dataflow パイプラインの LLM 推論パフォーマンスが大幅に向上します。vLLM のパフォーマンスと、固定サイズのバッチを使う単純なパイプラインのパフォーマンスを比較するため、T4 GPU で、1 つのワーカーがあるパイプラインを 2 つ実行してみました。各パイプラインでは、P3 データセットからプロンプトを読み取り、google/gemma-2b モデルを実行し、結果を記録しました。
単純な(デフォルトの)バッチ戦略を使った場合、10,000 個のプロンプトの処理に 59.137 vCPU 時間かかりました。vLLM で連続バッチ処理を行う場合は、同じ 10,000 個のプロンプトの処理に 2.481 vCPU 時間しかかかりませんでした。これは 23 倍以上の改善です!
ここには、いくつかの注意点があります。具体的には、どちらのパイプラインもチューニングを行っていません。単純なパイプラインでも、バッチのサイズを大きくする、バッチを均一化するといったチューニングを行うことで、パフォーマンスが大幅に向上する可能性があります。とはいえ、チューニング作業なしで、20 行未満のコードで高パフォーマンスな LLM サービス パイプラインを作成できるのは、vLLM の魔法の一端です。別のモデルで比較してみたい場合は、モデルハンドラの文字列を 1 つ変更することで、効率的に比較できます!
vLLM と Dataflow の力を組み合わせることで、ストリーミング アプリケーションの LLM を簡単かつ効率的にデプロイして拡張することができます。詳しい方法を知りたい方は、こちらのサンプル ノートブック https://cloud.google.com/dataflow/docs/notebooks/run_inference_vllm をお試しください。
Gemma モデルの詳細やそれを使ってできることについては、Gemma のドキュメント https://ai.google.dev/gemma/docs をご覧ください。
vLLM など、モデルを最適な形で提供するメカニズムの詳細については、vLLM のドキュメント https://docs.vllm.ai/en/latest/ をご覧ください。

Announcing User Simulation in ADK Evaluation

EmbeddingGemma の概要: オンデバイス埋め込み処理向けの最高水準オープンモデル

Building with Gemini 3 in Jules

Gemma 3 270M の概要: 超高効率 AI のためのコンパクト モデル

Announcing the Data Commons Gemini CLI extension

Announcing the Agent Development Kit for Go: Build Powerful AI Agents with Your Favorite Languages