

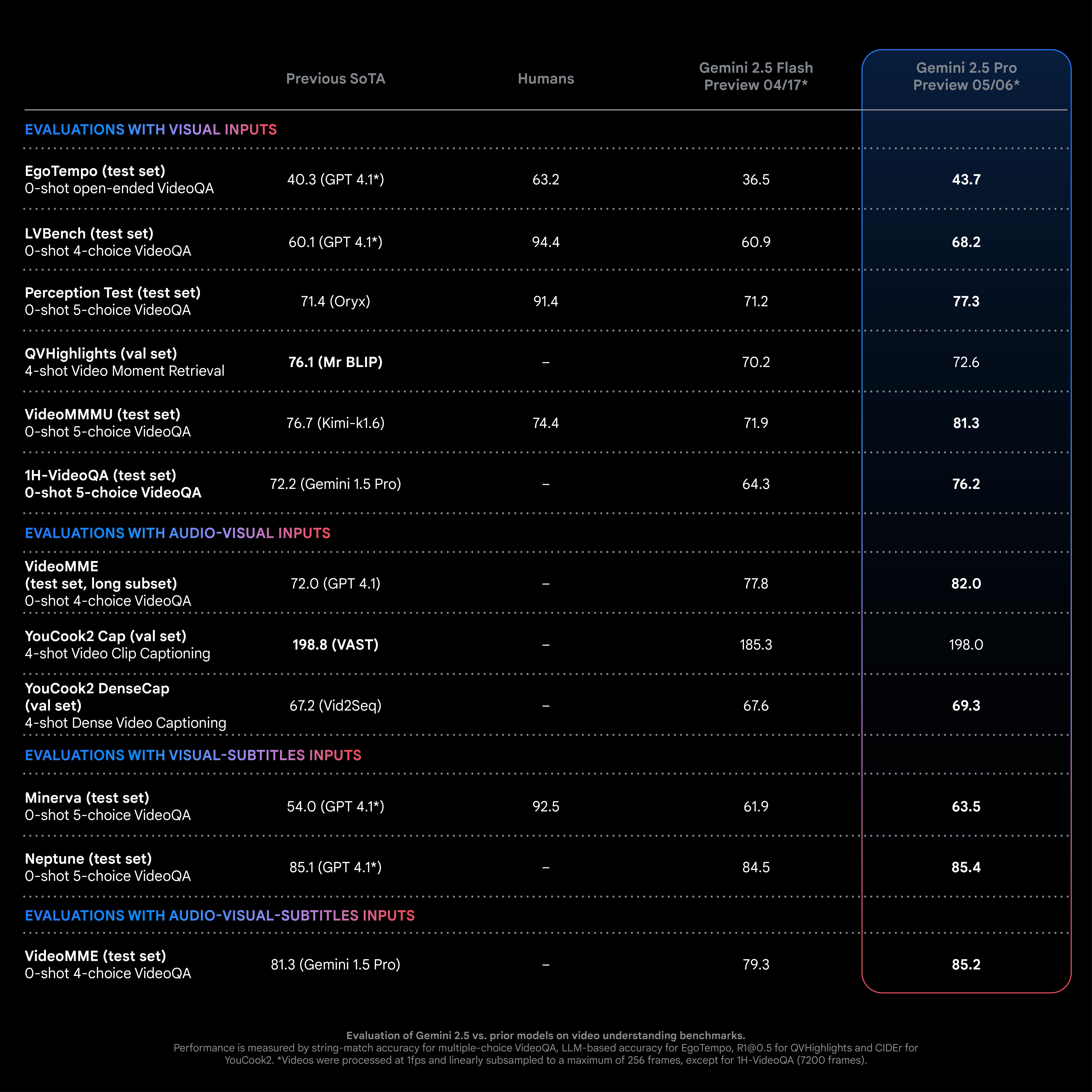
We recently launched two new models in our Gemini family: Gemini 2.5 Pro Preview (05/06) and Gemini 2.5 Flash (04/17). These models mark a major leap in video understanding. Gemini 2.5 Pro achieves state-of-the-art performance on key video understanding benchmarks, surpassing recent models like GPT 4.1 under comparable testing conditions (same prompt and video frames).
Furthermore, it rivals specialized fine-tuned models on several challenging benchmarks (e.g. YouCook2 dense captioning and QVHighlights moment retrieval). For cost-sensitive applications, Gemini 2.5 Flash provides a highly competitive alternative.
Gemini 2.5 is the first time a natively multimodal model can use audio-visual information seamlessly with code and other data formats. To illustrate the power of Gemini 2.5's video understanding capabilities, we showcase some of the use cases that we’ve been most excited about below.
Gemini 2.5 Pro unlocks new possibilities for transforming videos into interactive applications. Video To Learning App, a Google AI Studio starter app, uses Gemini 2.5 to make learning from video content more effective and engaging.
First, the model sees a YouTube URL along with a text prompt that explains how it should analyze the video. Gemini 2.5 Pro analyzes the video and crafts a detailed spec for a learning application which reinforces key ideas in the video.
The generated spec is then sent directly back to Gemini 2.5 Pro to generate the code for the application, as illustrated in the vision correction simulator application below. Gemini 2.5 Flash can achieve similar results, offering a glimpse into novel video use cases in domains such as education and interactive content creation.
Gemini 2.5 Pro unlocks exciting creative possibilities, such as the ability to generate dynamic animations from videos with a single prompt. This capability opens up new avenues for use cases such as automated content generation and creating accessible video summaries.
For example, when given our video on Project Astra along with the prompt 'Create an animation in p5.js covering the different landmarks seen in this video.', Gemini 2.5 Pro analyzes the footage and produces a corresponding p5.js animation. The animation visualizes the landmarks identified by Gemini 2.5 Pro in the same temporal order as in the video.
Gemini 2.5 Pro excels at identifying specific moments within videos using audio-visual cues with significantly higher accuracy than previous video processing systems. For example, in this 10-minute video of the Google Cloud Next '25 opening keynote, it accurately identifies 16 distinct segments related to product presentations, using both audio and visual cues from the video to do so.
With its advanced moment retrieval capabilities, Gemini 2.5 Pro is also able to solve nuanced temporal reasoning problems such as counting. In this example, Gemini successfully counts 17 distinct occurrences where the main character uses their phone in the project Astra video.
Video understanding in Gemini 2.5 Flash and Pro are available in Google AI Studio, the Gemini API, and Vertex AI. Support for YouTube videos is available via the Gemini API and Google AI Studio, enabling anyone to build applications with access to billions of videos.
The Gemini API now offers a 'low' media resolution parameter enabling Gemini 2.5 Pro to process ~6 hours of video with 2 million token context. This provides for a more cost-effective setting with competitive video understanding performance (e.g., 84.7% vs 85.2% accuracy on VideoMME) for many long video understanding use cases.
We are inspired by the innovative video applications already emerging from the community and can’t wait to see what you build!
A big shoutout to Aaron Wade for creating Video To Learning App and for the Vision Correction simulator example showcased in the blogpost.
We thank Sergi Caelles, Boyu Wang and Saarthak Khanna for their contributions on the evaluations presented above, Angeliki Lazaridou for inspiring some demo examples, and the entire Gemini video understanding team for the work culminating in this release. Finally, we would like to thank the video understanding leads Mario Lučić, Shuo-yiin Chang, and Paul Natsev, and overall multimodal understanding lead Jean-Baptiste Alayrac.

Build Long-running AI agents that pause, resume, and never lose context with ADK

Accelerating on-device AI: A look at Arm and Google AI Edge optimization

Turn creative prompts into interactive XR experiences with Gemini

Announcing Genkit Middleware: Intercept, extend, and harden your agentic apps

How we built the Google I/O 2026 Save the Date experience