
생성형 AI(gen AI) 채택률이 빠르게 늘고 있지만, 비공개 및 기밀 유지 보장에 대한 요구 수준이 더 높은 데이터에 gen AI를 적용하여 제품을 개발할 수 있는 잠재력은 여전히 거의 미개척 상태로 남아 있습니다.
예를 들어, 이는 다음과 같은 것에 gen AI를 적용하는 것을 의미할 수 있습니다.
이와 같은 특정 응용 분야에서는 개인 정보 보호/기밀 유지, 투명성, 데이터 처리의 외부 검증 가능성과 관련한 요구 사항이 높아질 수 있습니다.
Google은 더욱 철저하게 비공개 상태를 유지해야 하는 데이터를 처리하기 위해 gen AI의 잠재력을 실험하고 탐색하는 데 사용할 수 있는 다양한 기술을 개발했습니다. 이 게시물에서는 최근에 출시된 GenC 오픈소스 프로젝트를 사용하여 컨피덴셜 컴퓨팅, Gemma 오픈소스 모델, 모바일 플랫폼을 함께 결합하여 개인 정보 보호/기밀성, 투명성, 외부 검증 가능성에 관한 요구 수준이 높아진 데이터를 처리할 수 있는 자체 gen AI 기반 앱을 개발하며 다양한 실험을 시작하는 방법을 설명하겠습니다.
아래 그림과 같이 이 게시물에서 중점적으로 다룰 시나리오에는 기기의 데이터에 액세스할 수 있고 LLM을 사용하여 이 데이터에 대해 gen AI 처리를 수행하려는 모바일 앱이 등장합니다.
예를 들어, 기기에 저장된 메모, 문서 또는 녹음에 대한 질문을 요약하거나 질문에 답하도록 되어 있는 개인 비서 앱을 상상해 보세요. 콘텐츠에 다른 사람과 주고받은 메시지와 같은 개인 정보가 포함될 수 있으므로 비공개로 유지하고자 합니다.
이 예에서는 오픈소스 모델의 Gemma 제품군을 선택했습니다. 여기서는 모바일 앱에 초점을 맞추지만, 온프레미스에서 자체 데이터를 호스팅하는 기업에도 동일한 원칙이 적용됩니다.
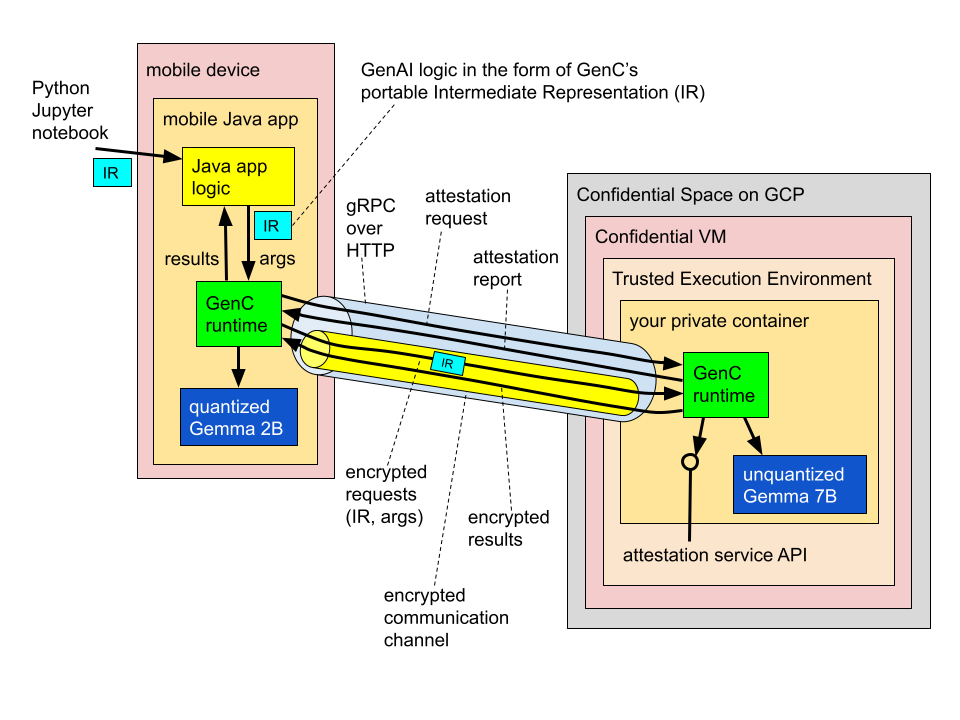
이 예에서는 두 개의 LLM을 포함하는 '하이브리드' 설정을 보여주는데, 한 LLM은 사용자 기기에서 로컬로 실행되고 다른 LLM은 컨피덴셜 컴퓨팅으로 구동되는 Google Cloud의 Confidential Space TEE(신뢰할 수 있는 실행 환경)에서 호스팅됩니다. 모바일 앱은 이 하이브리드 아키텍처를 통해 온디바이스와 클라우드 리소스를 모두 활용하여 다음과 같이 두 가지 모두의 고유한 이점을 누릴 수 있습니다.
이 예에서 두 모델은 함께 작동하며, 더 작고 저렴하며 빠른 Gemma 2B가 첫 번째 계층 역할을 하고 더 간단한 쿼리를 처리하는 모델 캐스케이드에 연결되는 반면, 더 큰 Gemma 7B는 Gemma 2B가 스스로 처리할 수 없는 쿼리에 대한 백업 역할을 합니다. 예를 들어, 아래의 추가 코드 스니펫에서, 먼저 각 입력 쿼리를 분석하여 두 모델 중 가장 적절한 모델을 결정하는 온디바이스 라우터로 작동하도록 Gemma 2B를 설정한 다음, 그 결과에 따라 쿼리를 온디바이스에서 로컬로 처리하거나 클라우드 기반 TEE에 있는 Gemma 7B로 릴레이합니다.
이 아키텍처에서는 클라우드의 TEE를 투명성, 암호화 보장, 신뢰할 수 있는 하드웨어로 구동되는 사용자 모바일 기기를 사실상 논리적으로 확장한 것으로 생각할 수 있습니다.
한눈에 봐도 이 설정은 복잡해 보일 수 있으며, 처음부터 모든 것을 완전히 설정해야 한다면 실제로도 그렇게 될 것입니다. 그래서 프로세스를 더 쉽게 만들려고 GenC를 정교하게 개발했습니다.
다음은 GenC에서 위와 같은 시나리오를 설정하기 위해 실제로 작성해야 하는 코드의 예입니다. Java 및 C++ 저작 API도 제공하지만, 여기서는 Python을 널리 선택해 사용하는 것으로 보고 기본적으로 제공합니다. 이 예에서는 더 민감한 주제의 존재를 (더 신중한 응답을 만들 수 있는) 더 강력한 모델로 쿼리를 처리해야 한다는 신호로 사용합니다. 이 예는 설명의 목적상 간소화된 것이라는 점을 유념하세요. 실제로는 라우팅 논리가 보다 정교하고 애플리케이션에 따라 달라질 수 있으며, 특히 작은 모델에서는 신중한 프롬프트 엔지니어링이 우수한 성능 달성에 필수적입니다.
@genc.authoring.traced_computation
def cascade(x):
gemma_2b_on_device = genc.interop.llamacpp.model_inference(
'/device/llamacpp', '/gemma-2b-it.gguf', num_threads=16, max_tokens=64)
gemma_7b_in_a_tee = genc.authoring.confidential_computation[
genc.interop.llamacpp.model_inference(
'/device/llamacpp', '/gemma-7b-it.gguf', num_threads=64, max_tokens=64),
{'server_address': /* server address */, 'image_digest': /* image digest */ }]
router = genc.authoring.serial_chain[
genc.authoring.prompt_template[
"""Read the following input carefully: "{x}".
Does it touch on political topics?"""],
gemma_2b_on_device,
genc.authoring.regex_partial_match['does touch|touches']]
return genc.authoring.conditional[
gemma_2b_on_device(x), gemma_7b_in_a_tee(x)](router(x))GitHub의 튜토리얼에서 이러한 예제 코드를 빌드하고 실행하는 방법에 대한 자세한 단계별 내역을 확인할 수 있습니다. 보시다시피, 추상화 수준은 LangChain과 같이 인기 있는 SDK에서 찾을 수 있는 것과 일치합니다. Gemma 2B 및 7B에 대한 모델 추론 호출은 프롬프트 템플릿 및 출력 파서와 함께 여기에 배치되며 체인으로 결합됩니다. (참고로, 저희는 확장하고자 하는 LangChain 상호 운용성을 제한적으로 제공합니다.)
Gemma 2B 모델 추론 호출은 온디바이스로 실행되는 체인 내에서 직접 사용되는 반면, Gemma 7B 호출은 confidential_computation 문 내에 명시적으로 삽입됩니다.
여기서 중요한 건 놀랄 일이 없다는 점입니다. 프로그래머는 온디바이스로 수행할 처리와 클라우드에서 기기에서 TEE로 위임할 사항에 대한 결정을 항상 완벽히 통제할 수 있습니다. 이 결정은 코드 구조에 명시적으로 반영됩니다. (이 예제에서는 신뢰할 수 있는 단일 백엔드에만 Gemma 7B 호출을 위임하지만, 저희가 제공하는 메커니즘은 포괄적이며 이를 사용하여 전체 에이전트 루프 등 더 큰 처리 청크를 개수에 관계없이 백엔드에 위임할 수 있습니다.)
위에 표시된 코드는 친숙한 Python 구문을 사용하여 표현되지만 내부적으로는 Intermediate Representation(또는 줄여서 'IR')이라고 하는 휴대용 플랫폼과 언어에 독립적인 형태로 변환됩니다.
이 접근 방식에는 다음을 비롯한 여러 가지 이점이 있습니다.
현실적인 배포에서는 성능이 결정적으로 중요한 요소인 경우가 많습니다. 현재 저희가 게시한 예제는 CPU 전용으로 제한되어 있으며, GenC는 현재 TEE에 있는 모델의 드라이버로 llama.cpp만 제공할 뿐입니다. 그러나 컨피덴셜 컴퓨팅 팀은 기밀 모드에서 작동하는 Nvidia H100 GPU의 예정된 미리보기와 함께 Intel AMX 기본 제공 가속기로 Intel TDX에 대한 지원을 확대하고 있으며, 저희는 사용 가능한 소프트웨어 및 하드웨어 옵션의 범위를 확장하여 최상의 성능과 더욱 광범위한 모델에 대한 지원을 제공하려고 적극적으로 노력하고 있습니다. 향후 업데이트를 기대해 주세요!
흥미를 느끼시길 바라며, 이 게시물을 통해 저희가 도입한 몇 가지 기술을 사용하여 자신만의 gen AI 애플리케이션을 개발해 보시기 바랍니다. GenC는 실험 및 연구 목적으로 개발된 실험용 프레임워크라는 점을 유념하시기 바랍니다. 즉, 무엇이 가능할지 보여주고 개발자 여러분이 저희와 함께 이 흥미진진한 분야를 탐구하고 싶은 영감을 드리고자 GenC를 만들었습니다. 더욱 발전하도록 기여하고 싶으시면 저자에게 연락하거나 GitHub에서 저희와 함께하시기 바랍니다. 함께 활발히 교류하고 협력하고 싶습니다!

LiteRT-LM이 탑재된 Chrome, Chromebook Plus, Pixel Watch의 온디바이스 생성형 AI

EmbeddingGemma 출시: 온디바이스 임베딩을 위한 동급 최고의 개방형 모델

Announcing the Agent Development Kit for Go: Build Powerful AI Agents with Your Favorite Languages

Gemma 3 270M 소개: 초효율적인 AI를 위한 콤팩트 모델

Google AI Edge Gallery: 이제 오디오와 Google Play에서 사용 가능

Announcing User Simulation in ADK Evaluation