
生成 AI(gen AI)の利用が急拡大していますが、プライベートで機密性の高いデータに生成 AI を適用する製品を作る余地は、ほぼ手つかずのまま残されています。
たとえば、次のようなことに生成 AI を利用できるかもしれません。
このような特定のアプリケーションでは、データ処理のプライバシーと機密性、透明性、外部検証性要件が厳しくなる場合があります。
Google は多くのテクノロジーを開発し、プライバシーを保つべきデータを扱う生成 AI の可能性を探ってきました。この投稿では、最近リリースされた GenC オープンソース プロジェクトを、Confidential Computing や Gemma オープンソース モデル、モバイル プラットフォームと組み合わせて使う方法を説明します。これにより、独自の生成 AI アプリで、プライバシーと機密性、透明性、外部検証性要件が厳しいデータを扱う実験を始めることができます。
この投稿で注目するシナリオは、以下に示すように、モバイルアプリでオンデバイスのデータにアクセスし、LLM で生成 AI 処理を実行します。
たとえば、デバイスに保存したメモ、文書、録画に関する要約や質問の回答を、パーソナル アシスタント アプリに依頼する場合が考えられます。こういったコンテンツには、他の人とのメッセージなどの個人情報が含まれている可能性があるため、絶対に漏れることがないようにしたいと考えます。
この例では、Gemma ファミリーのオープンソース モデルを選びました。これはモバイルアプリを想定したものですが、独自のデータをオンプレミスでホストしている企業にも、同じ原則を適用できます。
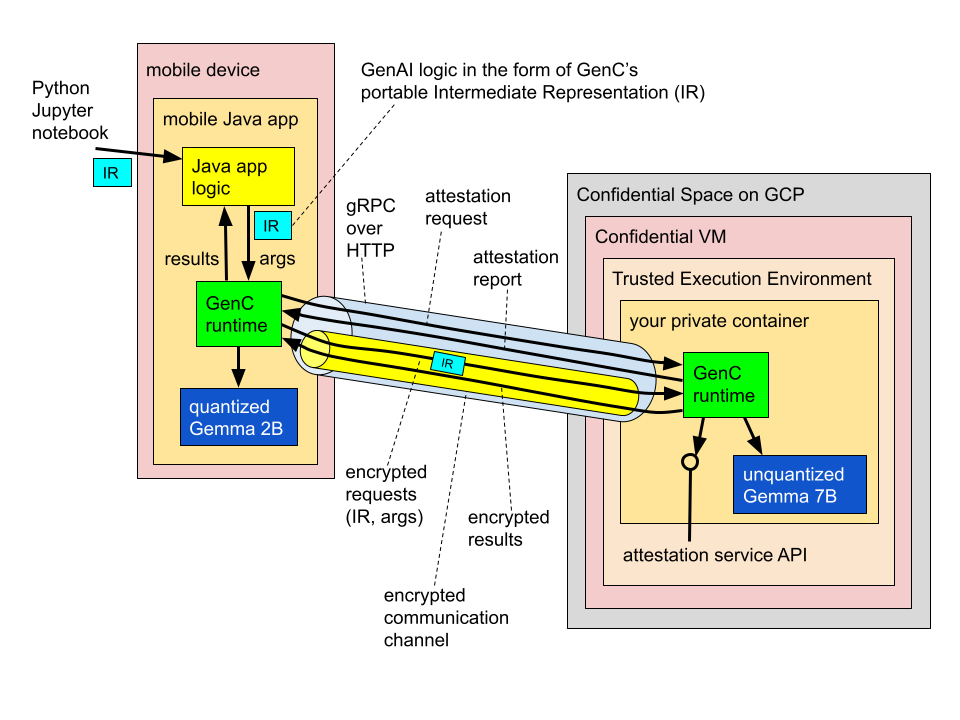
この例は、2 つの LLM を使う「ハイブリッド」設定です。1 つはユーザーのデバイスでローカル実行し、もう 1 つは Confidential Computing に対応した Google Cloud の Confidential Space 高信頼実行環境(TEE)にホストします。このハイブリッド アーキテクチャでオンデバイスとクラウドの両方のリソースを活用することで、モバイルアプリはそれぞれにしかない独自の利点を利用できます。
この例では、2 つのモデルを連携させ、モデル カスケードとして接続します。小さく安価で高速な Gemma 2B が最初の階層となり、簡単な問い合わせに対応します。一方、大きな Gemma 7B は、前者だけでは処理できない問い合わせのバックアップとして動作します。たとえば、少し下のコード スニペットでは、Gemma 2B をオンデバイス ルーターとして設定しています。これはまず、入力クエリを分析して 2 つのモデルのどちらが最適であるかを決定し、その結果に基づいて、問い合わせをオンデバイスでローカル処理するか、クラウドベースの TEE で動作する Gemma 7B にリレーします。
このアーキテクチャでは、クラウドの TEE を、ユーザーのモバイル デバイスの論理拡張と考えることができます。ただし、透明性、暗号化保証、信頼できるハードウェアといった特性が備わっています。
一見すると、この設定は複雑に思えるかもしれません。実際、ゼロからすべてを設定する場合は、そのようになります。GenC を開発したのは、このプロセスを簡単にするためにほかなりません。
以上のようなシナリオを設定するために、GenC で実際に書かなければならないコードの例を示します。人気の選択肢として、ここではデフォルトで Python を使いますが、Java と C++ のオーサリング API も提供しています。この例では、デリケートな話題ほど、強力なモデル(慎重な回答を作成できるモデル)で処理すべきシグナルとして扱います。この例は、説明用に簡略化されていることに注意してください。実際には、ルーティング ロジックをさらに洗練させ、アプリケーション固有のものにする必要があるでしょう。特に小型モデルでは、慎重なプロンプト エンジニアリングを行わなければ、優れたパフォーマンスは実現できません。
@genc.authoring.traced_computation
def cascade(x):
gemma_2b_on_device = genc.interop.llamacpp.model_inference(
'/device/llamacpp', '/gemma-2b-it.gguf', num_threads=16, max_tokens=64)
gemma_7b_in_a_tee = genc.authoring.confidential_computation[
genc.interop.llamacpp.model_inference(
'/device/llamacpp', '/gemma-7b-it.gguf', num_threads=64, max_tokens=64),
{'server_address': /* サーバー アドレス */, 'image_digest': /* イメージ ダイジェスト */ }]
router = genc.authoring.serial_chain[
genc.authoring.prompt_template[
"""Read the following input carefully: "{x}".
Does it touch on political topics?"""],
gemma_2b_on_device,
genc.authoring.regex_partial_match['does touch|touches']]
return genc.authoring.conditional[
gemma_2b_on_device(x), gemma_7b_in_a_tee(x)](router(x))GitHub のチュートリアルで、このような例を作成して実行する方法を細かく説明しています。ご覧のとおり、抽象化のレベルは、LangChain などの一般的な SDK で見られるものと同等です。Gemma 2B および 7B モデルの推論呼び出しは、プロンプト テンプレートや出力パーサ内に散りばめられ、チェーンに組み入れられます。(今のところ、LangChain との相互運用は限られていますが、今後改善したいと考えています)
Gemma 2B モデルの推論呼び出しは、デバイスで実行されるチェーンから直接行われますが、Gemma 7B の呼び出しは、明示的に confidential_computation 文に埋め込まれている点に注意してください。
重要なのは、ここにサプライズはないということです。プログラマーは、デバイスでどの処理を実行するか、デバイスからクラウドの TEE に委任するのは何かを、常に完全に制御しています。この決定は、コード構造に明示的に反映されています。(この例では、Gemma 7B 呼び出しを 1 つの信頼できるバックエンドに委任しているだけですが、提供するメカニズムは汎用的なので、エージェント ループ全体など、大きな処理のチャンクを任意の数のバックエンドに委任することもできます)
上のコードはおなじみの Python 構文で書かれていますが、内部的には、中間表現(略して「IR」)と呼ばれるものに変換されます。これは、プラットフォームにも言語にも依存しないポータブルな形式です。
このアプローチには、たくさんの利点があります。その一部を挙げましょう。
現実のデプロイでは、パフォーマンスが重要な要素になることがほとんどです。現時点で公開されている例は、動作が CPU に限定されており、現在の GenC は、llama.cpp のみを使って TEE にあるモデルを動作させています。ただし、Confidential Computing チームは、Intel AMX 内蔵アクセラレータと機密モードで実行する Nvidia H 100 GPU のプレビュー(近日公開)によって Intel TDX のサポートを拡張しています。利用できるソフトウェアとハードウェアのオプションを拡大し、最高のパフォーマンスを実現し、さまざまなモデルをサポートできるように、積極的に作業を進めていますので、今後のアップデートにご期待ください!
興味をお持ちいただければ幸いです。この投稿では、ここで紹介したテクノロジーの一部を使って、独自の生成 AI アプリケーションを作ってみることをおすすめしています。なお、GenC は実験および研究目的で開発された試験運用版フレームワークであることを覚えておいてください。可能性を実証し、このエキサイティングな空間を皆さんと一緒に探求するために開発しています。貢献したい方は、作者に連絡するか、GitHub からお知らせください。ぜひ力を合わせましょう!

Google AI Edge Gallery: 音声サポートが追加され Google Play で利用可能に

Announcing User Simulation in ADK Evaluation

EmbeddingGemma の概要: オンデバイス埋め込み処理向けの最高水準オープンモデル

LiteRT-LM を活用した Chrome、Chromebook Plus、Google Pixel Watch でのオンデバイス生成 AI

Gemma 3 270M の概要: 超高効率 AI のためのコンパクト モデル

Announcing the Agent Development Kit for Go: Build Powerful AI Agents with Your Favorite Languages