

AI의 세계는 놀라운 속도로 발전하고 있고, 시맨틱 검색 및 RAG(검색 증강 생성)와 같은 많은 최신 애플리케이션의 핵심에는 임베딩이 있습니다. 오늘, Google의 새로운 고효율 308M 매개변수 개방형 임베딩 모델인 EmbeddingGemma를 활용하는 방법에 대해 이야기할 수 있게 되어 기쁩니다. 이 모델은 크기가 작아 온디바이스 애플리케이션에 적합하지만, 동일한 효율성을 갖고 있어 특히 파인 튜닝을 통한 맞춤 설정과 관련해 클라우드를 위한 강력하고 새로운 가능성을 열어줍니다. Google Cloud의 Dataflow 및 AlloyDB와 같은 벡터 데이터베이스와 함께 EmbeddingGemma를 사용해 확장 가능한 실시간 지식 수집 파이프라인을 만드는 방법을 보여드리겠습니다.
임베딩은 단어와 개념 사이의 기본적인 관계를 포착하는 데이터의 수치적 벡터 표현입니다. 쿼리와 의미적으로 유사한 문서의 검색부터 RAG 시스템의 대용량 언어 모델(LLM)에 대한 관련 컨텍스트의 제공까지, 더욱 심층적이고 개념적인 수준에서 정보를 이해해야 하는 애플리케이션의 초석입니다.
이러한 애플리케이션을 구동하려면 비정형 데이터를 처리하고, 임베딩으로 변환하고, 전용 벡터 데이터베이스에 로드할 수 있는 강력한 지식 수집 파이프라인이 필요합니다. 바로 이 부분에서 Dataflow는 이러한 단계를 단일 관리형 파이프라인에 캡슐화하여 도움을 줄 수 있습니다.
파이프라인의 핵심에 EmbeddingGemma와 같은 작고 매우 효율적인 개방형 모델을 사용하면 전체 프로세스가 독립적으로 수행됩니다. 그러므로 임베딩 단계에서 다른 서비스에 대한 외부 네트워크 호출이 불필요해져 관리를 간소화할 수 있습니다. 개방형 모델이라 Dataflow 내에서 전적으로 호스팅할 수 있습니다. 이는 대규모 비공개 데이터 세트를 안전하게 처리할 수 있다는 믿음을 줍니다.
이러한 운영상의 장점 외에도, EmbeddingGemma는 파인 튜닝이 가능하여 특정 데이터 임베딩 요구에 맞게 사용자 설정할 수 있습니다. 여기에서 파인 튜닝 예시를 찾아볼 수 있습니다. 품질이 확장성만큼이나 중요한데, EmbeddingGemma는 그 점에서도 탁월합니다. EmbeddingGemma는 MTEB(대규모 텍스트 임베딩 벤치마크) 다국어 리더보드에서 500M 미만의 매개변수를 가진 모델 중 가장 높은 순위를 기록한 텍스트 전용 다국어 임베딩 모델입니다.
Dataflow는 통합 배치 및 스트리밍 데이터 처리를 위한 완전 관리형 자동 확장 플랫폼입니다. EmbeddingGemma와 같은 모델을 Dataflow 파이프라인에 직접 포함하면 다음과 같은 여러 장점이 있습니다.
일반적인 지식 수집 파이프라인은 데이터 소스에서 읽기, 데이터 전처리, 임베딩 생성, 벡터 데이터베이스에 쓰기의 4단계로 구성됩니다.
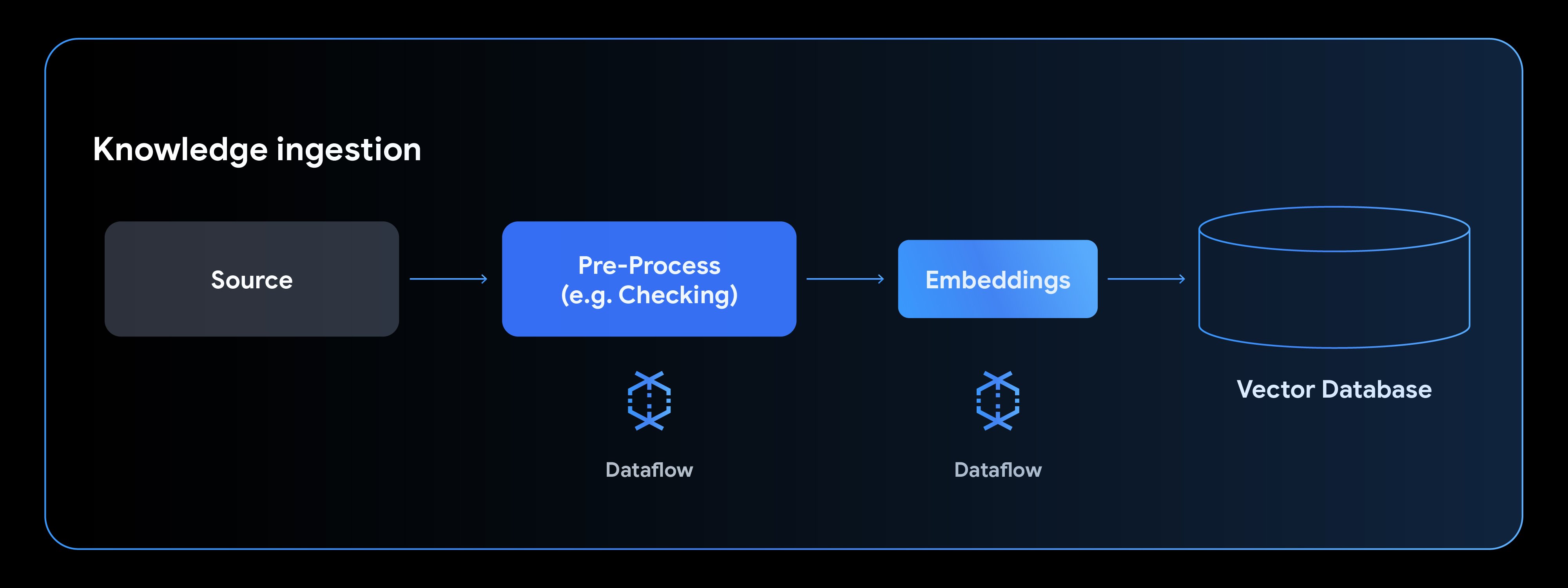
새로운 Gemma 모델을 사용하여 텍스트 임베딩을 생성하는 방법을 살펴보겠습니다. EmbeddingGemma 노트북에서 가져온 이 예에서는 Hugging Face 모델을 사용하도록 MLTransform을 구성한 다음 결과를 임베딩을 시맨틱 검색에 사용할 수 있는 AlloyDB에 작성하는 방법을 보여줍니다. AlloyDB와 같은 데이터베이스를 사용하면 이 시맨틱 검색을 추가적인 구조화된 검색과 결합하여 고품질의 관련성 높은 결과를 제공할 수 있습니다.
먼저, 임베딩할 열과 사용하는 모델의 유형을 지정하는 변환과 함께 임베딩에 사용할 모델의 이름을 정의합니다.
import tempfile
import apache_beam as beam
from apache_beam.ml.transforms.base import MLTransform
from apache_beam.ml.transforms.embeddings.huggingface import SentenceTransformerEmbeddings
# The new Gemma model for generating embeddings. You can replace this with your fine tuned model just by changing this path.
text_embedding_model_name = 'google/embeddinggemma-300m'
# Define the embedding transform with our Gemma model
embedding_transform = SentenceTransformerEmbeddings(
model_name=text_embedding_model_name, columns=['x']
)임베딩을 생성한 후에는 직접 출력 결과를 싱크로 전달하며, 보통 벡터 데이터베이스가 그 싱크가 됩니다. 이러한 임베딩을 작성하기 위해 구성 중심의 VectorDatabaseWriteTransform을 정의하겠습니다.
이 경우에는 AlloyDBVectorWriterConfig 객체를 전달하여 AlloyDB를 싱크로 사용합니다. Dataflow는 구성 객체만 사용하여 AlloyDB, CloudSQL, BigQuery를 포함한 많은 벡터 데이터베이스에 데이터 쓰기를 지원합니다.
# Define the config used to write to AlloyDB
alloydb_writer_config = AlloyDBVectorWriterConfig(
connection_config=connection_config,
table_name=table_name
)
# Build and run the pipeline
with beam.Pipeline() as pipeline:
_ = (
pipeline
| "CreateData" >> beam.Create(content) # In production could be replaced by a transform to read from any source
# MLTransform generates the embeddings
| "Generate Embeddings" >> MLTransform(
write_artifact_location=tempfile.mkdtemp()
).with_transform(embedding_transform)
# The output is written to our vector database
| 'Write to AlloyDB' >> VectorDatabaseWriteTransform(alloydb_writer_config)
)이 간단하지만 강력한 패턴을 사용하면 대규모 데이터 세트를 병렬로 처리하고, EmbeddingGemma(308M개 매개변수)로 임베딩을 생성하며, 벡터 데이터베이스를 채울 수 있습니다. 이 모든 과정이 단일하고 확장 가능하며 비용 효율적인 관리형 파이프라인 내에서 이루어집니다.
최신 Gemma 모델을 Dataflow의 확장성 및 AlloyDB와 같은 벡터 데이터베이스의 벡터 검색 능력과 결합하면 정교한 차세대 AI 애플리케이션을 손쉽게 개발할 수 있습니다.
자세한 내용은 Dataflow ML 설명서, 특히 데이터 준비 및 임베딩 생성에 대한 설명서를 참조하세요. 이 노트북을 따라 EmbeddingGemma를 사용하여 간단한 파이프라인 구축을 시도해 볼 수도 있습니다.
대규모 서버 측 애플리케이션의 경우 Gemini API를 통해 최첨단 Gemini 임베딩 모델을 탐색하여 최대의 성능과 용량을 경험해 보세요.
EmbeddingGemma에 대해 자세히 알아보려면 Google Developer 블로그에서 출시 공지 사항을 읽어보세요.



