

AI の世界は驚異的なスピードで進歩しており、埋め込みはセマンティック検索や検索拡張生成(RAG)といった多くの近代的なアプリケーションの中核をなしています。本日は、Google の新しい高効率な 3 億 800 万パラメータのオープン埋め込みモデル、EmbeddingGemma の活用方法についてお話しします。コンパクトなサイズはオンデバイス アプリケーションに最適ですが、その効率性こそが、クラウドに飛躍的な可能性をもたらします。特にファインチューニングによるカスタマイズでその影響が顕著に現れるでしょう。EmbeddingGemma を Google Cloud の Dataflow や AlloyDB などのベクトル データベースと併用して、スケーラブルなリアルタイムのナレッジ取り込みパイプラインをビルドする方法をご紹介します。
埋め込みは、単語と概念の間の基礎となる関係をキャプチャするデータの数値ベクトル表現です。これらは、クエリと意味的に類似したドキュメントの検索から、RAG システムの大規模言語モデル(LLM)に関連するコンテキストの提供まで、より深い概念レベルで情報を理解する必要があるアプリケーションの基盤となります。
これらのアプリケーションを強化するには、非構造化データを処理して埋め込みに変換し、特殊なベクトル データベースに読み込める堅牢なナレッジ取り込みパイプラインが必要です。ここで効果を発揮するのが Dataflow であり、これらのステップを単一のマネージド パイプラインにカプセル化してくれます。
EmbeddingGemma のような小型で非常に効率的なオープンモデルをパイプラインの中核に使用すると、プロセス全体が自己完結型になります。これにより、埋め込み処理において他のサービスへの外部ネットワーク呼び出しが不要になり、管理が簡素化されます。オープンモデルなので完全に Dataflow 内でホストすることができ、大規模なプライベート データセットを安全に処理できるようになります。
これらの運用上の利点に加えて、EmbeddingGemma はファインチューニング可能で、特定のデータ埋め込みニーズに合わせてカスタマイズできます。ファインチューニング例はこちらをご覧ください。品質はスケーラビリティと同様に重要であり、EmbeddingGemma はこの点でも優れています。Massive Text Embedding Benchmark(MTEB)多言語リーダーボードにおいて、5 億パラメータ未満のテキスト専用多言語埋め込みモデルで最も高いランクを獲得しています。
Dataflow は、統合されたバッチデータ処理とストリーミング データ処理のためのフルマネージド自動スケーリング プラットフォームです。EmbeddingGemma のようなモデルを Dataflow パイプラインに直接組み込むことで、次のような利点が得られます。
典型的なナレッジ取り込みパイプラインは、データソースからの読み取り、データの前処理、埋め込みの生成、ベクトル データベースへの書き込みという 4 つのフェーズで構成されます。
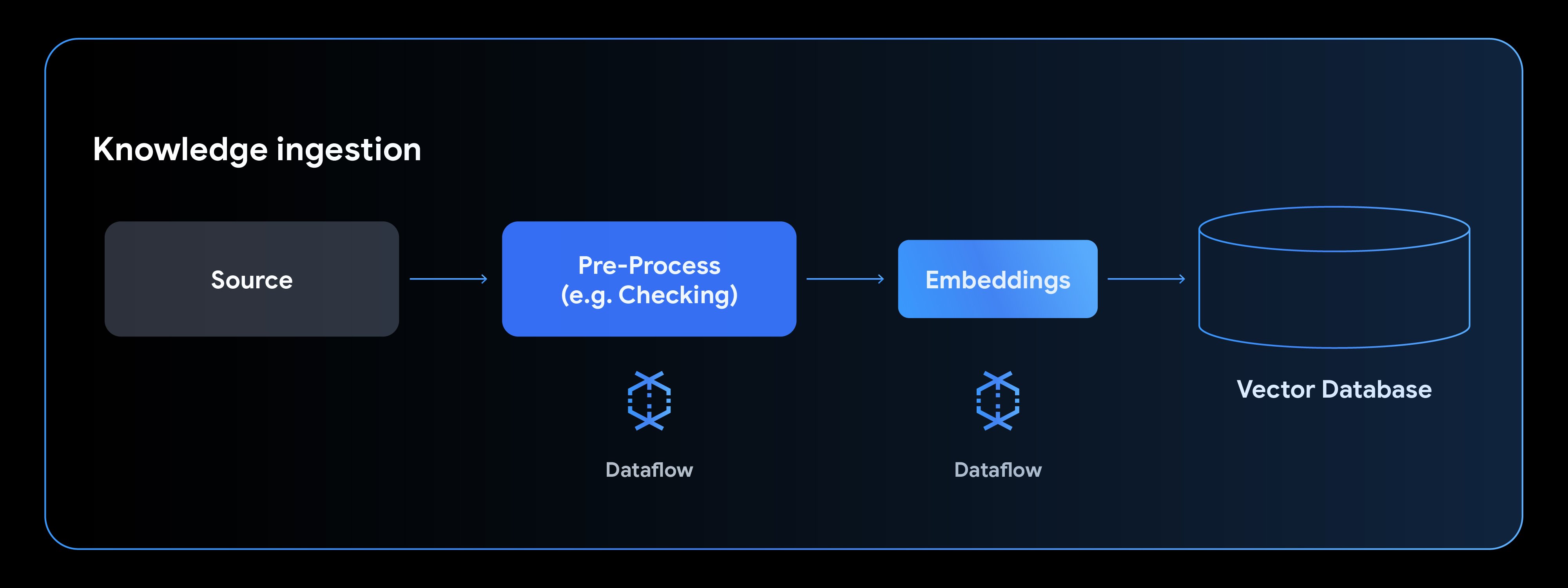
新しい Gemma モデルを使用してテキスト埋め込みを生成する方法を見ていきましょう。この例は EmbeddingGemma ノートブックをもとに作成したもので、Hugging Face モデルを使用するように MLTransform を構成し、結果を AlloyDB に書き込んで埋め込みをセマンティック検索に使用できるようにする方法を示しています。AlloyDB のようなデータベースを使用すると、このセマンティック検索と追加の構造化検索を組み合わせて、高品質で関連性の高い結果を提供できます。
まず、埋め込みに使用するモデルの名前と、埋め込む列および使用するモデルのタイプを指定する変換を定義します。
import tempfile
import apache_beam as beam
from apache_beam.ml.transforms.base import MLTransform
from apache_beam.ml.transforms.embeddings.huggingface import SentenceTransformerEmbeddings
# The new Gemma model for generating embeddings. You can replace this with your fine tuned model just by changing this path.
text_embedding_model_name = 'google/embeddinggemma-300m'
# Define the embedding transform with our Gemma model
embedding_transform = SentenceTransformerEmbeddings(
model_name=text_embedding_model_name, columns=['x']
)埋め込みを生成したら、出力をシンク(通常ベクトル データベース)に直接パイプします。これらの埋め込みを記述するには、構成主導型の VectorDatabaseWriteTransform を定義します。
この例では AlloyDBVectorWriterConfig オブジェクトを渡して、AlloyDB をシンクとして使用します。Dataflow は構成オブジェクトのみを使用し、AlloyDB、CloudSQL、BigQuery など、多くのベクトル データベースへの書き込みをサポートしています。
# Define the config used to write to AlloyDB
alloydb_writer_config = AlloyDBVectorWriterConfig(
connection_config=connection_config,
table_name=table_name
)
# Build and run the pipeline
with beam.Pipeline() as pipeline:
_ = (
pipeline
| "CreateData" >> beam.Create(content) # In production could be replaced by a transform to read from any source
# MLTransform generates the embeddings
| "Generate Embeddings" >> MLTransform(
write_artifact_location=tempfile.mkdtemp()
).with_transform(embedding_transform)
# The output is written to our vector database
| 'Write to AlloyDB' >> VectorDatabaseWriteTransform(alloydb_writer_config)
)このシンプルでありながら強力なパターンにより、大規模なデータセットの並列処理、EmbeddingGemma(3 億 800 万パラメータ)を使用した埋め込み生成、ベクトル データベースの構築を、単一のスケーラブルで費用対効果の高いマネージド パイプライン内ですべて実行できます。
最新の Gemma モデルと Dataflow のスケーラビリティ、そして AlloyDB のようなベクトル データベースのベクトル検索機能を組み合わせることで、高度な次世代 AI アプリケーションを簡単にビルドできます。
詳細については、Dataflow ML のドキュメント、特にデータの準備と埋め込みの生成に関するドキュメントをご覧ください。このノートブックの手順に沿って、EmbeddingGemma を使用してシンプルなパイプラインを試すこともできます。
大規模なサーバーサイド アプリケーションについては、Gemini API を介して最先端の Gemini Embedding モデルをお試しください。最高水準の品質とパフォーマンスを実現できます。
EmbeddingGemma の詳細については、Google デベロッパー ブログのリリースのお知らせをご覧ください。



