

The world of AI is moving at an exciting pace, and embeddings are at the core of many modern applications like semantic search and Retrieval Augmented Generation (RAG). Today, we're excited to discuss how you can leverage Google's new highly efficient, 308M parameter open embedding model, EmbeddingGemma. While its small size makes it perfect for on-device applications, this same efficiency unlocks powerful new possibilities for the cloud, especially when it comes to customization through fine-tuning. We'll show you how to use EmbeddingGemma with Google Cloud's Dataflow and vector databases like AlloyDB to build a scalable, real-time knowledge ingestion pipeline.
Embeddings are numerical vector representations of data that capture the underlying relationships between words and concepts. They are the cornerstone of applications that need to understand information on a deeper, conceptual level, from searching for documents that are semantically similar to a query to providing relevant context for Large Language Models (LLMs) in RAG systems.
To power these applications, you need a robust knowledge ingestion pipeline that can process unstructured data, convert it into embeddings, and load it into a specialized vector database. This is where Dataflow can help by encapsulating these steps into a single managed pipeline.
Using a small, highly efficient open model like EmbeddingGemma at the core of your pipeline makes the entire process self-contained, which can simplify management by eliminating the need for external network calls to other services for the embedding step. Because it's an open model, it can be hosted entirely within Dataflow. This provides the confidence to securely process large-scale, private datasets.
Beyond these operational benefits, EmbeddingGemma is also fine-tunable, allowing you to customize it for your specific data embedding needs; you can find a fine-tuning example here. Quality is just as important as scalability, and EmbeddingGemma excels here as well. It is the highest-ranking text-only multilingual embedding model under 500M parameters on the Massive Text Embedding Benchmark (MTEB) Multilingual leaderboard.
Dataflow is a fully managed, autoscaling platform for unified batch and streaming data processing. By including a model like EmbeddingGemma directly into a Dataflow pipeline, you gain several advantages:
A typical knowledge ingestion pipeline consists of four phases: reading from a data source, preprocessing the data, generating embeddings, and writing to a vector database.
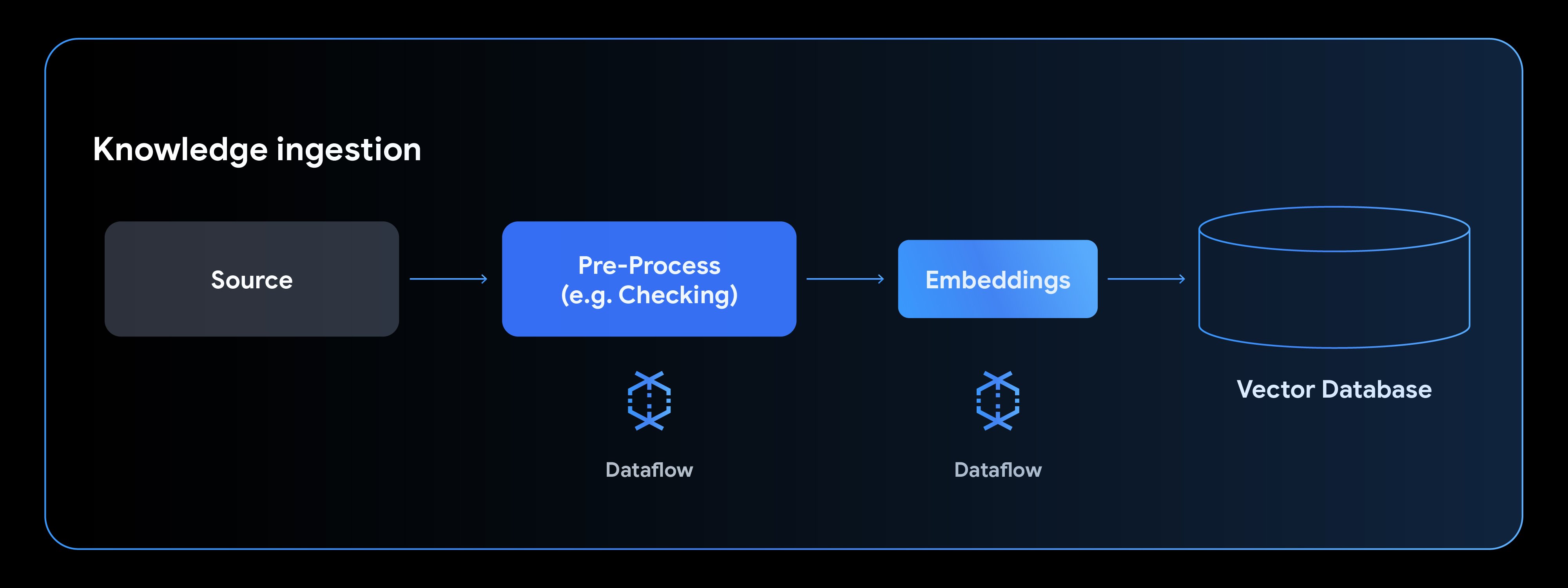
Let's walk through how to use the new Gemma model to generate text embeddings. This example, adapted from the EmbeddingGemma notebook, shows how to configure MLTransform to use a Hugging Face model and then write the results to AlloyDB where the embeddings can be used for semantic search. Databases like AlloyDB allow us to combine this semantic search with an additional structured search to provide high quality and relevant results.
First, we define the name of the model we'll use for embeddings along with a transform specifying the columns we want to embed and the type of model we're using.
import tempfile
import apache_beam as beam
from apache_beam.ml.transforms.base import MLTransform
from apache_beam.ml.transforms.embeddings.huggingface import SentenceTransformerEmbeddings
# The new Gemma model for generating embeddings. You can replace this with your fine tuned model just by changing this path.
text_embedding_model_name = 'google/embeddinggemma-300m'
# Define the embedding transform with our Gemma model
embedding_transform = SentenceTransformerEmbeddings(
model_name=text_embedding_model_name, columns=['x']
)Once we've generated embeddings, we'll pipe the output directly into our sink, which will usually be a vector database. To write these embeddings, we will define a config-driven VectorDatabaseWriteTransform.
In this case, we will use AlloyDB as our sink by passing in an AlloyDBVectorWriterConfig object. Dataflow supports writing to many vector databases, including AlloyDB, CloudSQL, and BigQuery, using just configuration objects.
# Define the config used to write to AlloyDB
alloydb_writer_config = AlloyDBVectorWriterConfig(
connection_config=connection_config,
table_name=table_name
)
# Build and run the pipeline
with beam.Pipeline() as pipeline:
_ = (
pipeline
| "CreateData" >> beam.Create(content) # In production could be replaced by a transform to read from any source
# MLTransform generates the embeddings
| "Generate Embeddings" >> MLTransform(
write_artifact_location=tempfile.mkdtemp()
).with_transform(embedding_transform)
# The output is written to our vector database
| 'Write to AlloyDB' >> VectorDatabaseWriteTransform(alloydb_writer_config)
)This simple yet powerful pattern allows you to process massive datasets in parallel, generate embeddings with EmbeddingGemma – 308M parameters – and populate your vector database—all within a single, scalable, cost-efficient, and managed pipeline.
By combining the latest Gemma models with the scalability of Dataflow and the vector search power of vector databases like AlloyDB, you can build sophisticated, next-generation AI applications with ease.
To learn more, explore the Dataflow ML documentation, especially documentation on preparing data and generating embeddings. You can also try a simple pipeline using EmbeddingGemma by following this notebook.
For large-scale, server-side applications, explore our state-of-the-art Gemini Embedding model via the Gemini API for maximum performance and capacity.
To learn more about EmbeddingGemma, read our launch announcement on the Google Developer blog.

ADK for Java opening up to third-party language models via LangChain4j integration

Building High-Performance Data Pipelines with Grain and ArrayRecord

Architecting efficient context-aware multi-agent framework for production

Announcing the Data Commons Gemini CLI extension