

Following in the footsteps of Gemma 1.1 (Kaggle, Hugging Face), CodeGemma (Kaggle, Hugging Face) and the PaliGemma multimodal model (Kaggle, Hugging Face), we are happy to announce the release of the Gemma 2 model in Keras.
Gemma 2 is available in two sizes - 9B and 27B parameters - with standard and instruction-tuned variants. You can find them here:
Gemma 2’s top-notch results on LLM benchmarks are covered elsewhere (see goo.gle/gemma2report). In this post we would like to showcase how the combination of Keras and JAX can help you work with these large models.
JAX is a numerical framework built for scale. It leverages the XLA machine learning compiler and trains the largest models at Google.
Keras is the modeling framework for ML engineers, now running on JAX, TensorFlow or PyTorch. Keras now brings the power model parallel scaling through a delightful Keras API. You can try the new Gemma 2 models in Keras here:
Because of their size, these models can only be loaded and fine-tuned at full precision by splitting their weights across multiple accelerators. JAX and XLA have extensive support for weights partitioning (SPMD model parallelism) and Keras adds the keras.distribution.ModelParallel API to help you specify shardings layer by layer in a simple manner:
# List accelerators
devices = keras.distribution.list_devices()
# Arrange accelerators in a logical grid with named axes
device_mesh = keras.distribution.DeviceMesh((2, 8), ["batch", "model"], devices)
# Tell XLA how to partition weights (defaults for Gemma)
layout_map = gemma2_lm.backbone.get_layout_map()
# Define a ModelParallel distribution
model_parallel = keras.distribution.ModelParallel(device_mesh, layout_map, batch_dim_name="batch")
# Set is as the default and load the model
keras.distribution.set_distribution(model_parallel)
gemma2_lm = keras_nlp.models.GemmaCausalLM.from_preset(...)The gemma2_lm.backbone.get_layout_map()function is a helper returning a layer by layer sharding configuration for all the weights of the model. It follows the Gemma paper (goo.gle/gemma2report) recommendations. Here is an excerpt:
layout_map = keras.distribution.LayoutMap(device_mesh)
layout_map["token_embedding/embeddings"] = ("model", "data")
layout_map["decoder_block.*attention.*(query|key|value).kernel"] =
("model", "data", None)
layout_map["decoder_block.*attention_output.kernel"] = ("model", None, "data")
...In a nutshell, for each layer, this config specifies along which axis or axes to split each block of weights, and on which accelerators to place the pieces. It’s easier to understand with a picture. Let’s take as an example the “query” weights in the Transformer attention architecture, which are of shape (nb heads, embed size, head dim):
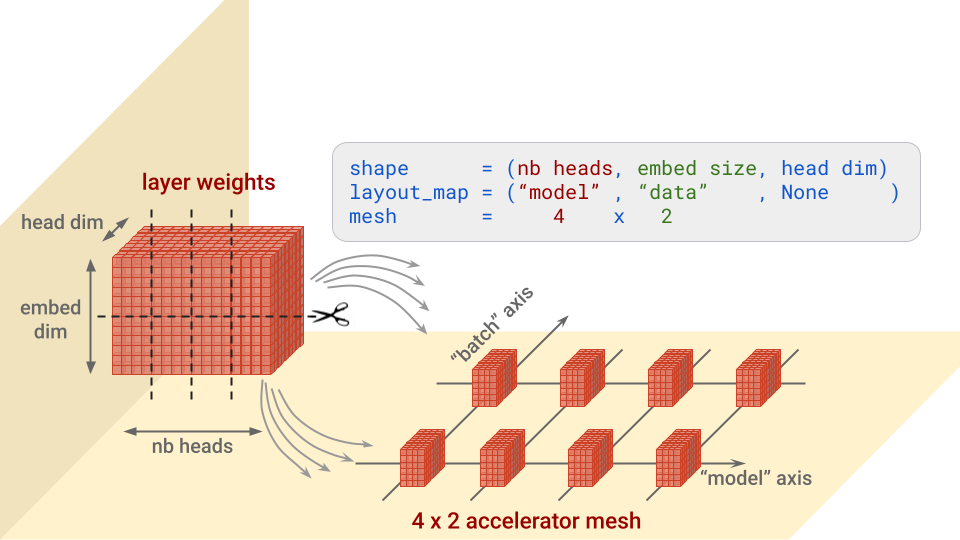
Note: mesh dimensions for which there are no splits will receive copies. This would be the case for example if the layout map above was (“model”, None, None).
Notice also the batch_dim_name="batch" parameter in ModelParallel. If the “batch” axis has multiple rows of accelerators on it, which is the case here, data parallelism will also be used. Each row of accelerators will load and train on only a part of each data batch, and then the rows will combine their gradients.
Once the model is loaded, here are two handy code snippets to display the weight shardings that were actually applied:
for variable in gemma2_lm.backbone.get_layer('decoder_block_1').weights:
print(f'{variable.path:<58} {str(variable.shape):<16} \
{str(variable.value.sharding.spec)}')
#... set an optimizer through gemma2_lm.compile() and then:
gemma2_lm.optimizer.build(gemma2_lm.trainable_variables)
for variable in gemma2_lm.optimizer.variables:
print(f'{variable.path:<73} {str(variable.shape):<16} \
{str(variable.value.sharding.spec)}')And if we look at the output (below), we notice something important: the regexes in the layout spec matched not only the layer weights, but also their corresponding momentum and velocity variables in the optimizer and sharded them appropriately. This is an important point to check when partitioning a model.
# for layers:
# weight name . . . . . . . . . . shape . . . . . . layout spec
decoder_block_1/attention/query/kernel (16, 3072, 256)
PartitionSpec('model', None, None)
decoder_block_1/ffw_gating/kernel (3072, 24576)
PartitionSpec(None, 'model')
...
# for optimizer vars:
# var name . . . . . . . . . . . .shape . . . . . . layout spec
adamw/decoder_block_1_attention_query_kernel_momentum
(16, 3072, 256) PartitionSpec('model', None, None)
adamw/decoder_block_1_attention_query_kernel_velocity
(16, 3072, 256) PartitionSpec('model', None, None)
...LoRA is a technique that freezes model weights and replaces them with low-rank, i.e. small, adapters.
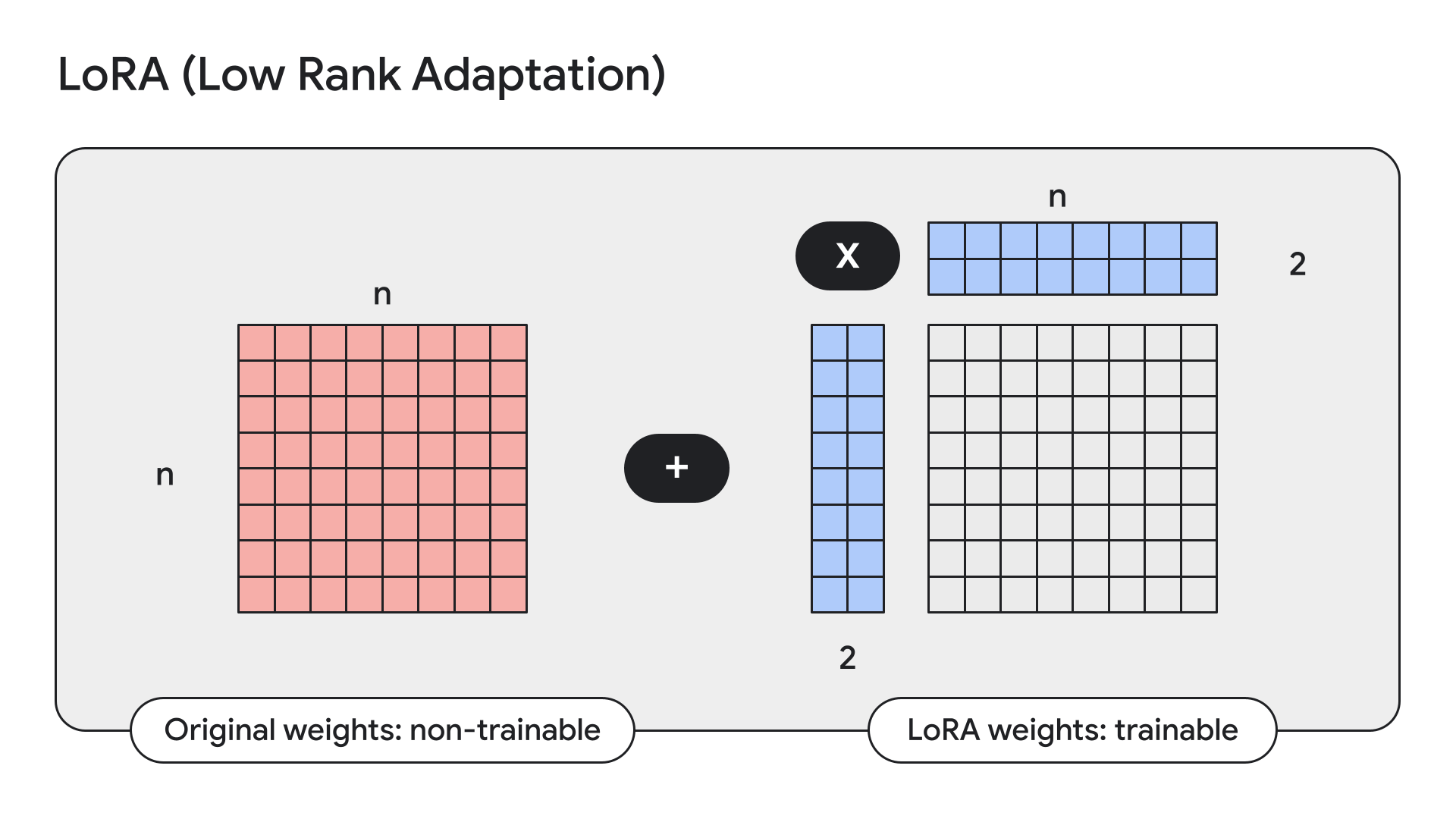
Keras also has straightforward APIs for this:
gemma2_lm.backbone.enable_lora(rank=4) # Rank picked from empirical testingDisplaying model details with model.summary() after enabling LoRA, we can see that LoRA reduces the number of trainable parameters in Gemma 9B from 9 billion to 14.5 million.
Last month, we announced that Keras models would be available, for download and user uploads, on both Kaggle and Hugging Face. Today, we are pushing the Hugging Face integration even further: you can now load any fine-tuned weights for supported models, whether they have been trained using a Keras version of the model or not. Weights will be converted on the fly to make this work. This means that you now have access to the dozens of Gemma fine-tunes uploaded by Hugging Face users, directly from KerasNLP. And not just Gemma. This will eventually work for any Hugging Face Transformers model that has a corresponding KerasNLP implementation. For now Gemma and Llama3 work. You can try it out on the Hermes-2-Pro-Llama-3-8B fine-tune for example using this Colab:
causal_lm = keras_nlp.models.Llama3CausalLM.from_preset(
"hf://NousResearch/Hermes-2-Pro-Llama-3-8B"
)PaliGemma is a powerful open VLM inspired by PaLI-3. Built on open components including the SigLIP vision model and the Gemma language model, PaliGemma is designed for class-leading fine-tune performance on a wide range of vision-language tasks. This includes image captioning, visual question answering, understanding text in images, object detection, and object segmentation.
You can find the Keras implementation of PaliGemma on GitHub, Hugging Face models and Kaggle.
We hope you will enjoy experimenting or building with the new Gemma 2 models in Keras!

Announcing the Colab MCP Server: Connect Any AI Agent to Google Colab

Introducing EmbeddingGemma: The Best-in-Class Open Model for On-Device Embeddings

Introducing Gemma 3 270M: The compact model for hyper-efficient AI
Developer’s Guide to AI Agent Protocols

Build a smart financial assistant with LlamaParse and Gemini 3.1

Jump to play: Building with Gemini & MediaPipe