

Gemma 1.1(Kaggle, Hugging Face), CodeGemma(Kaggle, Hugging Face), PaliGemma 멀티모달 모델(Kaggle, Hugging Face)에 뒤이어 Keras로 구현된 Gemma 2 모델의 출시를 발표하게 되어 기쁩니다.
Gemma 2는 90억 개 및 270억 개 매개변수의 두 가지 크기로 제공되고 표준 버전과 명령어 튜닝 버전이 있습니다. 다음 링크에서 확인하실 수 있습니다.
LLM 벤치마크에 대한 Gemma 2의 최고 수준 결과는 다른 곳에서 다룹니다(goo.gle/gemma2report 참조). 이 게시물에서는 Keras와 Jax의 조합이 이러한 대규모 모델로 작업하는 데 어떻게 도움이 되는지 보여드리고자 합니다.
JAX는 확장성을 위해 개발된 수치 프레임워크로서 XLA 머신러닝 컴파일러를 활용하고 Google에서 가장 큰 모델을 학습시킵니다.
이제 JAX, TensorFlow 또는 PyTorch에서 실행되는 Keras는 ML 엔지니어용 모델링 프레임워크입니다. 현재 Keras는 마음에 쏙 드는 Keras API를 통해 강력한 모델 병렬 확장 기능을 제공합니다. 다음 링크를 통해 Keras에서 새로운 Gemma 2 모델을 사용해 볼 수 있습니다.
이러한 모델은 그 크기 때문에 가중치를 여러 가속기에 걸쳐 분할하여 로드해야만 하고 최대 정밀도로 미세 조정해야만 합니다. JAX와 XLA는 가중치 분할(SPMD 모델 병렬 처리)을 광범위하게 지원하며 Keras는 keras.distribution.ModelParallel API를 추가하여 다음과 같이 간단한 방식으로 샤딩을 레이어 단위로 지정할 수 있습니다.
# 가속기 나열
devices = keras.distribution.list_devices()
# 명명된 축이 있는 논리적 그리드에 가속기 배열
device_mesh = keras.distribution.DeviceMesh((2, 8), ["batch", "model"], devices)
# XLA에 가중치 분할 방법 지시(Gemma의 기본값)
layout_map = gemma2_lm.backbone.get_layout_map()
# ModelParallel 분배 정의
model_parallel = keras.distribution.ModelParallel(device_mesh, layout_map, batch_dim_name="batch")
# 기본값으로 설정하고 모델 로드
keras.distribution.set_distribution(model_parallel)
gemma2_lm = keras_nlp.models.GemmaCausalLM.from_preset(...)gemma2_lm.backbone.get_layout_map() 함수는 모델의 모든 가중치에 대한 레이어 샤딩 구성에 따라 레이어를 반환하는 도우미입니다. 이 함수는 Gemma 논문(goo.gle/gemma2report)의 권장 사항을 따릅니다. 아래 발췌 내용을 참조하세요.
layout_map = keras.distribution.LayoutMap(device_mesh)
layout_map["token_embedding/embeddings"] = ("model", "data")
layout_map["decoder_block.*attention.*(query|key|value).kernel"] =
("model", "data", None)
layout_map["decoder_block.*attention_output.kernel"] = ("model", None, "data")
...간단히 말해, 각 레이어에 대해 이 구성에서는 각 가중치 블록을 분할할 축과 조각을 배치할 가속기를 지정합니다. 그림으로 보면 더 쉽게 이해할 수 있습니다. Transformer 어텐션 아키텍처의 '쿼리' 가중치를 예로 들어 보겠습니다. 이 가중치는 (nb heads, embed size, head dim) 형태입니다.
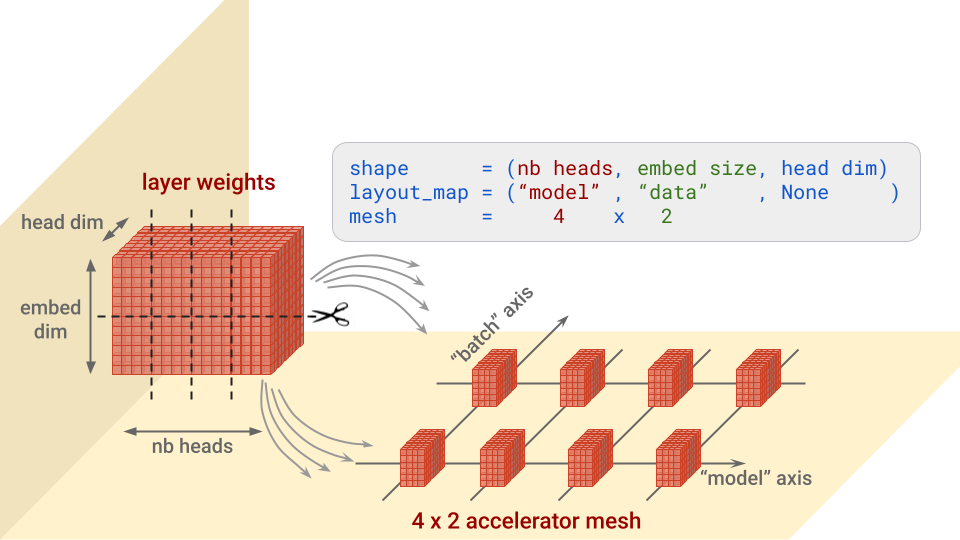
참고: 분할이 없는 메시 차원은 복사본을 받게 됩니다. 예를 들어 위의 레이아웃 맵이 (“model”, None, None)인 경우입니다.
ModelParallel에서 batch_dim_name="batch" 매개변수도 확인하세요. 이 사례와 같이 'batch' 축상에 여러 행의 가속기가 있는 경우 데이터 병렬 처리도 사용됩니다. 가속기의 각 행은 각 데이터 배치의 일부만 로드하고 학습하며, 그런 다음에 행이 그라데이션을 결합합니다.
일단 모델이 로드되면, 다음과 같이 실제로 적용된 가중치 샤딩을 표시하는 두 가지 편리한 코드 스니펫이 있습니다.
for variable in gemma2_lm.backbone.get_layer('decoder_block_1').weights:
print(f'{variable.path:<58} {str(variable.shape):<16} \
{str(variable.value.sharding.spec)}')
#... gemma2_lm.compile()을 통해 최적화 프로그램을 설정한 다음
gemma2_lm.optimizer.build(gemma2_lm.trainable_variables)
for variable in gemma2_lm.optimizer.variables:
print(f'{variable.path:<73} {str(variable.shape):<16} \
{str(variable.value.sharding.spec)}')출력(아래)을 살펴보면 중요한 점을 알 수 있습니다. 레이아웃 사양의 정규식이 레이어 가중치뿐 아니라 옵티마이저의 해당 운동량 및 속도 변수와도 일치하여 이들을 적절하게 분할했다는 점입니다. 이는 모델을 분할할 때 확인해야 할 중요한 사항입니다.
# 레이어의 경우:
# 가중치 이름 . . . . . . . . . . 모양 . . . . . . 레이아웃 사양
decoder_block_1/attention/query/kernel (16, 3072, 256)
PartitionSpec('model', None, None)
decoder_block_1/ffw_gating/kernel (3072, 24576)
PartitionSpec(None, 'model')
...
# 옵티마이저 변수의 경우:
# 변수 이름 . . . . . . . . . . . .모양 . . . . . . 레이아웃 사양
adamw/decoder_block_1_attention_query_kernel_momentum
(16, 3072, 256) PartitionSpec('model', None, None)
adamw/decoder_block_1_attention_query_kernel_velocity
(16, 3072, 256) PartitionSpec('model', None, None)
...LoRA는 모델 가중치를 고정하고 낮은 순위의 어댑터, 즉 소형 어댑터로 모델 가중치를 대체하는 기법입니다.
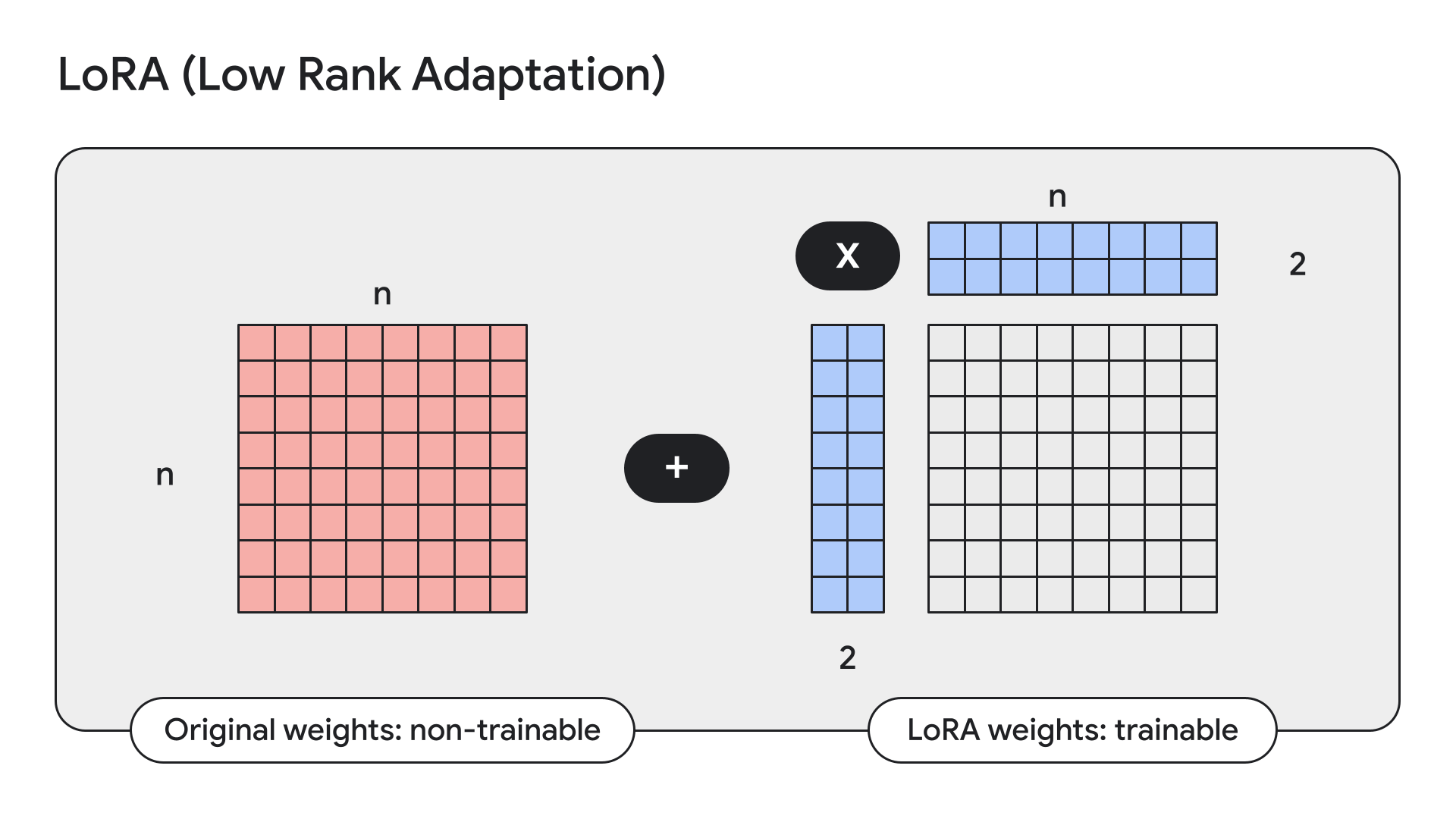
Keras에는 이를 위한 간단한 API도 있습니다.
gemma2_lm.backbone.enable_lora(rank=4) # 경험적 테스트에서 뽑은 순위LoRA를 활성화한 후 model.summary()로 모델 세부 정보를 표시하면 LoRA가 Gemma 9B에서 학습 가능한 매개변수의 수를 90억 개에서 1,450만 개로 줄이는 것을 확인할 수 있습니다.
지난달에 저희는 Kaggle과 Hugging Face에서 모두 Keras 모델을 다운로드와 사용자 업로드에 사용할 수 있게 될 것이라고 발표했습니다. 현재는 Hugging Face 통합을 더욱더 강화하고 있습니다. 이제 지원되는 모델을 Keras 버전의 모델을 사용하여 학습시켰는지에 관계없이 이들 모델에 대해 미세 조정된 가중치를 로드할 수 있습니다. 이 작업을 수행하기 위해 가중치가 즉석에서 변환됩니다. 즉, 이제 KerasNLP에서 직접 Hugging Face 사용자가 업로드한 수십 개의 Gemma 미세 조정에 액세스할 수 있다는 뜻입니다. Gemma뿐만이 아닙니다. 이는 결국 해당 KerasNLP 구현이 있는 모든 Hugging Face Transformer 모델에서 유효합니다. 현재로서는 Gemma와 Llama3가 해당됩니다. 예를 들어, 다음 Colab을 사용하여 Hermes-2-Pro-Llama-3-8B 미세 조정에서 시도해 볼 수 있습니다.
causal_lm = keras_nlp.models.Llama3CausalLM.from_preset(
"hf://NousResearch/Hermes-2-Pro-Llama-3-8B"
)PaliGemma는 PaLI-3에서 영감을 받아 개발한 강력한 개방형 VLM입니다. SigLIP 비전 모델과 Gemma 언어 모델을 포함한 개방형 구성 요소를 기반으로 개발된 PaliGemma는 광범위한 비전 언어 작업에서 동급 최고의 미세 조정 성능을 제공하도록 설계한 VLM입니다. PaliGemma에는 이미지 캡션, 시각적 질문 답변, 이미지 내 텍스트 이해, 객체 감지, 객체 분할 기능이 포함됩니다.
GitHub, Hugging Face 모델, Kaggle에서 PaliGemma의 Keras 구현을 확인할 수 있습니다.
Keras에서 새로운 Gemma 2 모델로 다양한 실험과 개발을 즐기세요!



