

Gemma 1.1(Kaggle、Hugging Face)、CodeGemma(Kaggle、Hugging Face)、PaliGemma マルチモーダル モデル(Kaggle、Hugging Face)に続き、Keras に Gemma 2 モデルをリリースしました。
Gemma 2 は、2 つのサイズ(9B および 27B パラメータ)で利用でき、標準版とインストラクション チューニング版があります。こちらからご覧ください。
Gemma 2 は、LLM ベンチマークで圧倒的な結果をたたき出していますが、この点には触れません(goo.gle/gemma2report を参照)。この投稿では、この大規模モデルを活用するために、Keras および JAX と組み合わせる方法を紹介します。
JAX は大規模対応の数値フレームワークです。XLA 機械学習コンパイラを活用しており、Google 最大のモデルのトレーニングに利用されています。
Keras は ML エンジニア向けのモデリング フレームワークです。現在 JAX、TensorFlow、PyTorch で動作し、魅力的な Keras API を通じてパワーモデルの並列スケーリングを実現します。以下から、Keras で新しい Gemma 2 モデルを試すことができます。
サイズの関係で、これらのモデルを完全な精度で読み込んでファイン チューニングするには、重みを複数のアクセラレータに分割する必要があります。JAX と XLA は、重みパーティショニング(SPMD モデル並列処理)を幅広くサポートしています。Keras には keras.distribution.ModelParallel API が追加されているので、シンプルな方法でレイヤごとにシャーディングを指定できます。
# アクセラレータのリスト
devices = keras.distribution.list_devices()
# 軸に名前をつけ、論理グリッドにアクセラレータを配置する
device_mesh = keras.distribution.DeviceMesh((2, 8), ["batch", "model"], devices)
# XLA に重みのパーティショニング方法を伝達(Gemma のデフォルト)
layout_map = gemma2_lm.backbone.get_layout_map()
# ModelParallel 分散を定義
model_parallel = keras.distribution.ModelParallel(device_mesh, layout_map, batch_dim_name="batch")
# デフォルトとして設定してモデルを読み込む
keras.distribution.set_distribution(model_parallel)
gemma2_lm = keras_nlp.models.GemmaCausalLM.from_preset(...)gemma2_lm.backbone.get_layout_map() 関数は、モデルのすべての重みのレイヤごとのシャーディング構成を返すヘルパーです。これは、Gemma の論文(goo.gle/gemma2report)の推奨事項に従っています。以下は抜粋です。
layout_map = keras.distribution.LayoutMap(device_mesh)
layout_map["token_embedding/embeddings"] = ("model", "data")
layout_map["decoder_block.*attention.*(query|key|value).kernel"] =
("model", "data", None)
layout_map["decoder_block.*attention_output.kernel"] = ("model", None, "data")
...簡単に言えば、この構成は、各レイヤで重みのブロックをどの軸に沿って分割し、それぞれをどのアクセラレータに配置するかを指定しています。図を見るほうがわかりやすいでしょう。例として、トランスフォーマー アテンション アーキテクチャの「query」の重みについて説明します。この形状は、(nb heads, embed size, head dim) です。
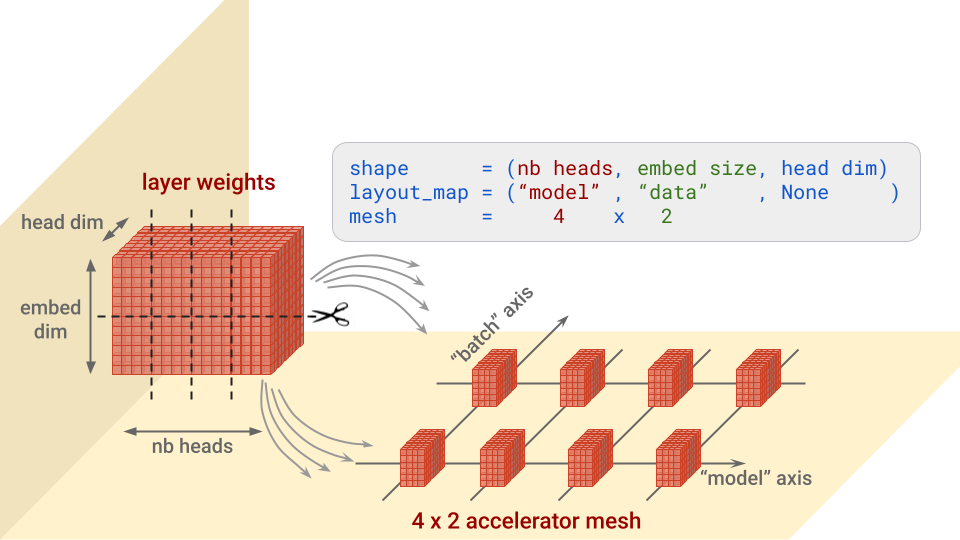
注: 分割されないメッシュの次元には、コピーが渡されます。たとえば、上のレイアウト マップが (“model”, None, None) となる場合です。
ModelParallel の batch_dim_name="batch" パラメータにも注意してください。この例のように、“batch” 軸に複数行のアクセラレータがある場合、データも並列化されます。アクセラレータの各行は、各データバッチの一部のみを読み込んでトレーニングし、その後、各行の勾配が結合されます。
モデルが読み込まれると、次の 2 つの便利なコード スニペットを使って、実際に適用された重みシャーディングを表示できます。
for variable in gemma2_lm.backbone.get_layer('decoder_block_1').weights:
print(f'{variable.path:<58} {str(variable.shape):<16} \
{str(variable.value.sharding.spec)}')
#... gemma2_lm.compile() でオプティマイザを設定してから、次を実行
gemma2_lm.optimizer.build(gemma2_lm.trainable_variables)
for variable in gemma2_lm.optimizer.variables:
print(f'{variable.path:<73} {str(variable.shape):<16} \
{str(variable.value.sharding.spec)}')出力(下記)を確認すると、重要なことがわかります。レイアウト仕様の正規表現は、レイヤの重みだけでなく、オプティマイザの対応するモーメンタムと速度の変数にも一致するため、適切なシャーディングが行われます。これは、モデルをパーティショニングするときに確認すべき重要なポイントです。
# レイヤ:
# 重み名 . . . . . . . . . . 形状 . . . . . . レイアウト仕様
decoder_block_1/attention/query/kernel (16, 3072, 256)
PartitionSpec('model', None, None)
decoder_block_1/ffw_gating/kernel (3072, 24576)
PartitionSpec(None, 'model')
...
# オプティマイザ変数:
# 変数名 . . . . . . . . . . . .形状 . . . . . . レイアウト仕様
adamw/decoder_block_1_attention_query_kernel_momentum
(16, 3072, 256) PartitionSpec('model', None, None)
adamw/decoder_block_1_attention_query_kernel_velocity
(16, 3072, 256) PartitionSpec('model', None, None)
...LoRA は、モデルの重みをフリーズさせ、それを低ランク、すなわち小さなアダプタで置き換える手法です。
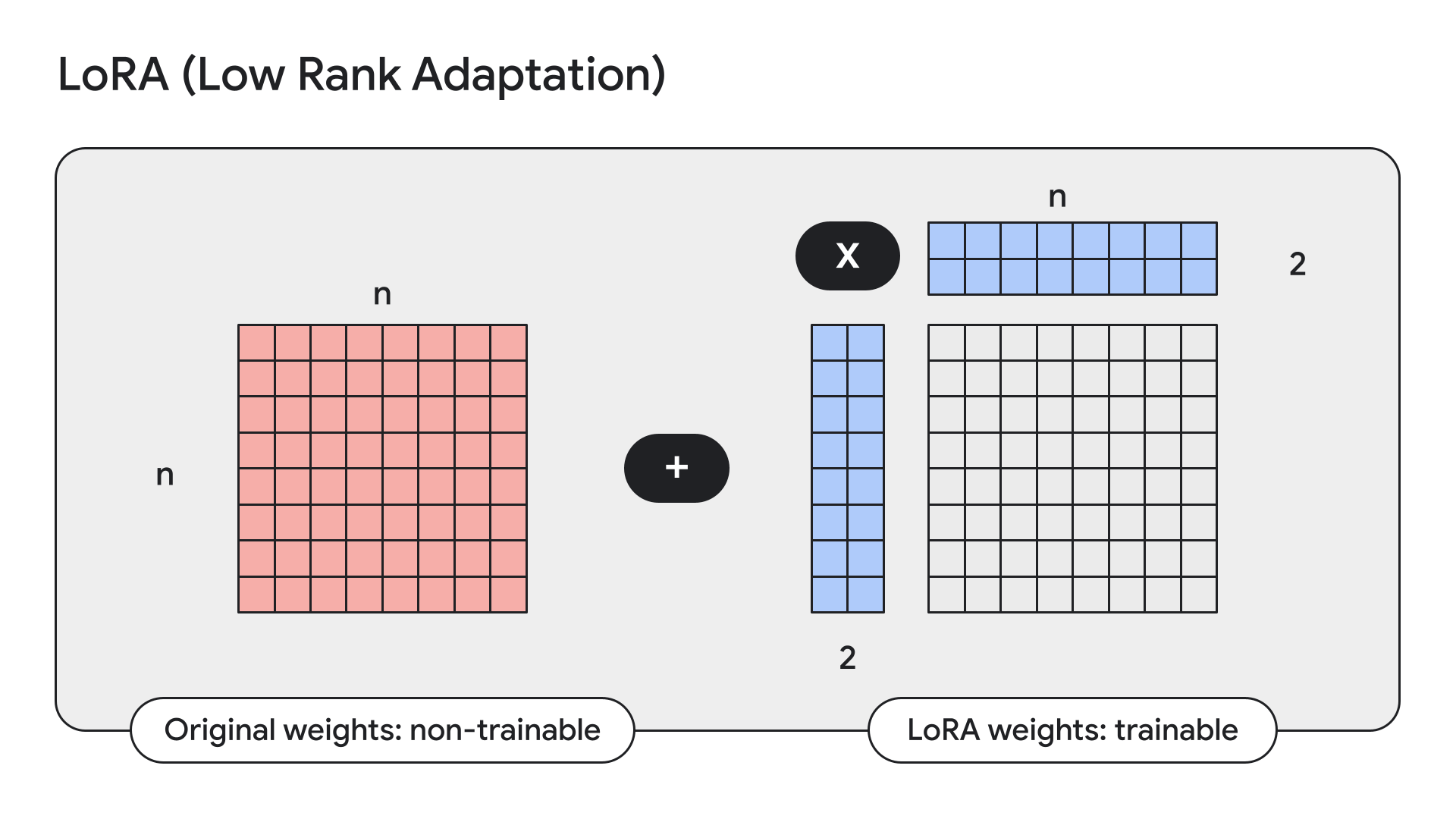
Keras には、簡単にこれを行う API もあります。
gemma2_lm.backbone.enable_lora(rank=4) # 経験的テストから選んだランクLoRA を有効にしてから model.summary() でモデルの詳細を表示すると、Gemma 9B のトレーニング可能なパラメータ数が 90 億から 1450 万に減少していることがわかります。
先月お知らせしたように、Kaggle と Hugging Face の両方で、Keras モデルのダウンロードとユーザーによるアップロードが可能になりました。本日より、Hugging Face との連携をさらに強化し、Keras バージョンのモデルでトレーニングしたかどうかは問わずに、サポートされているモデルで、ファイン チューニングした重みを読み込めるようにします。重みは即時変換されます。つまり、Hugging Face ユーザーがアップロードしたたくさんの Gemma ファイン チューニングに、KerasNLP から直接アクセスできます。そして、Gemma だけではありません。今後、この仕組みは、対応する KerasNLP 実装があるすべての Hugging Face トランスフォーマー モデルで動作するようになります。現時点では、Gemma と Llama 3 で動作します。こちらの Colab から、Hermes-2-Pro-Llama-3-8B ファイン チューニングなどで試すことができます。
causal_lm = keras_nlp.models.Llama3CausalLM.from_preset(
"hf://NousResearch/Hermes-2-Pro-Llama-3-8B"
)PaliGemma は、PaLI-3 に触発された強力なオープン VLM です。PaliGemma は、SigLIP 視覚モデルや Gemma 言語モデルなどのオープン コンポーネントを基に開発され、幅広い視覚言語タスクでトップレベルのファイン チューニング性能を実現するように設計されています。たとえば、画像のキャプション生成、視覚を使う必要がある質問への回答、画像内のテキストの理解、物体の検出やセグメンテーションなどです。
PaliGemma の Keras 実装は、GitHub、Hugging Face モデル、Kaggle にあります。
Keras で新しい Gemma 2 モデルを楽しく実験したり、構築したりしていただけることを願っています!



