Gemini’s native multimodal and long context capabilities power applications like NotebookLM, Google Lens and many more, and have unlocked a variety of novel applications for developers.
This blogpost highlights some of the use cases that we’re most excited about for image and video input in the Gemini API, and that we hope will spark new ideas for what can be built with vision capabilities. The examples showcased are with Gemini 1.5 Pro, our strongest performing model for image and video understanding applications, but we encourage trying out 1.5 Flash and 1.5 Flash-8B (and our experimental models!) depending on the complexity of your task.
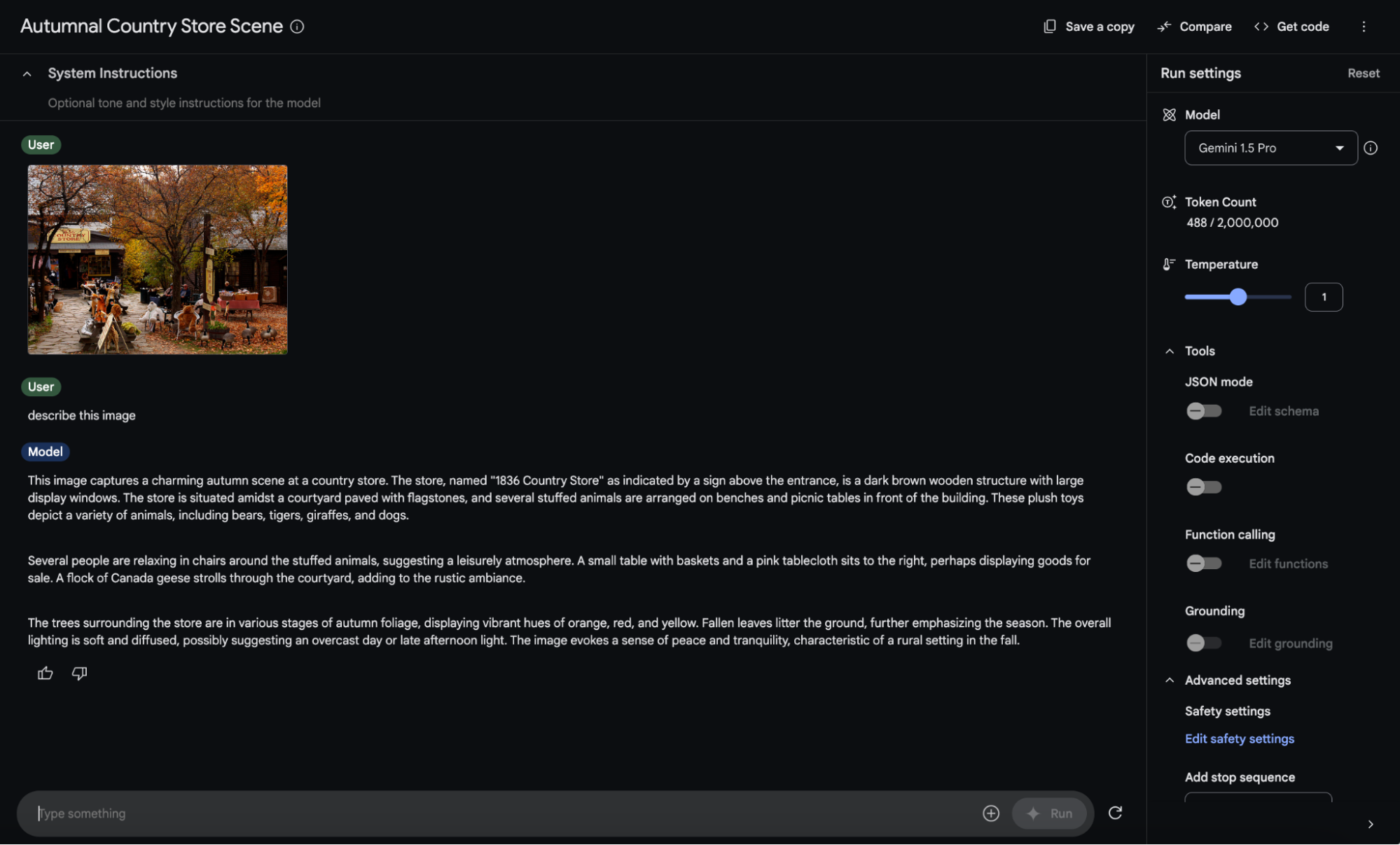
Gemini models can describe, answer questions about, and reason over images. The models adjust description length, tone and format depending on the prompt, so you are able to adjust model behavior for your use case.
Gemini is able to understand and process over 1000 pages of PDF documents. With its native vision capabilities, Gemini can accurately transcribe tables, interpret complex multi-column layouts, understand charts, sketches, diagrams and handwritten text inside documents, and use this text and visual information to carry out end to end tasks.
Here is one example where Gemini uses information from a series of PDFs to generate structured outputs and code.
We fed in 15 Alphabet earnings releases, up to Q3 2024 (152 pages total), and asked Gemini to extract Google revenue numbers from across these documents, create tables aggregating this data, and then write code using matplotlib to visualize revenue and quarter-on-quarter growth.
Prompt:
These are earnings reports over the last 15 quarters.
2. Generate a table of total revenues for each Google product/service -- "Google Search", "Youtube ads", "Google Network", "Google subscriptions, platforms and devices", "Google Cloud" and "Other Bets" -- for each of the quarters (15 in total). Show this in multiple tables (4 quarters for each table) in your output. Note that Google subscriptions, platforms and devices was called 'Google other' third quarter 2023 and before.
Response:
Here are the tables you requested:
**1. Total Revenue by Quarter (in millions USD)**
| Quarter Ended | Year | Total Revenue |
|-------------------|------|--------------|
| March 31 | 2021 | 55,314 |
| June 30 | 2021 | 61,880 |
| September 30 | 2021 | 65,118 |
| December 31 | 2021 | 75,325 |
| March 31 | 2022 | 68,011 |
| June 30 | 2022 | 69,685 |
| September 30 | 2022 | 69,092 |
| December 31 | 2022 | 76,048 |
| March 31 | 2023 | 69,787 |
| June 30 | 2023 | 74,604 |
| September 30 | 2023 | 76,693 |
| December 31 | 2023 | 86,310 |
| March 31 | 2024 | 80,539 |
| June 30 | 2024 | 84,742 |
| September 30 | 2024 | 88,268 |
**2. Revenue by Google Product/Service (in millions USD)**
**2021 Q1 - Q4**
| Quarter Ended | Google Search | YouTube Ads | Google Network | Google Other | Google Cloud | Other Bets |
|----------------|--------------|------------|---------------|-------------|-------------|-----------|
| March 31, 2021 | 31,879 | 6,005 | 6,800 | 6,494 | 4,047 | 198 |
| June 30, 2021 | 35,845 | 7,002 | 7,597 | 6,623 | 4,628 | 192 |
| Sept 30, 2021 | 37,926 | 7,205 | 7,999 | 6,754 | 4,990 | 182 |
| Dec 31, 2021 | 43,301 | 8,633 | 9,305 | 8,161 | 5,541 | 181 |
**2022 Q1 - Q4**
| Quarter Ended | Google Search | YouTube Ads | Google Network | Google Other | Google Cloud | Other Bets |
|----------------|--------------|------------|---------------|-------------|-------------|-----------|
| March 31, 2022 | 39,618 | 6,869 | 8,174 | 6,811 | 5,821 | 440 |
| June 30, 2022 | 40,689 | 7,340 | 8,259 | 6,553 | 6,276 | 193 |
| Sept 30, 2022 | 39,539 | 7,071 | 7,872 | 6,895 | 6,868 | 209 |
| Dec 31, 2022 | 42,604 | 7,963 | 8,475 | 8,796 | 7,315 | 226 |
**2023 Q1 - Q4**
| Quarter Ended | Google Search | YouTube Ads | Google Network | Google Other | Google Cloud | Other Bets |
|----------------|--------------|------------|---------------|-------------|-------------|-----------|
| March 31, 2023 | 40,359 | 6,693 | 7,496 | 7,413 | 7,454 | 288 |
| June 30, 2023 | 42,628 | 7,665 | 7,850 | 8,142 | 8,031 | 285 |
| Sept 30, 2023 | 44,026 | 7,952 | 7,669 | 8,339 | 8,411 | 297 |
| Dec 31, 2023 | 48,020 | 9,200 | 8,297 | 10,794 | 9,192 | 657 |
**2024 Q1 - Q3**
| Quarter Ended | Google Search | YouTube Ads | Google Network | Subscriptions, Platforms, & Devices | Google Cloud | Other Bets |
|----------------|--------------|------------|---------------|-----------------------------------|-------------|-----------|
| March 31, 2024 | 46,156 | 8,090 | 7,413 | 8,739 | 9,574 | 495 |
| June 30, 2024 | 48,509 | 8,663 | 7,444 | 9,312 | 10,347 | 365 |
| Sept 30, 2024 | 49,385 | 8,921 | 7,548 | 10,656 | 11,353 | 388 |Prompt: Using the tables generated, write matplotlib code to visualize these revenues, in bar chart format. On the x-axis, plot time (each of the 15 quarters in chronological order). On the y-axis, plot revenues -- total revenue and for each product and service for each time horizon. Do not leave code for the user to fill in. Leave out Other Bets, and ensure that the bars have equal spacing.

Prompt: Awesome! Now, can you generate a plot showing quarter on quarter revenue growth for each of the product areas? The x axis should be time (each of the 15 quarters) and the y axis should be the revenue percentage growth, and there should be 6 lines on the chart. Include variable values in the code even if they were defined previously. Exclude other bets.
Quarter on Quarter revenue growth is defined as ((revenue for current quarter)-(revenue for previous quarter))/(revenue for previous quarter).
You can use the Gemini 1.5 models to understand and extract information from ‘real world’ documents, such as receipts, labels, signs, notes, whiteboard sketches, personal records and many more. Here’s an example of Gemini extracting values for user-defined fields from an image of a receipt, and returning this as a JSON object.
Gemini models can extract data from screen captures of webpages, and return this data in structured output formats such as JSON. This enables accessing real-time page content as a human would see it, including images and video on webpages, enabling applications such as web data APIs and browsing agents.
Below is an example where Gemini converts information from this Google Play webpage into a structured output format.

Prompt: Extract each of the books from this webpage, and return a list of JSON objects, where each contains
Only output information that you see in the webpage
[
{
"name": "Warriors: A Starless Clan #6",
"author": "Erin Hunter",
"stars": null,
"price": "$14.95"
},
{
"name": "In Too Deep: A Reacher Novel",
"author": "Lee Child",
"stars": 4.7,
"price": "$16.95"
},
{
"name": "The Waiting: A Ballard and Bosch Novel",
"author": "Michael Connelly",
"stars": 4.8,
"price": "$16.95"
},
{
"name": "The Fury of the Gods",
"author": "John Gwynne",
"stars": 5.0,
"price": "$29.95"
},
{
"name": "Raised by Wolves: Patterson's Greatest Small-Town Thriller",
"author": "James Patterson",
"stars": null,
"price": "$14.95"
},
{
"name": "Iron Flame (1 of 2)",
"author": null,
"stars": 4.6,
"price": "$27.95"
},
{
"name": "The Message",
"author": "Ta-Nehisi Coates",
"stars": 4.9,
"price": "$14.95"
},
{
"name": "Revenge of the Tipping Point: Overstories, Superspreaders",
"author": "Malcolm Gladwell",
"stars": 4.6,
"price": "$14.95"
},
{
"name": "Counting Miracles: A Novel",
"author": "Nicholas Sparks",
"stars": 4.3,
"price": "$16.95"
},
{
"name": "Nexus: A Brief History of Information Networks from...",
"author": "Yuval Noah Harari",
"stars": 4.2,
"price": "$19.95"
},
{
"name": "Wind and Truth: Book Five of...",
"author": "Brandon Sanderson",
"stars": null,
"price": "$38.45"
},
{
"name": "Passions in Death: An Eve...",
"author": "J.D. Robb",
"stars": 4.5,
"price": "$14.95"
},
{
"name": "Sunrise on the Reaping (A Hunger Games Novel)",
"author": "Suzanne Collins",
"stars": null,
"price": "$19.95"
},
{
"name": "Michael Vey 10: The Colony",
"author": "Richard Paul Evans",
"stars": null,
"price": "$14.95"
},
{
"name": "The Echo Machine: How Right-Wing Extremism...",
"author": "David Pakman",
"stars": null,
"price": "$24.95"
},
{
"name": "The Perfect Crime (A Jessie...",
"author": null,
"stars": null,
"price": "$14.95"
},
{
"name": "Peppermint Peril (A Penny...",
"author": null,
"stars": null,
"price": "$4.99"
},
{
"name": "Lethal Prey",
"author": "John Sandford",
"stars": null,
"price": "$14.95"
},
{
"name": "The Song of Achilles: A Novel",
"author": "Madeline Miller",
"stars": 4.7,
"price": "$3.99"
},
{
"name": "A People's History of the United States",
"author": "Howard Zinn",
"stars": 4.1,
"price": "$4.99"
},
{
"name": "Termination Shock: A Novel",
"author": "Neal Stephenson",
"stars": 4.3,
"price": "$4.99"
},
{
"name": "Mere Christianity",
"author": "C.S. Lewis",
"stars": 4.8,
"price": "$4.99"
},
{
"name": "Local Woman Missing",
"author": "Mary Kubica",
"stars": 4.6,
"price": "$6.99"
},
{
"name": "Murder on the Orient Express: A Hercule Poirot Mystery",
"author": "Agatha Christie",
"stars": 4.4,
"price": "$4.99"
},
{
"name": "The Mountains Sing",
"author": "Nguyen Phan Que Mai",
"stars": 1.5,
"price": "$32.30"
},
{
"name": "The Bands of Mourning",
"author": "Brandon Sanderson",
"stars": 4.9,
"price": "$19.95"
},
{
"name": "The Institute: A Novel",
"author": "Stephen King",
"stars": 4.7,
"price": "$16.95"
},
{
"name": "Tom Lake: A Novel",
"author": "Ann Patchett",
"stars": 4.4,
"price": "$16.95"
},
{
"name": "All the Sinners Bleed: A Novel",
"author": "S.A. Cosby",
"stars": 4.7,
"price": "$14.95"
},
{
"name": "The Black Prism",
"author": "Brent Weeks",
"stars": 4.9,
"price": "$35.99"
},
{
"name": "The Hundred Years' War on Palestine: A History of Settle...",
"author": "Rashid Khalidi",
"stars": 4.6,
"price": "$14.95"
},
{
"name": "War",
"author": "Bob Woodward",
"stars": 3.7,
"price": "$14.95"
},
{
"name": "A People's History of the United States",
"author": "Howard Zinn",
"stars": 4.1,
"price": "$4.99"
},
{
"name": "Confronting the Presidents: No Spin Assessments from...",
"author": "Bill O'Reilly & Martin Dugard",
"stars": 4.8,
"price": "$19.95"
},
{
"name": "Chaos: Charles Manson, the CIA, and the Secret History o...",
"author": null,
"stars": 4.8,
"price": "$29.95"
},
{
"name": "The Demon of Unrest: A Saga of Hubris, Heartbreak, and...",
"author": "Erik Larson",
"stars": 3.1,
"price": "$19.95"
},
{
"name": "A Hidden Secret: A Kate Burkholder Short Story",
"author": "Linda Castillo",
"stars": 4.8,
"price": "$1.99"
},
{
"name": "MrBallen Presents: Strange, Dark & Mysterious: The...",
"author": null,
"stars": 5.0,
"price": "$13.95"
},
{
"name": "Angle of Investigation: Three Harry Bosch Stories",
"author": "Michael Connelly",
"stars": 4.4,
"price": "$12.95"
},
{
"name": "Cross Kill: An Alex Cross Story",
"author": "James Patterson",
"stars": 4.7,
"price": "$14.95"
},
{
"name": "Detective Cross",
"author": "James Patterson",
"stars": 4.6,
"price": "$14.95"
},
{
"name": "Blood Brothers: A Short Story Exclusive",
"author": "James Rollins",
"stars": 5.0,
"price": "$9.95"
}
]You can use Gemini to detect objects in an image and generate bounding box coordinates for them. Gemini’s object detection capabilities are particularly useful for visually grounding the model’s response back to the image, and provide added value over specialized models when required to reason and find objects based on user-defined criteria.
Here’s an example of object detection using Gemini 1.5 Pro:
Gemini detects each of the objects in the image and outputs bounding box coordinates in its response. The image below displays the bounding boxes (using this colab notebook).
Gemini can process videos up to 90 minutes long, including both visual frames and audio. With Gemini, you can:
Here is an example where we use Gemini to generate a video summary:
Prompt: Generate technical lecture notes for this video in a manner that would be understandable for a high school student. Make sure to follow these instructions:
Response:
Here are the technical lecture notes you requested:
# **Achieving Rapid Response Times in Large Online Services**
Jeff Dean, Google
## **Introduction**
Rapid response times of web applications are important for making them more interactive, fluid, and easy to use for the user. It’s often challenging to keep web apps performing quickly when there’s a large fanout, or the number of servers that need to be contacted in order to fulfill the user’s request. This can be seen in Google Search, where the results page often requires information from thousands of servers to create. This is made even more challenging when Google services are run in a shared environment, or on a large cluster of servers where many different services can be performed. This allows for an array of network issues like traffic congestion, background activity, and spikes in foreground activity for other services being carried out on the same server cluster.
When the latency of applications under these conditions is inspected, they exhibit what's referred to as long-tail latencies. Jeff used an amusing picture of himself on an African safari getting his shirt pulled by a cheetah to illustrate this concept. As he explained, long tail latency means that when you measure the latency of your application and find that it performs quickly on average, the 99th percentile latency could be very long. For example, if your server has a 10 ms average response time and a 99th percentile latency of 1 second, then if you have to get data from only one of those servers, 1% of requests will take more than a second. But when you have to get a response from 100 servers, 63% of your requests will take over a second, since at least one of the servers is likely to be experiencing this high latency.
## **Basic Latency Reduction Techniques**
Some common ways of dealing with these issues are:
* Differentiated service classes: Prioritizing interactive requests and their network traffic much higher than background requests, as this is less likely to affect the user experience if these requests lag.
* Reduce head-of-line blocking: Dividing large requests into many smaller requests to prevent lag for higher-priority requests waiting behind them.
* Manage expensive background activities: Rate-limiting background activities or delaying them until there’s less traffic on the servers, as these are usually not directly associated with a user request.
## **Fault Tolerance vs. Tolerating Variability**
The speaker drew an analogy to fault tolerance, a common hardware technique where unreliable parts of the system, like hard drives or a computer's power supply, are used to create a whole reliable system. By analogy, he wants to use unpredictable components that vary greatly in performance to create a predictable and high-performing system. Jeff pointed out that while both fault tolerance and tolerating variability use extra resources, the difference between the two is in the timescale of their variability. The issues that fault tolerance measures are on a scale of tens or hundreds of events per day, while latency tolerance measures thousands of events per second.
## **Latency Tolerating Techniques**
Here are two techniques that Jeff describes for minimizing variability in latency:
### Cross Request Adaptation
* Collect statistics on the system. This could include latency rates, performance of backends, etc.
* Take action to improve the latency of future requests, for example, by load balancing.
* Timescale for these kinds of actions are generally on the order of tens of seconds to minutes.
### Within-Request Adaptation
* Within a single high-level request, cope with slow subsystems.
* Timescale for these kinds of actions are generally immediate, while the user is waiting for a request to be fulfilled.
## **Fine-Grained Dynamic Partitioning**
One cross request adaption technique that Jeff discussed was fine-grained dynamic partitioning. Normally, if you have ‘n’ servers, you could simply divide the workload into ‘n’ equal pieces, and each server can deal with one piece each, assuming that there’s no shared environment where other things can happen. But once you have a shared environment, the load becomes unpredictable and can result in a server getting overloaded. In the case of a shared environment, it’s recommended to have a server dealing with 10–100 different pieces of work. This allows for very fine-grain load balancing, because if one server is overloaded, one of those pieces of work can be assigned to another server. Another reason for doing this is that it speeds up failure recovery, because when a server dies, whatever it was responsible for is distributed to other machines, and if the workload has been divided into ‘n’ smaller tasks, this recovery process can happen in ‘n’ separate ways simultaneously.
## **Selective Replication**
Another technique often used by Google is called selective replication, where heavily-used pieces of information in the system are copied to other server clusters. This can be static, where the number of copies is fixed, or dynamic, where the number of copies of a piece of information is increased or decreased depending on the amount of traffic there is in requests associated with that information.
## **Latency-Induced Probation**
A third technique that Jeff described for dealing with unpredictable latency and interference effects from shared services was what he calls latency-induced probation, or the concept of removing capacity under load to improve latency. The steps for this are:
* Recognize that a server is slow to respond, even if it is a high priority server.
* Make a copy of the data in question on another server.
* Send a “shadow stream” of requests to the slow server. These requests are similar to “canary requests” in that they serve as a check to make sure the server is functioning.
* Once the latency of the slow server has gone down and the “canary” checks show it working, return it to service.
## **Backup Requests**
Another technique for minimizing latency variability is the use of backup requests, where a client sends a copy of the same request to two or more server clusters in order to improve latency. If one of the servers selected returns the data faster, the client sends a cancellation request for the duplicate request in the other server queue, if it’s possible to maintain information about where the original request was sent. However, the disadvantage of this is that it can double the processing required if two servers begin processing the request at about the same time. In the latter case, the client needs to check if the issue of simultaneous processing occurred, and if so, to send only one copy of the requested data.
The speaker then measured the improvement in latency using two different systems. The first was a loaded server cluster where data was replicated in two in-memory servers, and 1000 requests were spread across 100 tablets. The speaker measured the time it took for all 1000 keys to be retrieved. The second measurement used an almost completely idle system, but with the same parameters: data was replicated in two in-memory servers, 1000 requests were sent across 100 tablets, and the total retrieval time for all 1000 keys was measured. In both cases, backup requests reduced latency dramatically. The results for both loaded and idle servers, respectively, are shown in the tables below:
### Loaded cluster results:
| Policy | Avg | Std Dev | 95%ile | 99%ile | 99.9%ile |
| ------------- |:--------:|:-------:|:------:|:------:|:--------:|
| No backups | 33 ms | 1524 ms| 24 ms | 52 ms | 994 ms |
| Backup after 10 ms | 14 ms | 4 ms | 20 ms | 23 ms | 50 ms |
| Backup after 50 ms | 16 ms | 12 ms | 57 ms | 63 ms | 68 ms |
### Idle cluster results:
| Policy | 50%ile | 90%ile | 99%ile | 99.9%ile |
| ------------- |:--------:|:-------:|:------:|:--------:|
| No backups | 19 ms | 38 ms | 67 ms | 98 ms |
| Backup after 2 ms | 16 ms | 28 ms | 38 ms | 51 ms |
## Conclusion
These techniques can make online services more responsive and can dramatically cut down on processing time and costs.Gemini is able to extract information from videos and output it in structured formats, such as lists, tables and JSON objects. This is especially useful for tasks such as cataloging, detecting entities in domains such as retail, traffic and home security, unstructured data extraction from screen-recordings, and many more.
Note: Due to 1FPS sampling, the model can occasionally miss items in videos. We are working on enabling higher FPS sampling for videos soon. Therefore, for now we recommend verifying outputs for these use cases if needed, but we want to show glimpses of what we are working towards and where our models will be in the coming months.
To start building with vision in the Gemini API, visit our developer guide to get started. You can also join our developer forum to meet other builders and discuss your use cases & get help from Gemini API team members.

Enable on-demand expertise with Agent Skills in Genkit Go

Run Ray on TPU, Part 2: Ray AI libraries

Agent and Model Evaluations in Gemini Enterprise Agent Platform are now GA

Turn creative prompts into interactive XR experiences with Gemini

How we built the Google I/O 2026 Save the Date experience