Gemini의 네이티브 멀티모달 및 긴 컨텍스트 기능은 NotebookLM과 Google 렌즈, 그 밖에 다양한 앱에서 성능을 강화하고, 개발자를 위해 다양하고 참신한 애플리케이션의 가능성을 열어주었습니다.
이 블로그 게시물에서는 Gemini API의 이미지 및 동영상 입력에 대해 가장 기대되는 몇 가지 사용 사례를 집중 조명합니다. 이 게시물을 통해 비전 기능으로 개발할 수 있는 앱에 대한 새로운 아이디어를 떠올릴 수 있기를 바랍니다. 여기서 보여주는 예는 이미지 및 동영상 이해 애플리케이션을 위한 가장 강력한 성능의 모델인 Gemini 1.5 Pro를 사용했지만, 작업의 복잡성에 따라 1.5 Flash 및 1.5 Flash-8B(실험용 모델도 포함!)를 사용해 보시는 것도 좋습니다.
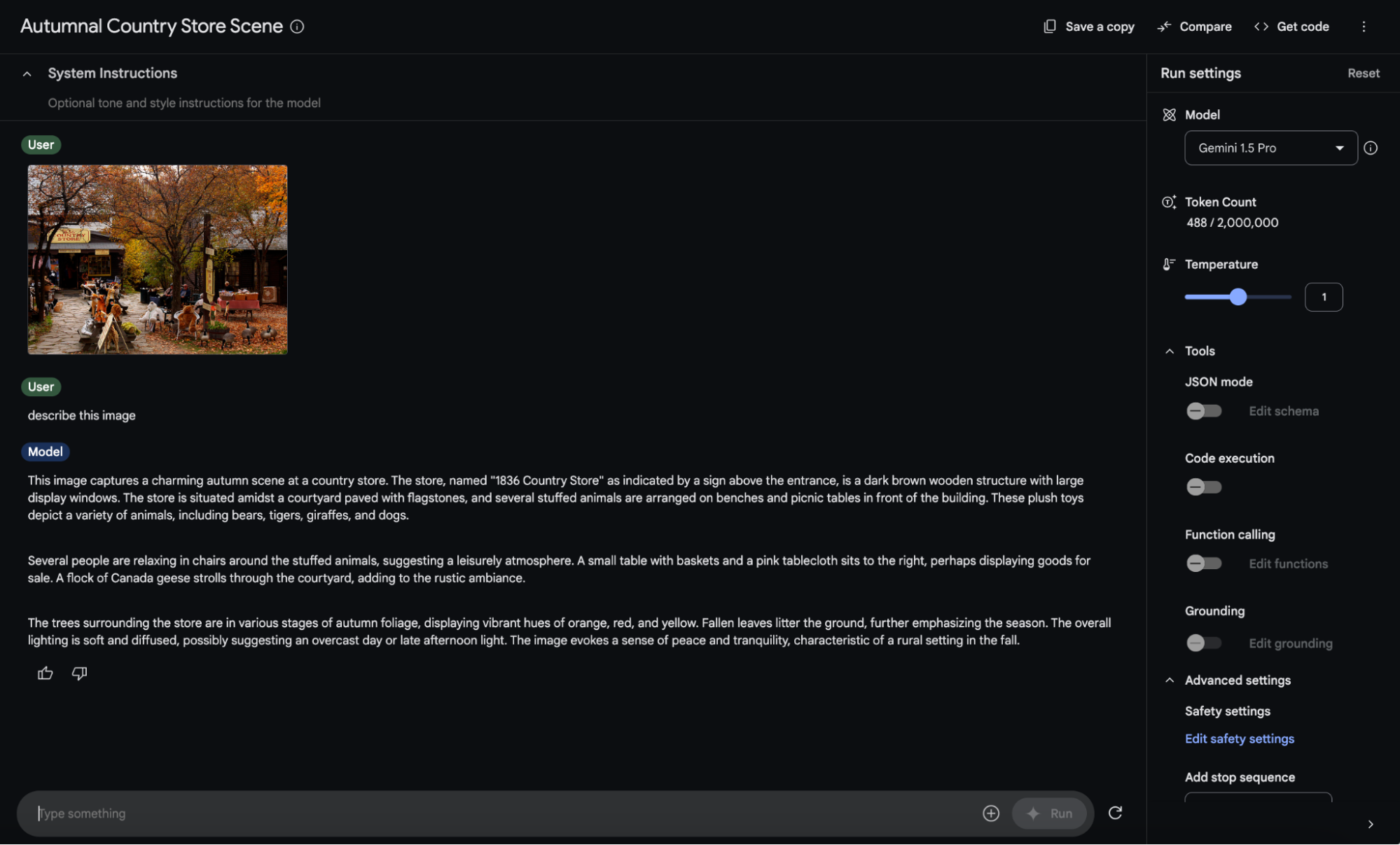
Gemini 모델은 이미지에 대해 설명하고 관련 질문에 답하고 추론할 수 있습니다. Gemini 모델은 프롬프트에 따라 설명의 길이, 어조, 형식을 조정하므로 사용 사례에 대한 모델 동작을 조정할 수 있습니다.
Gemini는 1,000페이지가 넘는 PDF 문서를 이해하고 처리할 수 있습니다. Gemini는 네이티브 비전 기능으로 표를 정확하게 기록하고, 복잡한 다중 열 레이아웃을 해석하고, 문서 내의 차트, 스케치, 다이어그램, 손글씨를 이해하며, 이러한 글씨와 시각 정보를 사용하여 엔드투엔드 작업을 수행할 수 있습니다.
다음은 Gemini가 일련의 PDF에서 얻은 정보를 사용하여 구조화된 출력과 코드를 생성하는 예시입니다.
2024년 3분기까지 Alphabet의 실적 공개 자료 15건(총 152페이지)을 Gemini에 제공하면서 이 문서에서 Google의 수익 관련 수치를 추출하고, 이 데이터를 집계하는 표를 만든 다음, matplotlib를 사용하여 수익과 분기별 성장을 시각화하는 코드를 작성해 달라고 요청했습니다.
프롬프트:
다음은 지난 15개 분기 동안의 수익 보고서입니다.
2. 각 분기(총 15개 분기)에 대한 각 Google 제품/서비스(예: 'Google 검색', 'Youtube 광고', 'Google 네트워크', 'Google 구독, 플랫폼 및 기기', 'Google Cloud', '신사업')의 총 수익 표를 생성해 주세요. 출력할 때는 여러 개의 표(표 하나 당 4개 분기)로 표시하세요. 참고로, 2023년 3분기 이전에는 Google 구독, 플랫폼 및 기기를 'Google 기타'라고 칭했습니다.
응답:
요청하신 표는 다음과 같습니다.
**1. 분기별 총수익(단위: 백만 달러)**
| 분기 마감일 | 연도 | 총수익 |
|-------------------|------|--------------|
| 3월 31일 | 2021 | 55,314 |
| 6월 30일 | 2021 | 61,880 |
| 9월 30일 | 2021 | 65,118 |
| 12월 31일 | 2021 | 75,325 |
| 3월 31일 | 2022 | 68,011 |
| 6월 30일 | 2022 | 69,685 |
| 9월 30일 | 2022 | 69,092 |
| 12월 31일 | 2022 | 76,048 |
| 3월 31일 | 2023 | 69,787 |
| 6월 30일 | 2023 | 74,604 |
| 9월 30일 | 2023 | 76,693 |
| 12월 31일 | 2023 | 86,310 |
| 3월 31일 | 2024 | 80,539 |
| 6월 30일 | 2024 | 84,742 |
| 9월 30일 | 2024 | 88,268 |
**2. Google 제품/서비스별 수익(단위: 백만 달러)**
**2021 Q1 - Q4**
| 분기 마감일 | Google 검색 | YouTube 광고 | Google 네트워크 | Google Other | Google Cloud | 신사업 |
|----------------|--------------|------------|---------------|-------------|-------------|-----------|
| 2021년 3월 31일 | 31,879 | 6,005 | 6,800 | 6,494 | 4,047 | 198 |
| 2021년 6월 30일 | 35,845 | 7,002 | 7,597 | 6,623 | 4,628 | 192 |
| 2021년 9월 30일 | 37,926 | 7,205 | 7,999 | 6,754 | 4,990 | 182 |
| 2021년 12월 31일 | 43,301 | 8,633 | 9,305 | 8,161 | 5,541 | 181 |
**2022 Q1 - Q4**
| 분기 마감일 | Google 검색 | YouTube 광고 | Google 네트워크 | Google Other | Google Cloud | 신사업 |
|----------------|--------------|------------|---------------|-------------|-------------|-----------|
| 2022년 3월 31일 | 39,618 | 6,869 | 8,174 | 6,811 | 5,821 | 440 |
| 2022년 6월 30일 | 40,689 | 7,340 | 8,259 | 6,553 | 6,276 | 193 |
| 2022년 9월 30일 | 39,539 | 7,071 | 7,872 | 6,895 | 6,868 | 209 |
| 2022년 12월 31일 | 42,604 | 7,963 | 8,475 | 8,796 | 7,315 | 226 |
**2023 Q1 - Q4**
| 분기 마감일 | Google 검색 | YouTube 광고 | Google 네트워크 | Google Other | Google Cloud | 신사업 |
|----------------|--------------|------------|---------------|-------------|-------------|-----------|
| 2023년 3월 31일 | 40,359 | 6,693 | 7,496 | 7,413 | 7,454 | 288 |
| 2023년 6월 30일 | 42,628 | 7,665 | 7,850 | 8,142 | 8,031 | 285 |
| 2023년 9월 30일 | 44,026 | 7,952 | 7,669 | 8,339 | 8,411 | 297 |
| 2023년 12월 31일 | 48,020 | 9,200 | 8,297 | 10,794 | 9,192 | 657 |
**2024 Q1 - Q3**
| 분기 마감일 | Google 검색 | YouTube 광고 | Google 네트워크 | 구독, 플랫폼 및 기기 | Google Cloud | 신사업 |
|----------------|--------------|------------|---------------|-----------------------------------|-------------|-----------|
| 2024년 3월 31일 | 46,156 | 8,090 | 7,413 | 8,739 | 9,574 | 495 |
| 2024년 6월 30일 | 48,509 | 8,663 | 7,444 | 9,312 | 10,347 | 365 |
| 2024년 9월 30일 | 49,385 | 8,921 | 7,548 | 10,656 | 11,353 | 388 |프롬프트: 생성된 표를 사용하여 matplotlib 코드를 작성해서 이러한 수익을 막대 차트 형식으로 시각화하세요. x축에는 시간(15개 분기를 시간 순으로 표시)을 플로팅하고, y축에는 총수익 및 각 시간대에서 각각의 제품과 서비스에 대한 수익을 플로팅해 주세요. 사용자가 입력해야 할 코드를 남기지 마세요. '신사업' 분야는 제외하고, 막대의 간격이 동일하도록 해주세요.

프롬프트: 훌륭합니다! 이제 각 제품 영역에 대해 분기별 수익 성장을 보여주는 플롯을 생성할 수 있습니까? x축은 시간(각 15개 분기), y축은 백분율로 나타낸 수익 성장률이어야 하며, 차트에는 6개의 선이 있어야 합니다. 이전에 정의되었던 변수의 값이라도 코드에 포함해 주세요. '신사업' 분야는 제외해 주세요.
직전 분기 대비 수익 성장은 ((당해 분기 수익) - (이전 분기 수익))/(이전 분기 수익)으로 정의됩니다.
영수증, 라벨, 표지판, 메모, 화이트보드 스케치, 개인 기록 등 ‘실제’ 문서에서 정보를 이해하고 추출하는 데 Gemini 1.5 모델을 사용할 수 있습니다. 다음은 Gemini가 영수증 이미지에서 사용자 정의 필드 값을 추출하고 이를 JSON 객체로 반환하는 예입니다.
Gemini 모델은 웹페이지의 화면 캡처에서 데이터를 추출하여 이 데이터를 JSON과 같이 구조화된 출력 형식으로 반환할 수 있습니다. 이를 통해 웹페이지의 이미지와 동영상을 포함하여 사람이 보는 것처럼 실시간 페이지 콘텐츠에 액세스할 수 있고 덕분에 웹 데이터 API 및 브라우징 에이전트 같은 애플리케이션을 사용할 수 있습니다.
다음은 Gemini가 이 Google Play 웹페이지의 정보를 구조화된 출력 형식으로 변환하는 예입니다.

프롬프트: 이 웹페이지에서 각 도서를 추출하고 다음이 각각 포함된 JSON 객체 목록을 반환해 주세요.
웹페이지에 표시되는 정보만 출력해 주세요.
[
{
"name": "Warriors: A Starless Clan #6",
"author": "Erin Hunter",
"stars": null,
"price": "$14.95"
},
{
"name": "In Too Deep: A Reacher Novel",
"author": "Lee Child",
"stars": 4.7,
"price": "$16.95"
},
{
"name": "The Waiting: A Ballard and Bosch Novel",
"author": "Michael Connelly",
"stars": 4.8,
"price": "$16.95"
},
{
"name": "The Fury of the Gods",
"author": "John Gwynne",
"stars": 5.0,
"price": "$29.95"
},
{
"name": "Raised by Wolves: Patterson's Greatest Small-Town Thriller",
"author": "James Patterson",
"stars": null,
"price": "$14.95"
},
{
"name": "Iron Flame (1 of 2)",
"author": null,
"stars": 4.6,
"price": "$27.95"
},
{
"name": "The Message",
"author": "Ta-Nehisi Coates",
"stars": 4.9,
"price": "$14.95"
},
{
"name": "Revenge of the Tipping Point: Overstories, Superspreaders",
"author": "Malcolm Gladwell",
"stars": 4.6,
"price": "$14.95"
},
{
"name": "Counting Miracles: A Novel",
"author": "Nicholas Sparks",
"stars": 4.3,
"price": "$16.95"
},
{
"name": "Nexus: A Brief History of Information Networks from...",
"author": "Yuval Noah Harari",
"stars": 4.2,
"price": "$19.95"
},
{
"name": "Wind and Truth: Book Five of...",
"author": "Brandon Sanderson",
"stars": null,
"price": "$38.45"
},
{
"name": "Passions in Death: An Eve...",
"author": "J.D. Robb",
"stars": 4.5,
"price": "$14.95"
},
{
"name": "Sunrise on the Reaping (A Hunger Games Novel)",
"author": "Suzanne Collins",
"stars": null,
"price": "$19.95"
},
{
"name": "Michael Vey 10: The Colony",
"author": "Richard Paul Evans",
"stars": null,
"price": "$14.95"
},
{
"name": "The Echo Machine: How Right-Wing Extremism...",
"author": "David Pakman",
"stars": null,
"price": "$24.95"
},
{
"name": "The Perfect Crime (A Jessie...",
"author": null,
"stars": null,
"price": "$14.95"
},
{
"name": "Peppermint Peril (A Penny...",
"author": null,
"stars": null,
"price": "$4.99"
},
{
"name": "Lethal Prey",
"author": "John Sandford",
"stars": null,
"price": "$14.95"
},
{
"name": "The Song of Achilles: A Novel",
"author": "Madeline Miller",
"stars": 4.7,
"price": "$3.99"
},
{
"name": "A People's History of the United States",
"author": "Howard Zinn",
"stars": 4.1,
"price": "$4.99"
},
{
"name": "Termination Shock: A Novel",
"author": "Neal Stephenson",
"stars": 4.3,
"price": "$4.99"
},
{
"name": "Mere Christianity",
"author": "C.S. Lewis",
"stars": 4.8,
"price": "$4.99"
},
{
"name": "Local Woman Missing",
"author": "Mary Kubica",
"stars": 4.6,
"price": "$6.99"
},
{
"name": "Murder on the Orient Express: A Hercule Poirot Mystery",
"author": "Agatha Christie",
"stars": 4.4,
"price": "$4.99"
},
{
"name": "The Mountains Sing",
"author": "Nguyen Phan Que Mai",
"stars": 1.5,
"price": "$32.30"
},
{
"name": "The Bands of Mourning",
"author": "Brandon Sanderson",
"stars": 4.9,
"price": "$19.95"
},
{
"name": "The Institute: A Novel",
"author": "Stephen King",
"stars": 4.7,
"price": "$16.95"
},
{
"name": "Tom Lake: A Novel",
"author": "Ann Patchett",
"stars": 4.4,
"price": "$16.95"
},
{
"name": "All the Sinners Bleed: A Novel",
"author": "S.A. Cosby",
"stars": 4.7,
"price": "$14.95"
},
{
"name": "The Black Prism",
"author": "Brent Weeks",
"stars": 4.9,
"price": "$35.99"
},
{
"name": "The Hundred Years' War on Palestine: A History of Settle...",
"author": "Rashid Khalidi",
"stars": 4.6,
"price": "$14.95"
},
{
"name": "War",
"author": "Bob Woodward",
"stars": 3.7,
"price": "$14.95"
},
{
"name": "A People's History of the United States",
"author": "Howard Zinn",
"stars": 4.1,
"price": "$4.99"
},
{
"name": "Confronting the Presidents: No Spin Assessments from...",
"author": "Bill O'Reilly & Martin Dugard",
"stars": 4.8,
"price": "$19.95"
},
{
"name": "Chaos: Charles Manson, the CIA, and the Secret History o...",
"author": null,
"stars": 4.8,
"price": "$29.95"
},
{
"name": "The Demon of Unrest: A Saga of Hubris, Heartbreak, and...",
"author": "Erik Larson",
"stars": 3.1,
"price": "$19.95"
},
{
"name": "A Hidden Secret: A Kate Burkholder Short Story",
"author": "Linda Castillo",
"stars": 4.8,
"price": "$1.99"
},
{
"name": "MrBallen Presents: Strange, Dark & Mysterious: The...",
"author": null,
"stars": 5.0,
"price": "$13.95"
},
{
"name": "Angle of Investigation: Three Harry Bosch Stories",
"author": "Michael Connelly",
"stars": 4.4,
"price": "$12.95"
},
{
"name": "Cross Kill: An Alex Cross Story",
"author": "James Patterson",
"stars": 4.7,
"price": "$14.95"
},
{
"name": "Detective Cross",
"author": "James Patterson",
"stars": 4.6,
"price": "$14.95"
},
{
"name": "Blood Brothers: A Short Story Exclusive",
"author": "James Rollins",
"stars": 5.0,
"price": "$9.95"
}
]Gemini를 사용하여 이미지의 객체를 탐지하고 해당 객체에 대한 경계 상자 좌표를 생성할 수 있습니다. Gemini의 객체 탐지 기능은 이미지에 대한 모델의 응답을 시각적으로 그라운딩하는 데 특히 유용하며, 사용자가 정의한 기준에 따라 객체를 추론하고 찾아야 할 경우 전문적인 모델보다 큰 부가가치를 제공합니다.
다음은 Gemini 1.5 Pro를 사용한 객체 탐지의 예입니다.
Gemini는 이미지의 각 객체를 탐지하고 응답에서 경계 상자 좌표를 출력합니다. 아래 이미지는 경계 상자를 표시합니다(이 colab 노트북 사용).
Gemini는 비주얼 프레임과 오디오를 포함하여 최대 90분 길이의 동영상을 처리할 수 있습니다. Gemini를 사용하면 다음을 수행할 수 있습니다.
다음은 Gemini를 사용하여 동영상 요약을 생성하는 예입니다.
프롬프트: 고등학생이 이해할 수 있는 방식으로 이 동영상에 대한 기술 강의 노트를 생성해 주세요. 다음 지시 사항을 지켜주세요.
응답:
Here are the technical lecture notes you requested:
# **Achieving Rapid Response Times in Large Online Services**
Jeff Dean, Google
## **Introduction**
Rapid response times of web applications are important for making them more interactive, fluid, and easy to use for the user. It’s often challenging to keep web apps performing quickly when there’s a large fanout, or the number of servers that need to be contacted in order to fulfill the user’s request. This can be seen in Google Search, where the results page often requires information from thousands of servers to create. This is made even more challenging when Google services are run in a shared environment, or on a large cluster of servers where many different services can be performed. This allows for an array of network issues like traffic congestion, background activity, and spikes in foreground activity for other services being carried out on the same server cluster.
When the latency of applications under these conditions is inspected, they exhibit what's referred to as long-tail latencies. Jeff used an amusing picture of himself on an African safari getting his shirt pulled by a cheetah to illustrate this concept. As he explained, long tail latency means that when you measure the latency of your application and find that it performs quickly on average, the 99th percentile latency could be very long. For example, if your server has a 10 ms average response time and a 99th percentile latency of 1 second, then if you have to get data from only one of those servers, 1% of requests will take more than a second. But when you have to get a response from 100 servers, 63% of your requests will take over a second, since at least one of the servers is likely to be experiencing this high latency.
## **Basic Latency Reduction Techniques**
Some common ways of dealing with these issues are:
* Differentiated service classes: Prioritizing interactive requests and their network traffic much higher than background requests, as this is less likely to affect the user experience if these requests lag.
* Reduce head-of-line blocking: Dividing large requests into many smaller requests to prevent lag for higher-priority requests waiting behind them.
* Manage expensive background activities: Rate-limiting background activities or delaying them until there’s less traffic on the servers, as these are usually not directly associated with a user request.
## **Fault Tolerance vs. Tolerating Variability**
The speaker drew an analogy to fault tolerance, a common hardware technique where unreliable parts of the system, like hard drives or a computer's power supply, are used to create a whole reliable system. By analogy, he wants to use unpredictable components that vary greatly in performance to create a predictable and high-performing system. Jeff pointed out that while both fault tolerance and tolerating variability use extra resources, the difference between the two is in the timescale of their variability. The issues that fault tolerance measures are on a scale of tens or hundreds of events per day, while latency tolerance measures thousands of events per second.
## **Latency Tolerating Techniques**
Here are two techniques that Jeff describes for minimizing variability in latency:
### Cross Request Adaptation
* Collect statistics on the system. This could include latency rates, performance of backends, etc.
* Take action to improve the latency of future requests, for example, by load balancing.
* Timescale for these kinds of actions are generally on the order of tens of seconds to minutes.
### Within-Request Adaptation
* Within a single high-level request, cope with slow subsystems.
* Timescale for these kinds of actions are generally immediate, while the user is waiting for a request to be fulfilled.
## **Fine-Grained Dynamic Partitioning**
One cross request adaption technique that Jeff discussed was fine-grained dynamic partitioning. Normally, if you have ‘n’ servers, you could simply divide the workload into ‘n’ equal pieces, and each server can deal with one piece each, assuming that there’s no shared environment where other things can happen. But once you have a shared environment, the load becomes unpredictable and can result in a server getting overloaded. In the case of a shared environment, it’s recommended to have a server dealing with 10–100 different pieces of work. This allows for very fine-grain load balancing, because if one server is overloaded, one of those pieces of work can be assigned to another server. Another reason for doing this is that it speeds up failure recovery, because when a server dies, whatever it was responsible for is distributed to other machines, and if the workload has been divided into ‘n’ smaller tasks, this recovery process can happen in ‘n’ separate ways simultaneously.
## **Selective Replication**
Another technique often used by Google is called selective replication, where heavily-used pieces of information in the system are copied to other server clusters. This can be static, where the number of copies is fixed, or dynamic, where the number of copies of a piece of information is increased or decreased depending on the amount of traffic there is in requests associated with that information.
## **Latency-Induced Probation**
A third technique that Jeff described for dealing with unpredictable latency and interference effects from shared services was what he calls latency-induced probation, or the concept of removing capacity under load to improve latency. The steps for this are:
* Recognize that a server is slow to respond, even if it is a high priority server.
* Make a copy of the data in question on another server.
* Send a “shadow stream” of requests to the slow server. These requests are similar to “canary requests” in that they serve as a check to make sure the server is functioning.
* Once the latency of the slow server has gone down and the “canary” checks show it working, return it to service.
## **Backup Requests**
Another technique for minimizing latency variability is the use of backup requests, where a client sends a copy of the same request to two or more server clusters in order to improve latency. If one of the servers selected returns the data faster, the client sends a cancellation request for the duplicate request in the other server queue, if it’s possible to maintain information about where the original request was sent. However, the disadvantage of this is that it can double the processing required if two servers begin processing the request at about the same time. In the latter case, the client needs to check if the issue of simultaneous processing occurred, and if so, to send only one copy of the requested data.
The speaker then measured the improvement in latency using two different systems. The first was a loaded server cluster where data was replicated in two in-memory servers, and 1000 requests were spread across 100 tablets. The speaker measured the time it took for all 1000 keys to be retrieved. The second measurement used an almost completely idle system, but with the same parameters: data was replicated in two in-memory servers, 1000 requests were sent across 100 tablets, and the total retrieval time for all 1000 keys was measured. In both cases, backup requests reduced latency dramatically. The results for both loaded and idle servers, respectively, are shown in the tables below:
### Loaded cluster results:
| Policy | Avg | Std Dev | 95%ile | 99%ile | 99.9%ile |
| ------------- |:--------:|:-------:|:------:|:------:|:--------:|
| No backups | 33 ms | 1524 ms| 24 ms | 52 ms | 994 ms |
| Backup after 10 ms | 14 ms | 4 ms | 20 ms | 23 ms | 50 ms |
| Backup after 50 ms | 16 ms | 12 ms | 57 ms | 63 ms | 68 ms |
### Idle cluster results:
| Policy | 50%ile | 90%ile | 99%ile | 99.9%ile |
| ------------- |:--------:|:-------:|:------:|:--------:|
| No backups | 19 ms | 38 ms | 67 ms | 98 ms |
| Backup after 2 ms | 16 ms | 28 ms | 38 ms | 51 ms |
## Conclusion
These techniques can make online services more responsive and can dramatically cut down on processing time and costs.Gemini는 동영상에서 정보를 추출하여 목록, 테이블 및 JSON 객체와 같은 구조화된 형식으로 출력할 수 있습니다. 이는 카탈로그 작성, 소매업, 교통 및 주택 보안과 같은 도메인의 엔터티 감지, 화면 녹화에서 구조화되지 않은 데이터 추출 등의 작업에 특히 유용합니다.
참고: 1FPS 샘플링으로 인해 모델이 동영상의 항목을 놓치는 상황이 발생할 있습니다. 그래서 곧 동영상에 대해 더 높은 FPS 샘플링을 지원하기 위해 노력하고 있습니다. 따라서 지금으로서는 필요한 경우에 이러한 사용 사례에 대한 출력을 확인하는 것이 좋지만, 저희가 어떤 목표를 위해 노력 중이며 앞으로 몇 달 후에는 모델이 어느 정도로 발전할지 살짝 보여드리고자 합니다.
Gemini API에서 비전으로 개발을 시작하려면 개발자 가이드를 참조하세요. 개발자 포럼에 참여하여 다른 빌더들을 만나고 사용 사례에 대해 논의하고 Gemini API 팀원의 도움을 받을 수도 있습니다.