

我们很高兴推出 EmbeddingGemma,这是一款全新开放式嵌入模型,在同一尺寸量级的模型中能提供一流性能。该模型专为设备端 AI 设计,其 308M 参数的设计紧凑高效,让您可以使用直接在硬件上运行的技术(例如 RAG 和语义搜索等)构建应用。该模型提供私密、高质量的嵌入向量。即使没有连接互联网,您也可以在任何地方使用这些嵌入向量。
Link to Youtube Video (visible only when JS is disabled)
EmbeddingGemma 可生成嵌入向量。这些嵌入向量是数字表征,在本例中,它们是文本(例如句子和文档)的数字表征。该模型生成嵌入向量的方式是将文本转换为数字向量,以便在高维空间中表达一定含义。嵌入向量的质量越好,对语言及其所有细微差别和复杂性的表征也越详细和准确。
构建 RAG 流水线时,有两个关键阶段:根据用户的输入检索相关上下文,并生成基于该上下文的回答。要执行检索,您可以生成用户提示的嵌入向量,并计算与系统上所有文档的嵌入向量之间的相似度。这样您就可以获取与用户查询最相关的段落。然后,系统可以将这些段落与原始用户查询一起传递给生成式模型(如 Gemma 3),使其生成与上下文相关的回答,例如模型理解到您需要木工的电话来联系木工师傅,维修损坏的地板。
为实现有效的 RAG 流水线,初始检索步骤的质量至关重要。低质量嵌入向量会导致检索不相关的文档,进而输出不准确或荒谬的答案。该步骤正是 EmbeddingGemma 展现性能的高光时刻,它能提供高质量表征,为打造准确可靠的设备端应用提供支持。
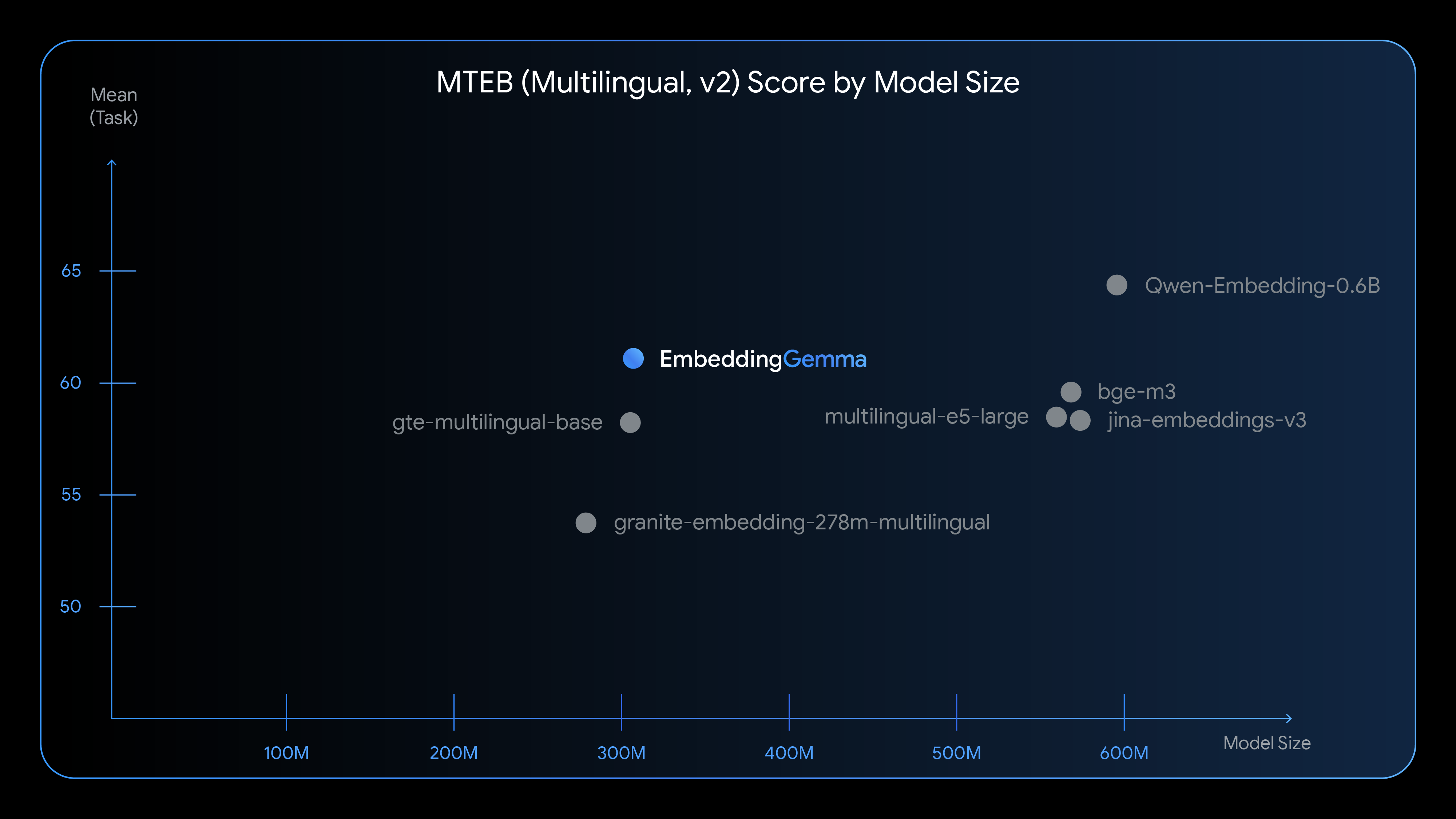
EmbeddingGemma 提供同等尺寸下最先进的文本理解性能,在生成多语言嵌入向量方面表现尤为出色。
查看 EmbeddingGemma 与其他热门嵌入模型的比较:
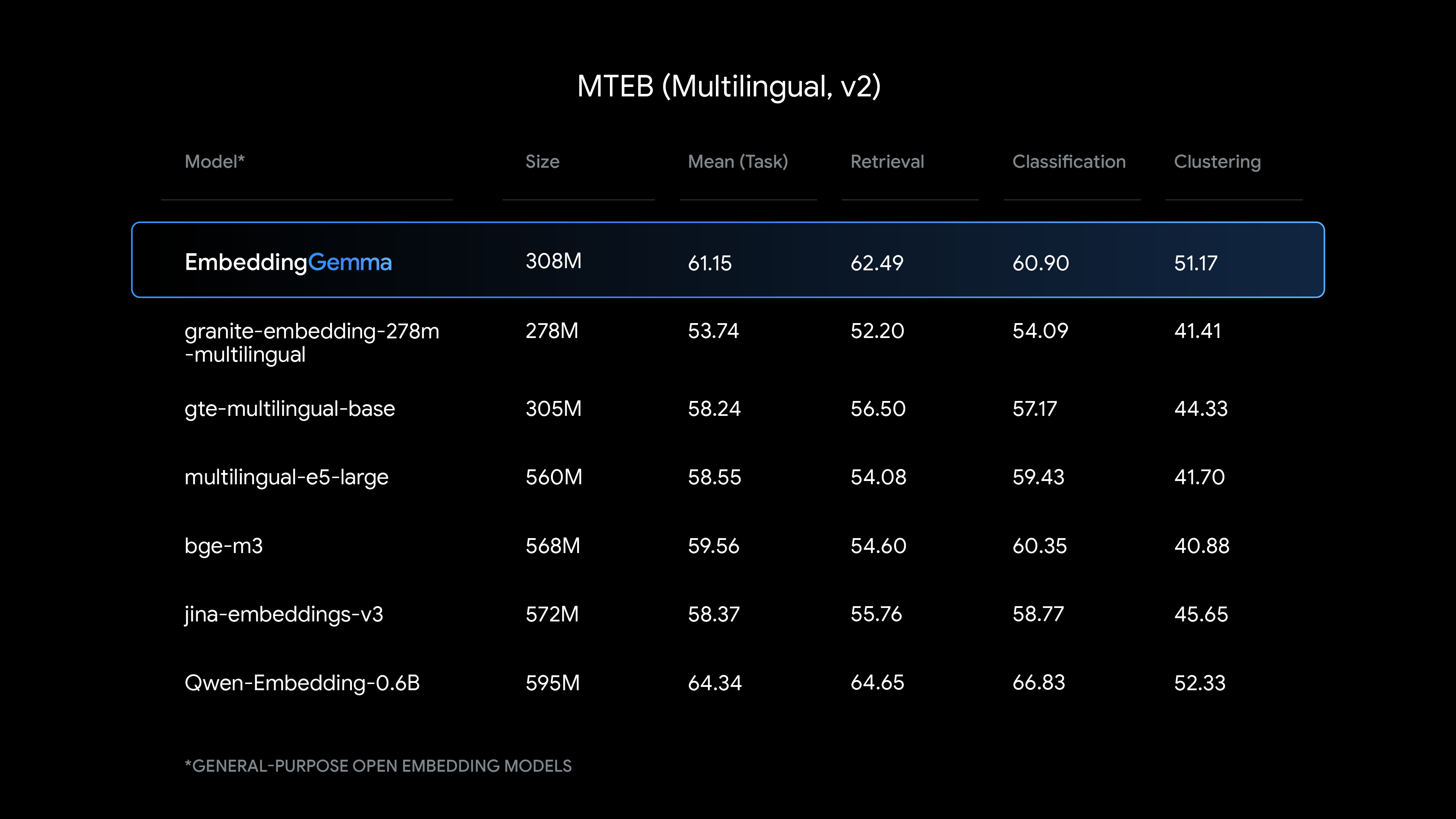
在该模型的 308M 参数中,约有 100M 为模型参数,200M 为嵌入向量参数。其设计注重提供良好性能,并最小化资源消耗。
EmbeddingGemma 使开发者能够在设备端构建灵活且注重隐私的应用。该模型直接在设备硬件上生成文档嵌入向量,有助于确保敏感用户数据的安全。它使用与 Gemma 3n 相同的分词器处理文本,减少了 RAG 应用的内存占用。运用 EmbeddingGemma 可解锁新功能,例如:
如果这些示例没有涵盖您的需求,请使用我们的快速入门笔记本,进一步微调 EmbeddingGemma,使其可用于特定领域、任务或特定语言。
我们的目标是提供满足您需求的最佳工具。此次发布 EmbeddingGemma 后,您便拥有了适用于任何应用的嵌入模型。
我们从一开始就把可访问性作为 EmbeddingGemma 的优先事项,并与开发者合作,让各热门平台和框架支持使用该模型。现在起,您可以体验为 Google 第一方平台(如 Android)提供支持的强大技术,并使用您熟悉的工具开始构建应用。

隆重推出 Gemma 3 270M:超高效的紧凑型 AI 模型

隆重推出 Veo 3.1 和 Gemini API 中的全新创意功能

Chrome、Chromebook Plus 和 Pixel Watch 中采用 LiteRT-LM 的设备端生成式 AI

Google AI Edge Gallery:现已支持音频并在 Google Play 上架
隆重推出 Coral NPU:适用于边缘 AI 的全栈平台

T5Gemma:全新 Encoder-Decoder 架构的 Gemma 模型系列