

We're excited to introduce EmbeddingGemma, a new open embedding model that delivers best-in-class performance for its size. Designed specifically for on-device AI, its highly efficient 308 million parameter design enables you to build applications using techniques such as Retrieval Augmented Generation (RAG) and semantic search that run directly on your hardware. It delivers private, high-quality embeddings that work anywhere, even without an internet connection.
Link to Youtube Video (visible only when JS is disabled)
EmbeddingGemma generates embeddings, which are numerical representations - in this case, of text (such as sentences and documents) - by transforming it into a vector of numbers to represent meaning in a high-dimensional space. The better the embeddings, the better the representation of language, with all its nuances and complexities.
When building a RAG pipeline, you have two key stages: retrieving relevant context based on a user’s input and generating answers grounded on that context. To perform the retrieval, you can generate the embedding of a user’s prompt and calculate the similarity with the embeddings of all the documents on your system. This allows you to get the most relevant passages to a user’s query. Then, these passages can be passed to a generative model, such as Gemma 3, alongside the original user query, to generate a contextually relevant answer, such as understanding that you need your carpenter's number for help with damaged floorboards.
For this RAG pipeline to be effective, the quality of the initial retrieval step is critical. Poor embeddings will retrieve irrelevant documents, leading to inaccurate or nonsensical answers. This is where EmbeddingGemma's performance shines, providing the high-quality representations needed to power accurate and reliable on-device applications.
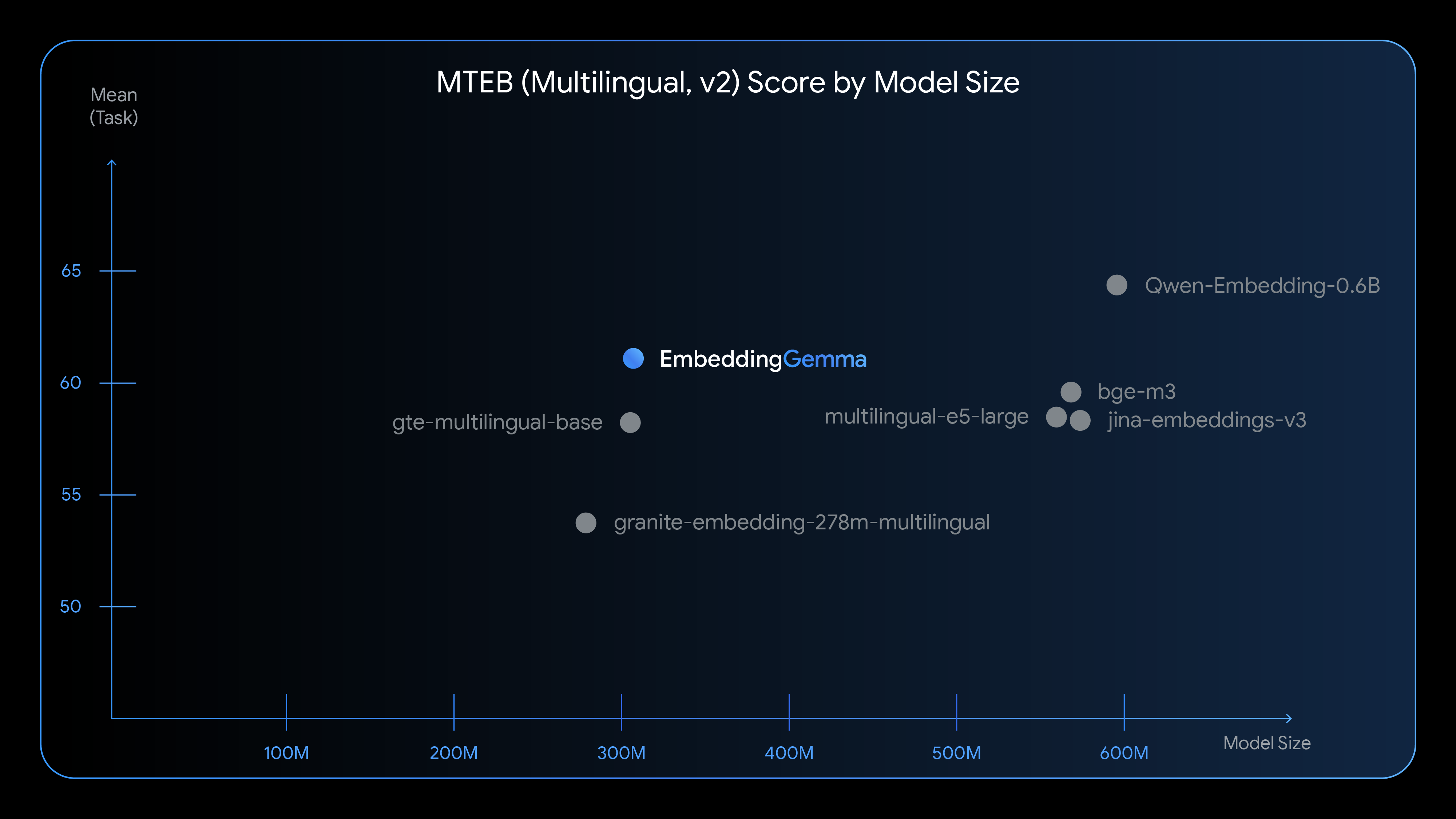
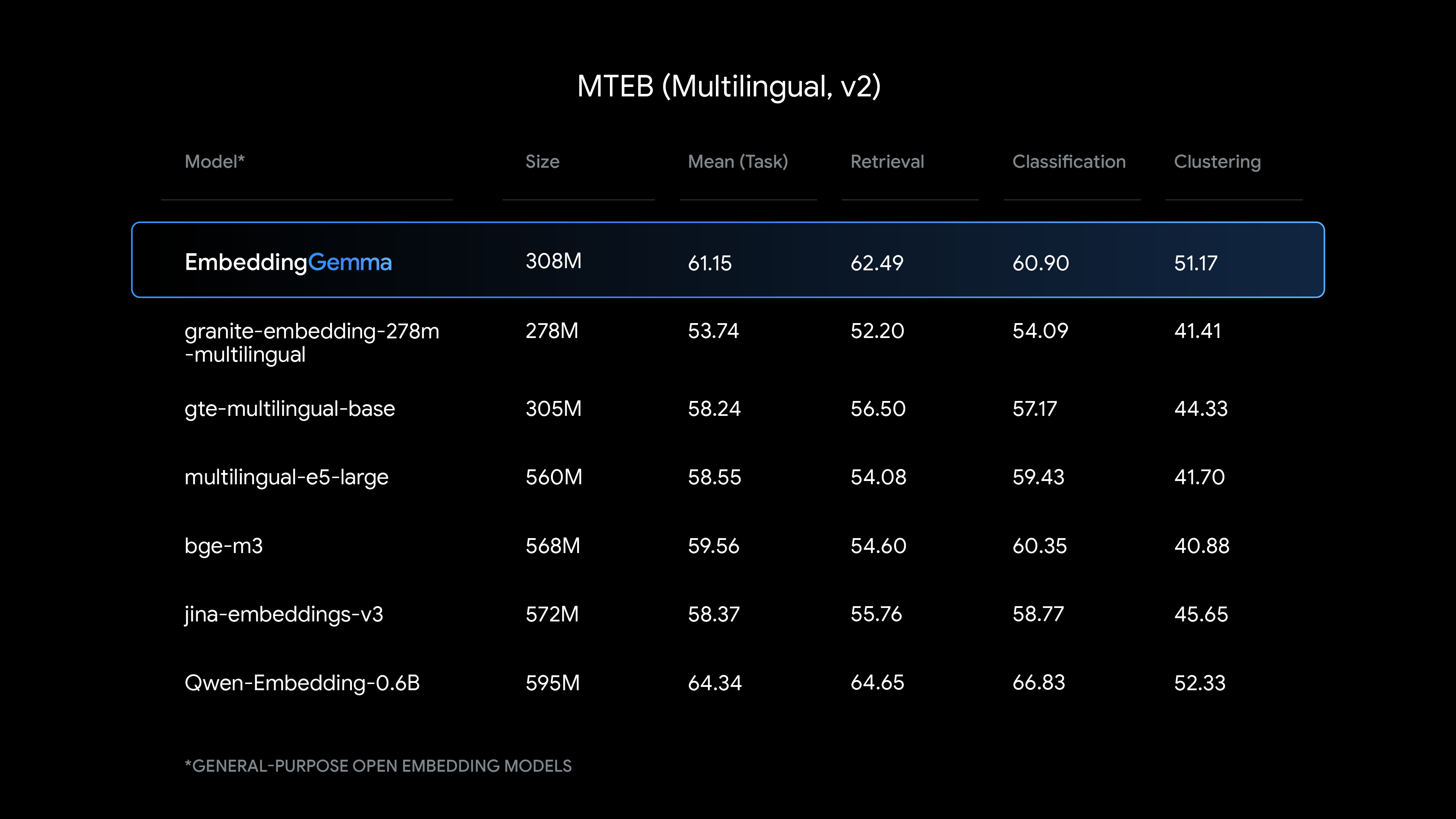
EmbeddingGemma delivers state-of-the-art text understanding for its size, with particularly strong performance on multilingual embedding generation.
See how EmbeddingGemma compares to other popular embedding models:
The 308M parameter model is composed of roughly 100M model parameters and 200M embedding parameters. It’s engineered for performance and minimal resource consumption.
EmbeddingGemma empowers developers to build on-device, flexible, and privacy-centric applications. It generates embeddings of documents directly on the device's hardware, helping ensure sensitive user data is secure. It utilizes the same tokenizer as Gemma 3n for text processing, reducing memory footprint in RAG applications. Unlock new capabilities with EmbeddingGemma, such as:
And if these examples don’t cover it, fine-tune EmbeddingGemma for a specific domain, task or particular language with our quickstart notebook.
Our goal is to provide the best tools for your needs. With this launch, you now have an embedding model for any application.
We’ve prioritized making EmbeddingGemma accessible from day one and have partnered with developers to enable support across popular platforms and frameworks. Start building today with the same technology that will power experiences in Google's first-party platforms like Android with the tools you already use.

On-device GenAI in Chrome, Chromebook Plus, and Pixel Watch with LiteRT-LM

Introducing Gemma 3 270M: The compact model for hyper-efficient AI
Unlocking Peak Performance on Qualcomm NPU with LiteRT

T5Gemma: A new collection of encoder-decoder Gemma models

Announcing the Data Commons Gemini CLI extension