

해당 크기로는 동급 최고의 성능을 제공하는 새로운 개방형 임베딩 모델인 EmbeddingGemma를 출시하게 되어 기쁩니다. 온디바이스 AI용으로 특별히 설계된 이 모델은 3억 8백만 개의 매개변수로 이루어진 고효율 구조를 갖고 있습니다. 덕분에 사용자는 하드웨어에서 직접 실행되는 RAG(검색 증강 생성: Retrieval Augmented Generation) 및 시맨틱 검색 같은 기술을 사용해 애플리케이션을 개발할 수 있습니다. 이 모델은 인터넷 연결 없이도 어디서나 작동하는 비공개 고품질 임베딩을 제공합니다.
Link to Youtube Video (visible only when JS is disabled)
EmbeddingGemma는 임베딩을 생성합니다. 임베딩은 수치적 표현으로(이 경우에는 문장, 문서와 같은 텍스트의 수치적 표현), 텍스트를 고차원의 공간에서 의미를 나타내는 숫자 벡터로 변환한 것입니다. 임베딩이 좋을수록 모든 뉘앙스와 복잡성까지 고려해 언어를 더 잘 표현할 수 있습니다.
RAG 파이프라인을 만들 때 두 가지 주요 단계가 있습니다. 사용자의 입력 데이터를 기반으로 관련 컨텍스트를 검색하는 단계와 해당 컨텍스트를 기반으로 답변을 생성하는 단계입니다. 검색을 수행하려면 사용자 프롬프트의 임베딩을 생성하고 시스템에 있는 모든 문서의 임베딩과 유사성을 계산할 수 있습니다. 이를 통해 사용자의 쿼리와 가장 관련성 높은 구절을 얻을 수 있습니다. 그런 다음, 원래 사용자 쿼리와 함께 이러한 구절을 Gemma 3와 같은 생성형 모델에 전달하여 맥락적으로 관련성이 높은 답변을 생성할 수 있습니다. 예를 들면, 손상된 마룻바닥 수리를 위해서는 목공 업자의 전화번호가 필요한 상황을 이해하고 답변을 제공하는 것입니다.
이 RAG 파이프라인이 효과를 발휘하려면 초기 검색 단계의 품질이 매우 중요합니다. 임베딩이 부실할 경우 관련 없는 문서가 검색되고, 이는 곧 부정확하거나 무의미한 답변으로 이어집니다. 바로 이 부분에서 EmbeddingGemma의 성능이 빛을 발합니다. 정확하고 신뢰할 수 있는 온디바이스 애플리케이션을 구동하는 데 필요한 고품질 표현을 제공하는 것입니다.
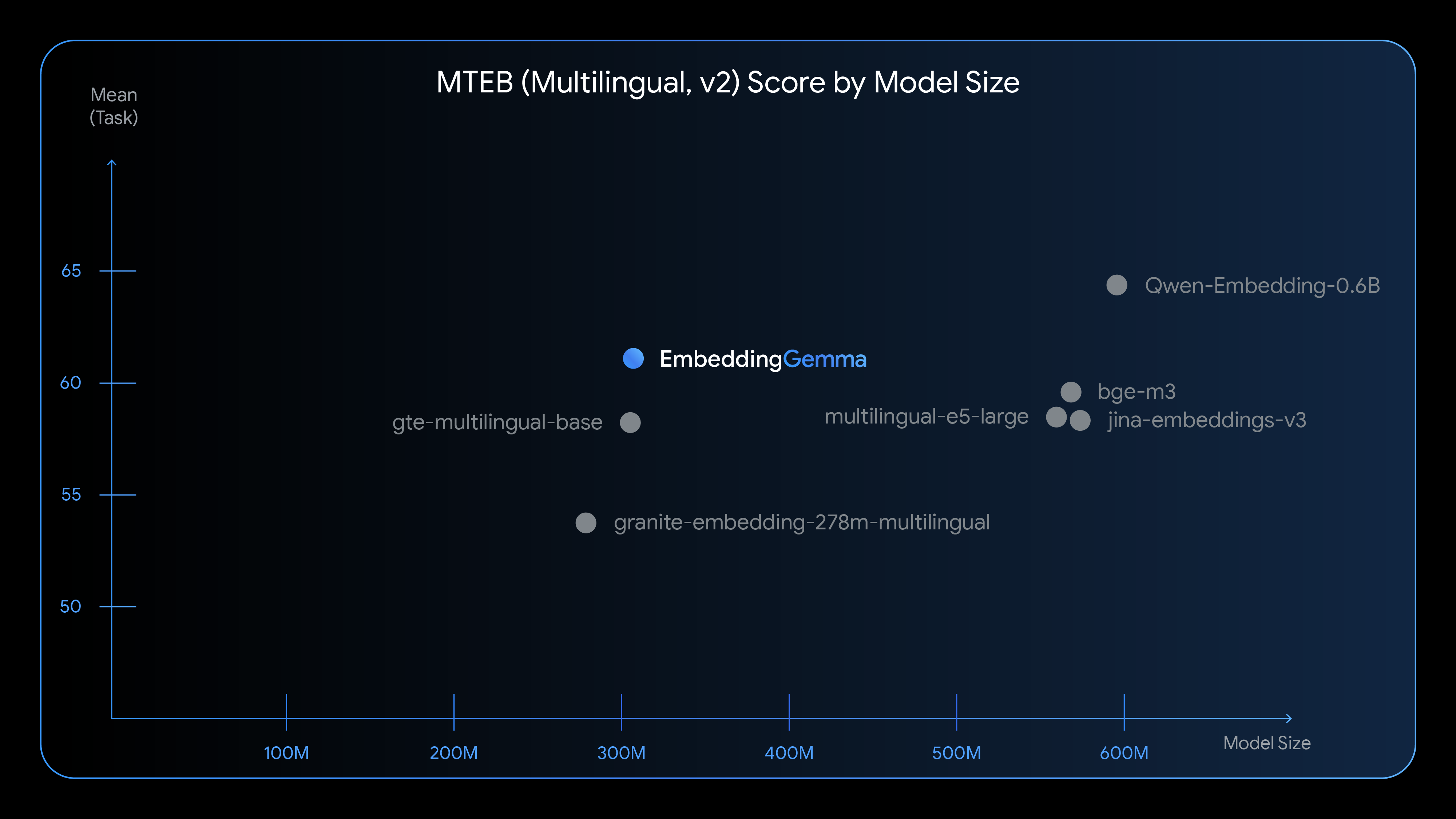
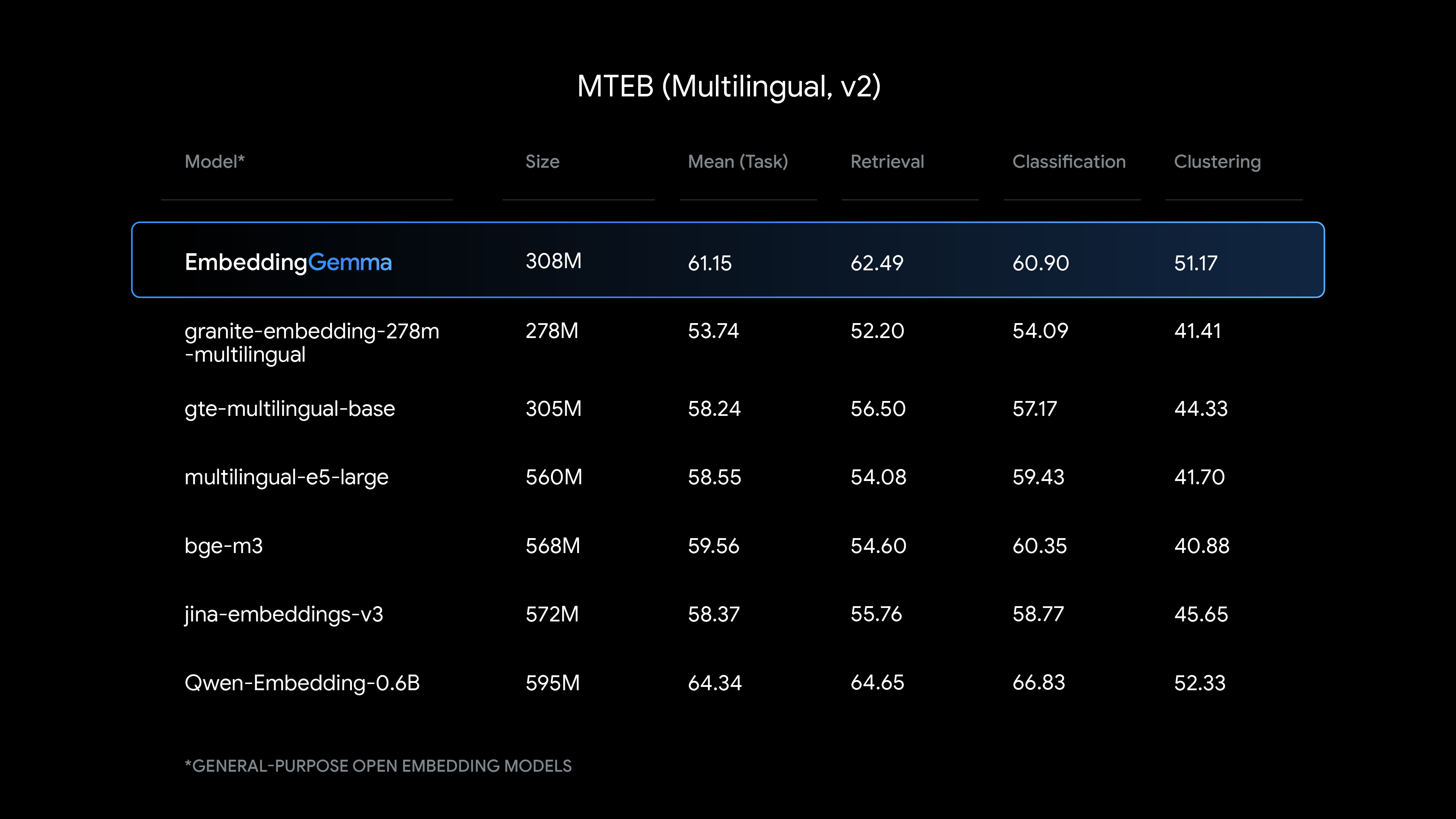
특히 다국어 임베딩 생성에서 강력한 성능을 발휘하는 EmbeddingGemma는 해당 크기로는 최첨단의 텍스트 이해 성능을 제공합니다.
EmbeddingGemma와 다른 인기 임베딩 모델의 비교 결과를 살펴보세요.
이 3억 8백만 개 매개변수 모델은 모델 매개변수 약 1억 개와 임베딩 매개변수 약 2억 개로 구성됩니다. 이 모델은 성능과 최소 리소스 소비를 목표로 설계되었습니다.
EmbeddingGemma는 개발자가 온디바이스 방식의 유연하고 개인정보 보호를 중심으로 하는 애플리케이션을 개발할 수 있도록 지원합니다. 이 모델은 기기의 하드웨어에서 직접 문서 임베딩을 생성하여 민감한 사용자 데이터의 보안을 보장합니다. 텍스트 처리를 위해 Gemma 3n과 동일한 토크나이저를 활용하여 RAG 애플리케이션의 메모리 공간을 줄입니다. EmbeddingGemma로 다음과 같은 새로운 기능을 활용해 보세요.
이 예제에서 다루지 않는 사항들은 빠른 시작 노트북으로 특정 도메인, 작업 또는 언어에 맞게 EmbeddingGemma를 파인 튜닝하세요.
저희의 목표는 개발자 여러분의 필요에 가장 적합한 도구를 제공하는 것입니다. 이번 출시를 통해 개발자는 이제 모든 애플리케이션에 맞는 임베딩 모델을 갖게 되었습니다.
저희는 출시 첫날부터 원활하게 EmbeddingGemma에 액세스할 수 있도록 하는 데 중점을 두고 인기 플랫폼과 프레임워크에서 지원될 수 있도록 개발자와 협력하고 있습니다. 여러분이 이미 사용 중인 도구를 그대로 사용해, Android 같은 Google 자사 플랫폼에서의 경험을 구동하게 될 동일한 기술로 오늘부터 바로 개발에 착수하세요.

Announcing the Data Commons Gemini CLI extension

LiteRT-LM이 탑재된 Chrome, Chromebook Plus, Pixel Watch의 온디바이스 생성형 AI

Gemma 3 270M 소개: 초효율적인 AI를 위한 콤팩트 모델

Building with Gemini 3 in Jules

Google AI Edge Gallery: 이제 오디오와 Google Play에서 사용 가능

T5Gemma: 새로운 인코더-디코더 Gemma 모델 컬렉션