

지난 10년간 모바일 기기에는 GPU를 비롯해 점점 더 강력해지는 특정한 목적에 특화된 가속기가 탑재되었으며, 최근에는 더욱 강력한 NPU(Neural Processing Units, 신경망처리장치)까지 사용되고 있습니다. AI 모델을 모바일 GPU와 NPU에서 가속화하면 CPU 대비 모델 속도를 최대 25배까지 높이고 전력 소비를 최대 5배까지 줄일 수 있습니다. 하지만 이렇게 탁월한 성능을 실제로 활용하는 것은 대부분의 개발자에게 어려운 과제입니다. GPU 추론의 경우 하드웨어별 API를, NPU 추론의 경우 벤더별 SDK, 포맷, 런타임을 각각 다뤄야 하기 때문입니다.
Google AI Edge 팀은 개발자들의 피드백을 바탕으로 이러한 과제를 해결하고, 더욱 뛰어난 성능으로 간편하게 모바일 AI를 가속화할 수 있도록 LiteRT에 다양한 개선 사항을 도입했습니다. 이번 신규 릴리스는 온디바이스 머신러닝 추론을 그 어느때 보다도 더 쉽게 만들어 주는 신형 LiteRT API, 최첨단 GPU 가속 기술, MediaTek 및 Qualcomm과 공동 개발한 새로운 NPU 지원(사전 체험판 이용 가능), 온디바이스 애플리케이션 성능을 극대화하는 고급 추론 기능들로 구성되어 있습니다. 지금부터 하나씩 살펴보겠습니다.
GPU는 언제나 LiteRT 가속 기술의 핵심으로서 가장 광범위한 지원과 가장 안정적인 성능 향상을 제공해 왔습니다. 저희의 최신 GPU 가속 기술인 MLDrift는 더 빨라진 성능과 개선 사항으로 그 기준을 한층 더 끌어올렸습니다. 덕분에 다음과 같은 기능을 통해 더 큰 규모의 모델도 지원할 수 있게 되었습니다.
결과적으로 CPU와 이전 버전의 TFLite GPU Delegate, 기타 GPU 기반 프레임워크 대비, 특히 CNN과 Transformer 모델에서 월등히 빠른 성능을 달성했습니다.
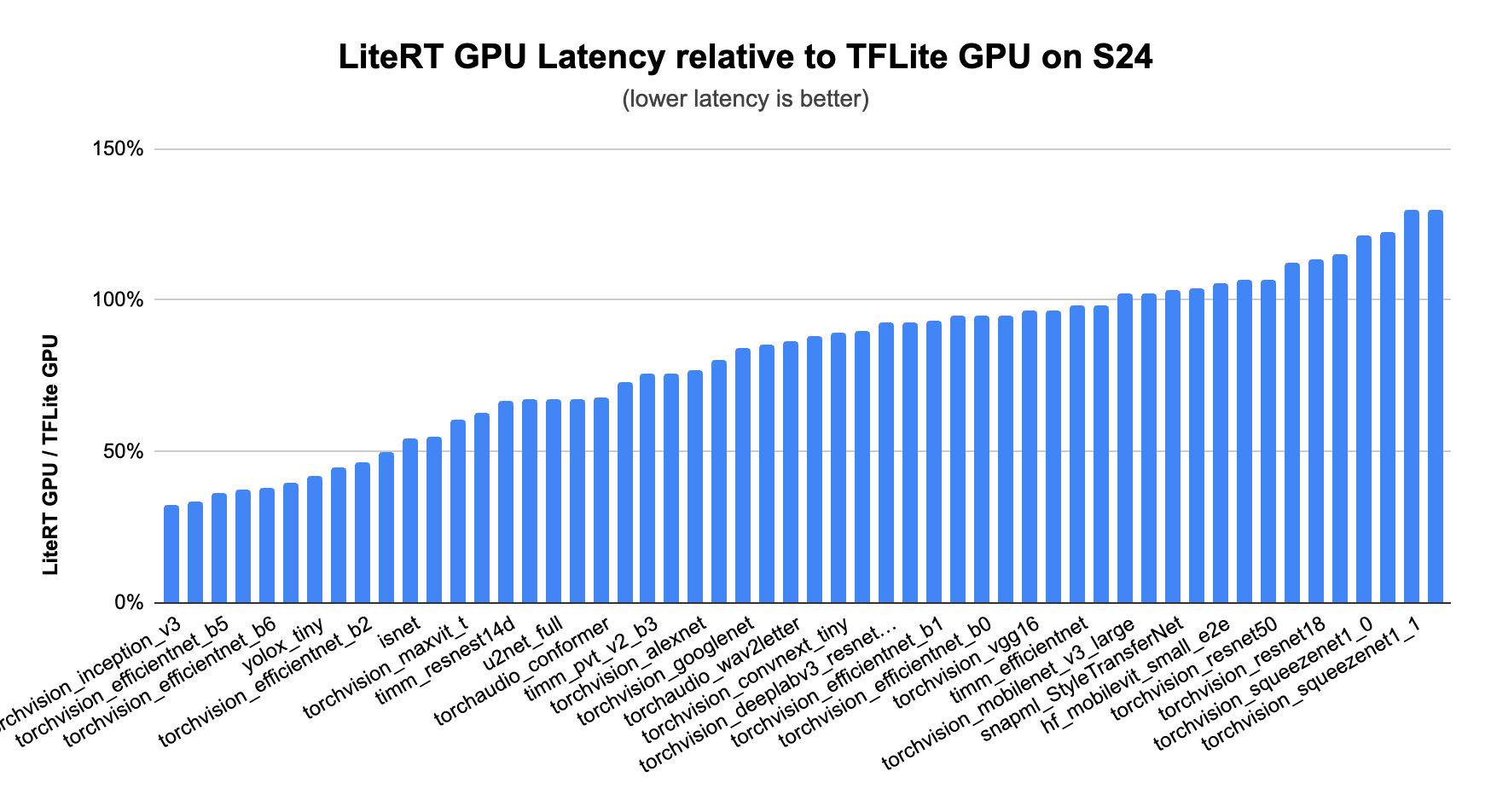
Google 문서에서 예시를 확인하고 지금 바로 GPU 가속을 시도해 보세요.
AI 전용 가속기인 NPU는 주요 스마트폰에 점점 더 많이 탑재되고 있습니다. NPU를 활용하면 AI 모델을 더욱 효율적으로 실행할 수 있으며, 많은 경우 속도도 향상됩니다. Google의 내부 테스트 결과, NPU는 CPU 대비 최대 25배 빠른 속도와 최대 5배 향상된 전력 효율을 확인할 수 있었습니다(2025년 5월 내부 테스트 기준).
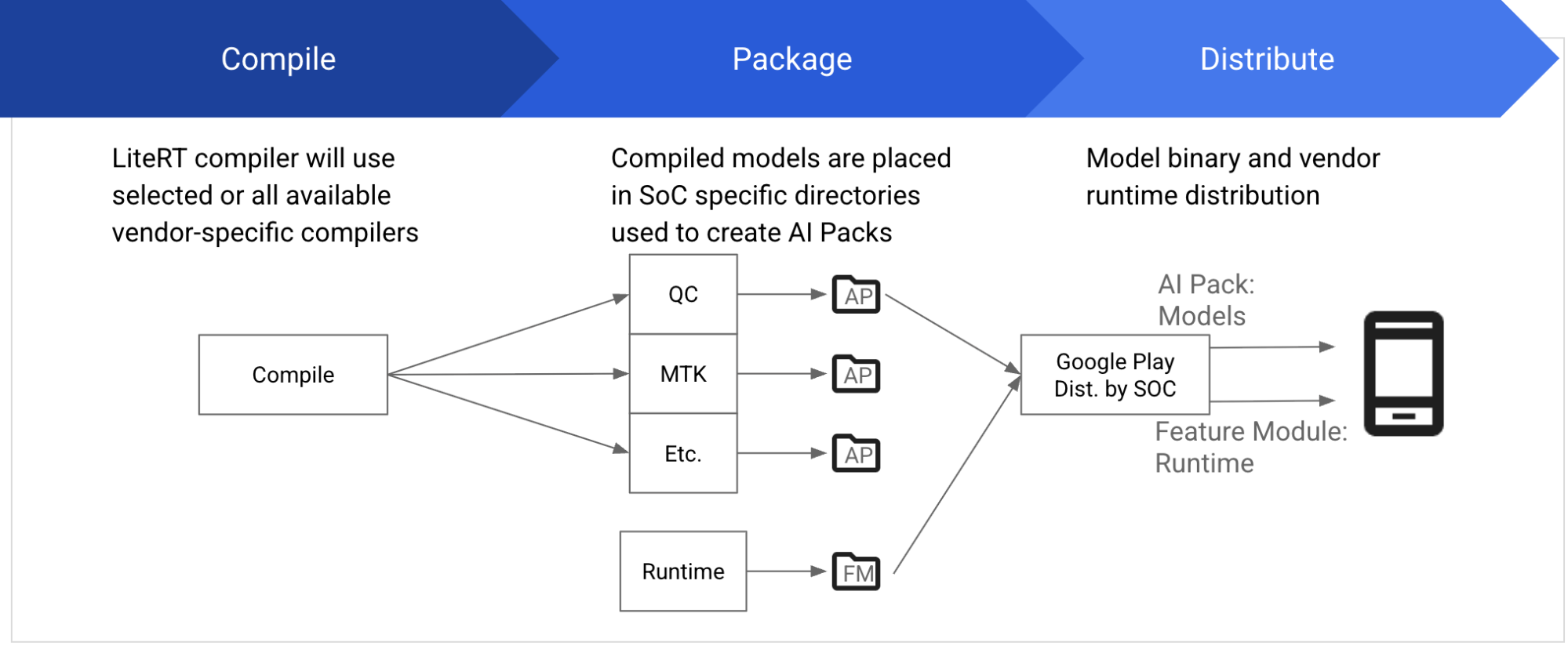
일반적으로 각 벤더는 컴파일러, 런타임, 기타 필수 구성 요소를 포함한 자체 SDK를 제공하여 자사의 SoC에서 모델을 컴파일하고 실행합니다. 이 SDK는 특정 SoC 버전과 정확히 맞아야 하고, 적절한 다운로드 및 설치가 이루어져야 합니다. 이제 LiteRT는 NPU에서 모델을 개발하고 배포하는 통일된 방식을 제공하여 이 모든 복잡한 과정을 단순하게 만듭니다.
MediaTek 및 Qualcomm과의 협력을 통해 개발자들이 시각, 오디오, NLP 모델 등 다양한 기본 ML 모델을 두 기업의 NPU에서 가속화할 수 있도록 지원하게 되어 매우 기쁘게 생각합니다. 앞으로도 모델과 도메인에 대한 지원이 확대될 예정입니다.
이 기능은 현재 비공개 미리보기로 제공되고 있습니다. 사전 체험판 이용을 원하시면 여기에서 신청하세요.
LiteRT API의 최신 버전에서는 GPU와 NPU를 사용하는 절차를 간소화하여 그 어느때보다도 사용이 쉬워졌습니다. 최신 변경 사항을 통해 대상 백엔드를 옵션으로 지정할 수 있게 되어 설정 절차가 대폭 간소화되었습니다. 일례로 개발자는 다음과 같이 GPU 가속을 지정할 수 있습니다.
// 1. Load model.
auto model = *Model::Load("mymodel.tflite");
// 2. Create a compiled model targeting GPU.
auto compiled_model = *CompiledModel::Create(model, kLiteRtHwAcceleratorGpu);보시다시피 새로운 CompiledModel API를 사용하면 모델과 대상 백엔드를 지정해 가속화하는 과정이 매우 간단해집니다.
고성능 백엔드 사용이 도움이 되지만, 메모리나 프로세서 병목 현상으로 인해 애플리케이션의 최적 성능이 제한될 수도 있습니다. 새로운 LiteRT API는 이러한 문제를 해결할 수 있도록 비용이 많이 드는 메모리 복사 과정을 없애는 내장형 버퍼 상호 운용성과 유휴 상태의 프로세서를 병렬로 활용할 수 있는 비동기 실행 기능을 제공합니다.
새로운 TensorBuffer API는 LiteRT에서 입력/출력 데이터를 효율적으로 처리하도록 지원합니다. 이 API를 사용하면 OpenGL 버퍼와 같은 하드웨어 메모리에 있는 데이터를 CompiledModel의 입력 또는 출력으로 직접 활용할 수 있어 비용이 많이 드는 CPU 복사 과정이 전혀 필요하지 않게 됩니다.
auto tensor_buffer = *litert::TensorBuffer::CreateFromGlBuffer(tensor_type, opengl_buffer);이러한 방식은 불필요한 CPU 오버헤드를 크게 줄이고 성능을 향상시킵니다.
아울러 시스템이 지원하는 경우에 TensorBuffer API를 통해 서로 다른 하드웨어 메모리 유형 간에 복사 작업 없이 원활하게 변환할 수 있습니다. 예를 들어 OpenGL 버퍼를 OpenCL 버퍼나 Android HardwareBuffer로 중간 CPU 변환 없이 손쉽게 데이터를 변환할 수 있는 것입니다.
이 기술은 갈수록 복잡해지는 AI 모델에서 필요로 하는 막대한 데이터 처리량과 높은 성능 요건을 충족하는 데 핵심적인 역할을 담당합니다. TensorBuffer 사용법은 Google 문서에서 확인하실 수 있습니다.
비동기 실행은 AI 모델의 다양한 부분이나 독립적인 작업들이 CPU와 GPU, NPU에서 동시에 실행되도록 하여, 다양한 프로세서의 가용 연산 주기를 적극 활용해 다음 예시처럼 효율성과 반응성을 높일 수 있습니다.
실시간 AI 상호작용이 필요한 애플리케이션에서는 하나의 프로세서에서 작업을 시작하고, 다른 프로세서에서 이어서 수행하는 방식으로 진행됩니다. 병렬 처리는 지연 시간을 최소화하며 더욱 매끄럽고 상호적인 사용자 경험을 제공합니다. 비동기 실행은 여러 프로세서에서 다수의 연산을 한 번에 효율적으로 관리함으로써 시스템 처리량을 극대화하고, 연산 부하가 높을 때에도 AI 애플리케이션이 유연하고 원활하게 작동하도록 보장합니다.
비동기 실행은 OS 수준의 메커니즘(예: Android/Linux 환경의 동기화 펜스)을 활용하여 구현되었으며, CPU의 개입 없이 하나의 하드웨어 가속기가 다른 하드웨어 가속기의 작업 완료 시 직접 트리거할 수 있도록 합니다. 이를 통해 지연 시간이 단축되고(예: 자사 GPU 비동기 데모에서 최대 2배 감소) 전력 소모도 절감되는 동시에, 파이프라인은 더 결정론적으로 작동하게 됩니다.
다음은 OpenGL 버퍼 입력을 활용한 비동기 추론을 보여주는 코드 스니펫입니다.
// Create an input TensorBuffer based on tensor_type that wraps the given OpenGL
// Buffer. env is an LiteRT environment to use existing EGL display and context.
auto tensor_buffer_from_opengl = *litert::TensorBuffer::CreateFromGlBuffer(env,
tensor_type, opengl_buffer);
// Create an input event and attach it to the input buffer. Internally, it
// creates and inserts a fence sync object into the current EGL command queue.
auto input_event = *Event::CreateManaged(env, LiteRtEventTypeEglSyncFence);
tensor_buffer_from_opengl.SetEvent(std::move(input_event));
// Create the input and output TensorBuffers…
// Run async inference
compiled_model1.RunAsync(input_buffers, output_buffers);비동기 실행 기능을 활용하는 더 많은 코드 예시는 Google 문서에서 확인하실 수 있습니다.
최신 AI 모델의 힘을 활용하는 한편 최신 가속 기능과 성능 향상 기법을 통해 사용자에게 최상의 AI 경험을 제공해 보시기 바랍니다. 시작 단계에서 참고할 수 있도록 모든 기능 사용법 예시가 완벽하게 통합된 샘플 앱도 제공되니 확인해 보세요.
이 블로그에 언급된 모든 신규 LiteRT 기능은 여기(https://github.com/google-ai-edge/LiteRT)에서 확인하실 수 있습니다.
Google AI Edge 관련 소식은 온디바이스 GenAI 업데이트와 다양한 온디바이스 벤치마킹 및 평가 정보가 담긴 새로운 AI Edge 포털 서비스를 참고하시기 바랍니다.
이번 발표와 Google I/O 2025의 모든 업데이트 정보는 5월 22일부터 io.google에서 확인하실 수 있습니다.
Advait Jain, Alan Kelly, Alexander Shaposhnikov, Andrei Kulik, Andrew Zhang, Akshat Sharma, Byungchul Kim, Chunlei Niu, Chuo-Ling Chang, Claudio Basile, Cormac Brick, David Massoud, Dillon Sharlet, Eamon Hugh, Ekaterina Ignasheva, Fengwu Yao, Frank Ban, Frank Barchard, Gerardo Carranza, Grant Jensen, Henry Wang, Ho Ko, Jae Yoo, Jiuqiang Tang, Juhyun Lee, Julius Kammerl, Khanh LeViet, Kris Tonthat, Lin Chen, Lu Wang, Luke Boyer, Marissa Ikonomidis, Mark Sherwood, Matt Kreileder, Matthias Grundmann, Misha Gutman, Pedro Gonnet, Ping Yu, Quentin Khan, Raman Sarokin, Sachin Kotwani, Steven Toribio, Suleman Shahid, Teng-Hui Zhu, Volodymyr Kysenko, Wai Hon Law, Weiyi Wang, Youchuan Hu, Yu-Hui Chen 등 이번 버전 출시에 도움을 주신 모든 팀 구성원과 협력 업체 관계자분들에게 감사의 마음을 전합니다.

LiteRT-LM이 탑재된 Chrome, Chromebook Plus, Pixel Watch의 온디바이스 생성형 AI

멀티모달리티, RAG, 함수 호출을 제공하는 온디바이스 소규모 언어 모델

Announcing the Agent Development Kit for Go: Build Powerful AI Agents with Your Favorite Languages

Google AI Edge Gallery: 이제 오디오와 Google Play에서 사용 가능

Announcing User Simulation in ADK Evaluation

게임 개발자를 위한 Google AI