

この 10 年間で、スマートフォンに組み込まれる目的別アクセラレータはますます強力なものになっており、GPU だけでなく、最近ではさらに強力な NPU(ニューラル プロセッシング ユニット)も搭載されるようになっています。モバイルの GPU や NPU で AI モデルを高速化すれば、最大で CPU の 25 倍の速度、5 分の 1 の消費電力を実現できます。しかし、ほとんどのデベロッパーにとっては、このようなパフォーマンス上のメリットを発揮できるようにすることは困難でした。これを実現するには、GPU 推論なら HW 固有の API を、NPU 推論ならベンダー固有の SDK、フォーマット、ランタイムを使いこなす必要があるからです。
Google AI Edge チームは、皆さんのフィードバックに耳を傾けています。そしてうれしいことに、LiteRT に複数の改善を加えたことをお知らせします。この改善により、前述の課題を解決し、モバイル AI を簡単に高速化して、パフォーマンスを向上させることができます。今回の新しいリリースには、オンデバイス ML 推論をこれまで以上に簡単にする新しい LiteRT API、最高水準の最新 GPU アクセラレーション、MediaTek および Qualcomm と共同開発した新しい NPU サポート(早期アクセス可能)、そしてオンデバイス アプリケーションのパフォーマンスを最大限に高める高度な推論機能が含まれています。さっそく試してみてください!
LiteRT のアクセラレーションの中核にあるのは常に GPU です。GPU は最も広くサポートされており、最も一貫してパフォーマンスを向上させることができます。GPU アクセラレーションの最新バージョンである MLDrift では、一段とレベルが向上し、かなり大きなサイズのモデルをサポートできるようにするために、パフォーマンスを高めるとともに、次のような改善が加えられています。
その結果、CPU や以前のバージョンの TFLite GPU デリゲート、そして CNN やトランスフォーマー モデル向けのその他の GPU 対応フレームワークよりも、大幅に高いパフォーマンスを実現しています。
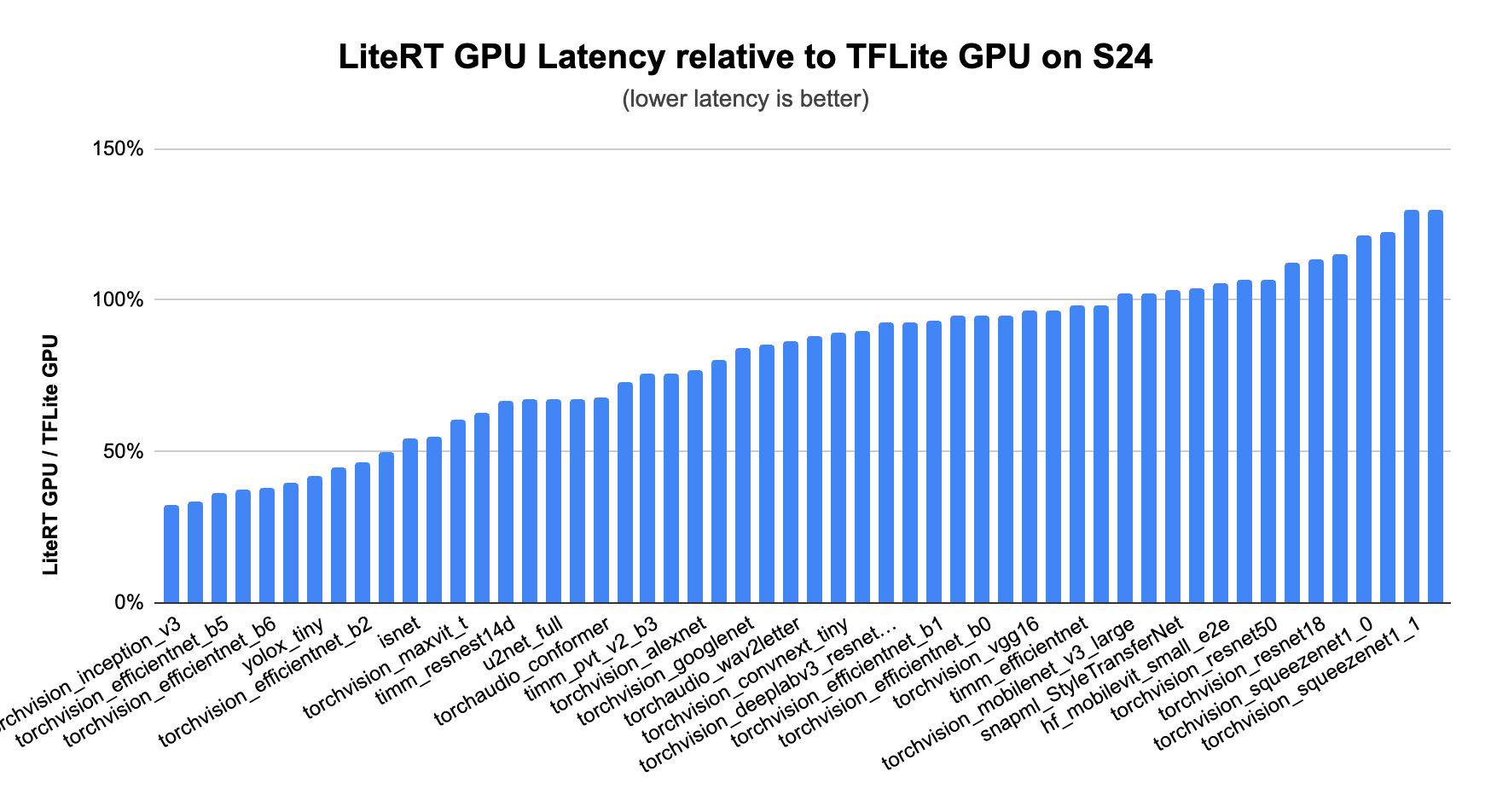
ドキュメントのサンプルを確認し、GPU アクセラレーションを試してみてください。
NPU は AI 専用のアクセラレータで、フラッグシップ モデルのスマートフォンに搭載されることが多くなっています。NPU が搭載されていると、AI モデルをはるかに効率的に実行でき、ほとんどのケースで速度も上がります。CPU と比較した内部テストでは、速度は最大 25 倍、電力効率は 5 倍になっています。(2025 年 5 月、社内テストに基づく)
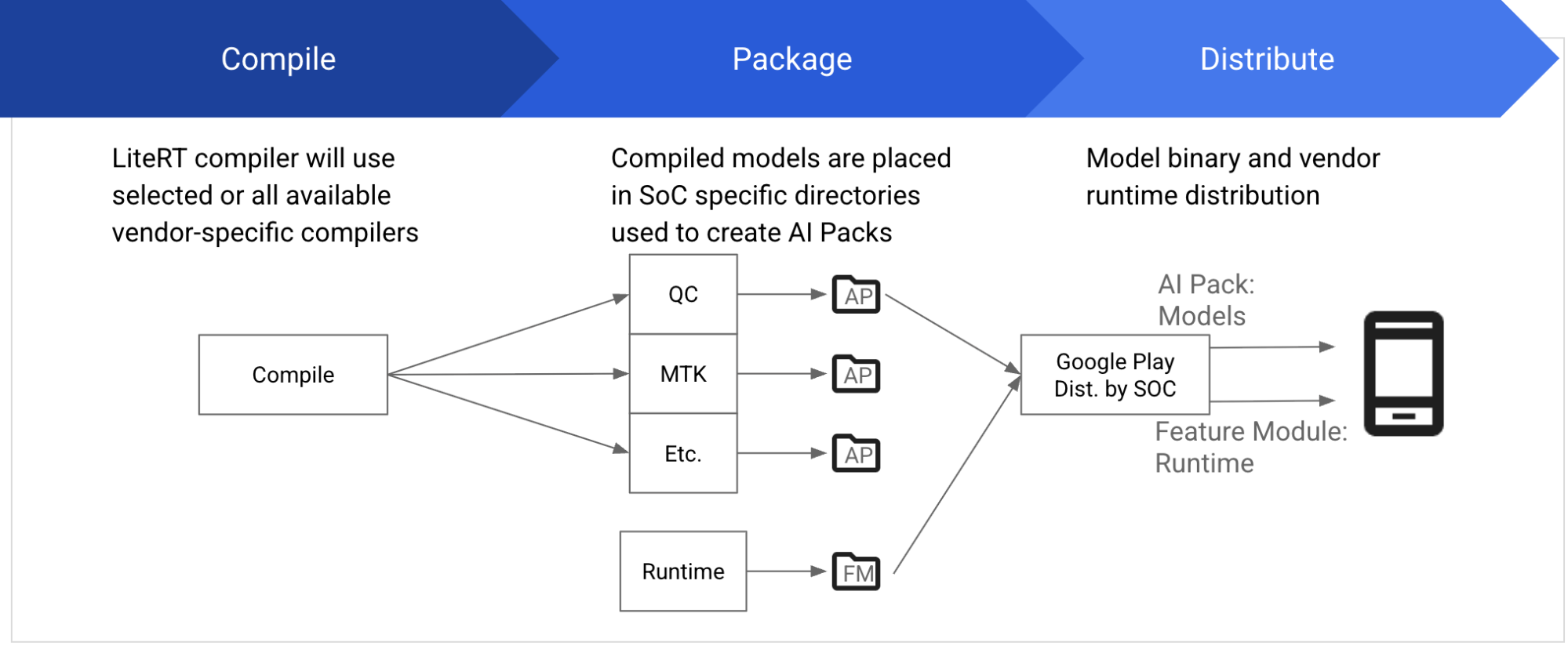
通常、各ベンダーは、SoC でモデルをコンパイルして実行するため、コンパイラやランタイムなどの依存関係を含む専用の SDK が提供されます。SDK は、特定の SoC バージョンと厳密に一致する必要があるので、正しいものをダウンロードしてインストールしなければなりません。LiteRT を使うと、NPU が違っていても同じ方法でモデルの開発やデプロイを行えるので、複雑な手順は不要になります。
また、MediaTek および Qualcomm との提携を通して、MediaTek と Qualcomm の NPU で、ビジョンモデル、オーディオ モデル、NLP モデルなど、さまざまな有名 ML モデルを高速化できるようにしています。今後 1 年間を通して、モデルやドメインのサポート強化を継続する予定です。
この機能はプライベート プレビュー版として利用できます。早期アクセスはこちらからお申し込みください。
LiteRT API の最新バージョンでは、プロセスをシンプルにすることで、これまで以上に簡単に GPU や NPU を利用できるようにしています。この最新の変更により、ターゲット バックエンドをオプションとして指定できるようになったので、セットアップがとても簡単になります。たとえば、デベロッパーは次のようにして GPU アクセラレーションを指定できます。
// 1. モデルを読み込む。
auto model = *Model::Load("mymodel.tflite");
// 2. GPU をターゲットにしてモデルをコンパイルする。
auto compiled_model = *CompiledModel::Create(model, kLiteRtHwAcceleratorGpu);ご覧のように、新しい CompiledModel API を使うと、とても簡単にモデルとターゲット バックエンドを指定して高速化できます。
高性能なバックエンドは効果的ですが、メモリやプロセッサのボトルネックによって、アプリケーションが最適なパフォーマンスを発揮できなくなる場合もあります。新しい LiteRT API は、このような課題に対処できるようになっています。バッファを共用する仕組みが搭載されているので、コストのかかるメモリコピー操作は不要になります。また、非同期実行によってアイドル状態のプロセッサを並列利用できます。
新しい TensorBuffer API は、LiteRT で入出力データを効率的に処理する方法を提供します。OpenGL バッファなどのハードウェア メモリにあるデータを、CompiledModel の入力または出力として直接利用できるので、コストのかかる CPU コピーは完全に不要になります。
auto tensor_buffer = *litert::TensorBuffer::CreateFromGlBuffer(tensor_type, opengl_buffer);これにより、不要な CPU オーバーヘッドが大幅に削減され、パフォーマンスが向上します。
さらに、サポート対象のシステムでは、TensorBuffer API を使って異なるハードウェア メモリタイプ間でコピー不要のシームレスな変換を行うこともできます。中間的に CPU に転送することなく、OpenGL バッファから OpenCL バッファに、さらには Android HardwareBuffer にデータを簡単に変換できることを想像してみてください。
AI モデルは、ますます複雑になっています。この手法は、それに伴うデータ量や要求性能の増加に対応するための鍵となります。TensorBuffer の使い方のサンプルは、ドキュメントをご覧ください。
非同期実行を活用すると、AI モデルのさまざまな部分や独立したタスクを CPU、GPU、NPU で同時に実行できます。そのため、さまざまなプロセッサの演算サイクルを自在に活用し、効率と応答速度を上げることができます。たとえば、次のようなことができます。
リアルタイム AI インタラクションが求められるアプリケーションでは、タスクを 1 つのプロセッサで開始して、他のオペレーションを別のプロセッサで進めることができます。並列処理によってレイテンシが最小限にとどめられるので、スムーズでインタラクティブなユーザー エクスペリエンスを実現できます。非同期実行では、複数のプロセッサを利用して演算を効果的に管理したり、重複して演算させたりすることで、システムのスループットを最大化します。そのため、演算負荷が高くなっても、AI アプリケーションの速度が低下することはなく、応答速度も保たれます。
非同期実行は、OS レベルのメカニズム(Android/Linux の同期フェンスなど)で実装され、CPU が関与しなくても、ある HW アクセラレータの処理が完了したときに、別の HW アクセラレータの処理を直接起動できます。そのため、レイテンシが減り(GPU 非同期デモでは最大 2 分の 1)、消費電力も削減され、パイプラインの予測可能性が向上します。
次に示すのは、OpenGL バッファ入力を使って非同期推論を行うコード スニペットです。
// 指定された OpenGL バッファをラップする tensor_type に基づいて入力 TensorBuffer を作成。
// env は、既存の EGL ディスプレイおよびコンテキストを使うための LiteRT 環境。
auto tensor_buffer_from_opengl = *litert::TensorBuffer::CreateFromGlBuffer(env,
tensor_type, opengl_buffer);
// 入力イベントを作成し、入力バッファにアタッチ。内部的には、
// フェンス同期オブジェクトを作成し、現在の EGL コマンドキューに挿入する。
auto input_event = *Event::CreateManaged(env, LiteRtEventTypeEglSyncFence);
tensor_buffer_from_opengl.SetEvent(std::move(input_event));
// 入力と出力の TensorBuffers を作成…
// 非同期推論を実行
compiled_model1.RunAsync(input_buffers, output_buffers);その他のコードサンプルは、非同期実行を活用する方法を説明したドキュメントをご覧ください。
最新の AI モデルを使ってユーザーに最高の体験を提供するため、最新のアクセラレーション機能とパフォーマンス向上技術を試してみましょう。まずは、すべての機能の活用方法が組み込まれているサンプルアプリをご覧ください。
このブログで紹介した LiteRT の新機能は、すべて https://github.com/google-ai-edge/LiteRT で確認できます。
その他の Google AI Edge ニュースとして、オンデバイス GenAI のアップデートと、オンデバイス向けのベンチマークや検証機能を幅広くカバーする新しい AI Edge Portal サービスがあります。これらについてもお読みください。
この発表と Google I/O 2025 のすべての最新情報は、5 月 22 日以降に io.google でご覧いただけます。
今回のリリースに向けた作業に貢献してくれた次のチームメンバーと協力者の皆様に感謝します。Advait Jain、Alan Kelly、Alexander Shaposhnikov、Andrei Kulik、Andrew Zhang、Akshat Sharma、Byungchul Kim、Chunlei Niu、Chuo-Ling Chang、Claudio Basile、Cormac Brick、David Massoud、Dillon Sharlet、Eamon Hugh、Ekaterina Ignasheva、Fengwu Yao、Frank Ban、Frank Barchard、Gerardo Carranza、Grant Jensen、Henry Wang、Ho Ko、Jae Yoo、Jiuqiang Tang、Juhyun Lee、Julius Kammerl、Khanh LeViet、Kris Tonthat、Lin Chen、Lu Wang、Luke Boyer、Marissa Ikonomidis、Mark Sherwood、Matt Kreileder、Matthias Grundmann、Misha Gutman、Pedro Gonnet、Ping Yu、Quentin Khan、Raman Sarokin、Sachin Kotwani、Steven Toribio、Suleman Shahid、Teng-Hui Zhu、Volodymyr Kysenko、Wai Hon Law、Weiyi Wang、Youchuan Hu、Yu-Hui Chen

Google AI Edge Gallery: 音声サポートが追加され Google Play で利用可能に

Announcing User Simulation in ADK Evaluation

マルチモダリティ、RAG、および関数呼び出しに対応したオンデバイス小型言語モデル

LiteRT-LM を活用した Chrome、Chromebook Plus、Google Pixel Watch でのオンデバイス生成 AI

ゲーム デベロッパー向け Google AI

Announcing the Agent Development Kit for Go: Build Powerful AI Agents with Your Favorite Languages