

Over the past decade, mobile phones have incorporated increasingly powerful purpose-specific accelerators including GPUs and recently, more powerful NPUs (Neural Processing Units). By accelerating your AI models on mobile GPUs and NPUs, you can speed up your models by up to 25x compared to CPU while also reducing power consumption by up to 5x. However, unlocking these outstanding performance benefits has proven challenging for most developers, as it requires wrangling HW-specific APIs in case of GPU inference or wrangling vendor-specific SDKs, formats, and runtimes for NPU inference.
Listening to your feedback, the Google AI Edge team is excited to announce multiple improvements to LiteRT solving the challenges above, and accelerating AI on mobile more easily with increased performance. Our new release includes a new LiteRT API making on-device ML inference easier than ever, our latest cutting-edge GPU acceleration, new NPU support co-developed with MediaTek and Qualcomm (open for early access), and advanced inference features to maximize performance for on-device applications. Let’s dive in!
GPUs have always been at the heart of LiteRT’s acceleration story, providing the broadest support and most consistent performance improvement. MLDrift, our latest version of GPU acceleration, pushes the bar even further with faster performance and improvements to support models of a significantly larger size through:
This results in significantly faster performance than CPUs, than previous versions of our TFLite GPU delegate, and even other GPU enabled frameworks particularly for CNN and Transformer models.
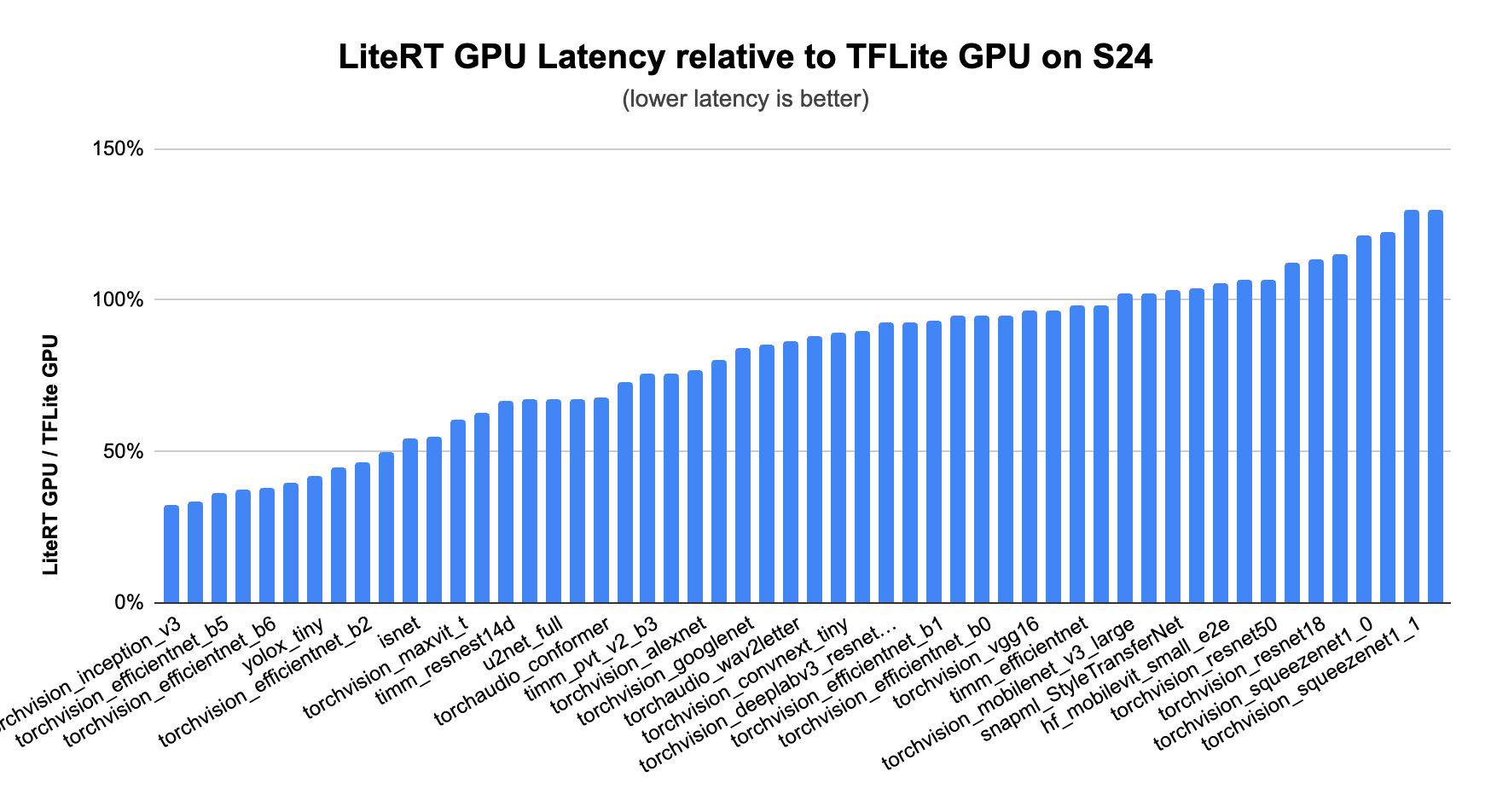
Find examples in our documentation and give GPU acceleration a try today.
NPUs, AI specific accelerators, are becoming increasingly common in flagship phones. They allow you to run AI models much more efficiently, and in many cases much faster. In our internal testing compared to CPUs this acceleration can be up to 25x faster, and 5x more power efficient. (May 2025, based on internal testing)
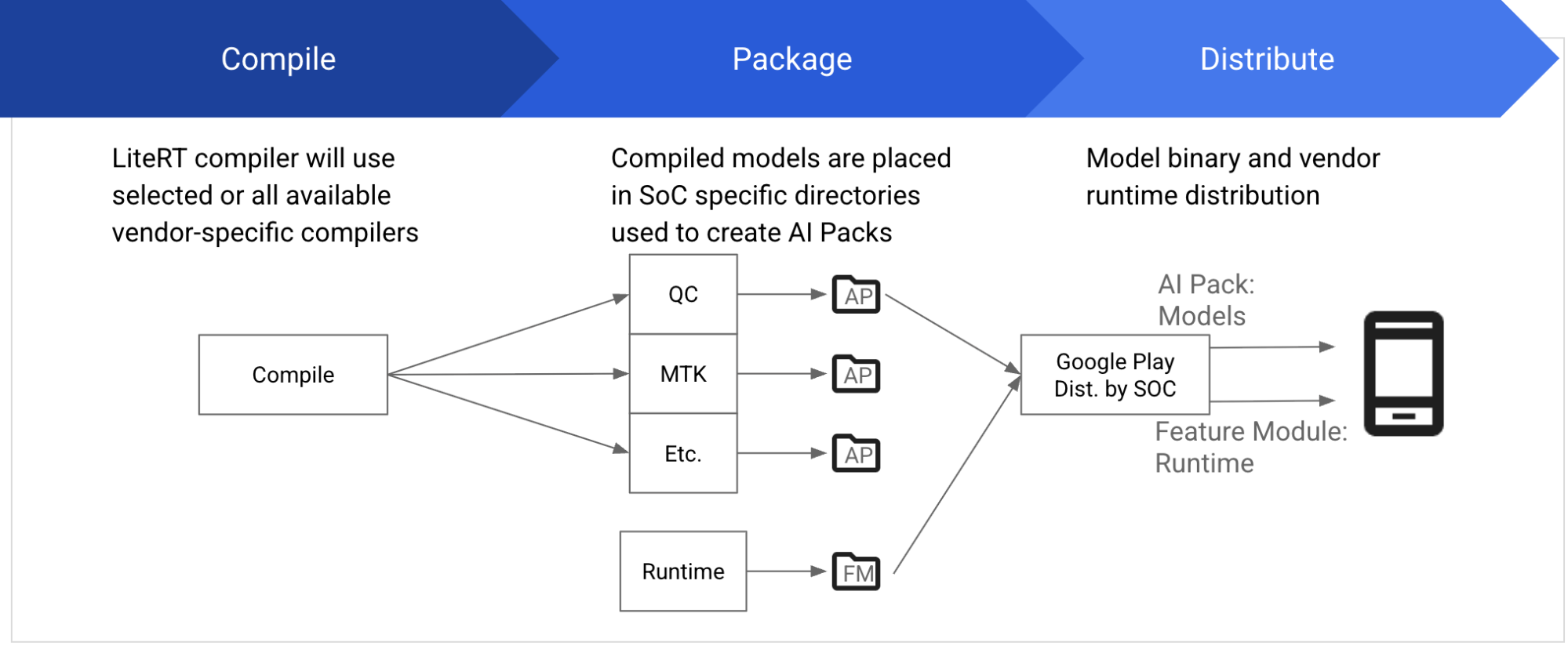
Typically, each vendor provides their own SDKs, including compilers, runtime, and other dependencies, to compile and execute models on their SoCs. The SDK must precisely match the specific SoC version and requires proper download and installation. LiteRT now provides a uniform way to develop and deploy models on NPUs, abstracting away all these complexities.
We’re excited to partner with MediaTek and Qualcomm to allow developers to accelerate a wide variety of classic ML models, such as vision, audio, and NLP models, on MediaTek and Qualcomm NPUs. Increased model and domain support will continue over the coming year.
This feature is available in private preview. For early access apply here.
We’ve made GPUs and NPUs easier than ever to use by simplifying the process in the latest version of the LiteRT APIs. With the latest changes, we have simplified the setup significantly with the ability to specify the target backend as an option. As an example, this is how a developer would specify GPU acceleration:
// 1. Load model.
auto model = *Model::Load("mymodel.tflite");
// 2. Create a compiled model targeting GPU.
auto compiled_model = *CompiledModel::Create(model, kLiteRtHwAcceleratorGpu);As you can see, the new CompiledModel API greatly simplifies how to specify the model and target backend(s) for acceleration.
While using high performance backends is helpful, optimal performance of your application can be hindered by memory, or processor bottlenecks. With the new LiteRT APIs, you can address these challenges by leveraging built-in buffer interoperability to eliminate costly memory copy operations, and asynchronous execution to utilize idle processors in parallel.
The new TensorBuffer API provides an efficient way to handle input/output data with LiteRT. It allows you to directly use data residing in hardware memory, such as OpenGL Buffers, as inputs or outputs for your CompiledModel, completely eliminating the need for costly CPU copies.
auto tensor_buffer = *litert::TensorBuffer::CreateFromGlBuffer(tensor_type, opengl_buffer);This significantly reduces unnecessary CPU overhead and boosts performance.
Additionally, the TensorBuffer API enables seamless copy-free conversions between different hardware memory types when supported by the system. Imagine effortlessly transforming data from an OpenGL Buffer to an OpenCL Buffer or even to an Android HardwareBuffer without any intermediate CPU transfers.
This technique is key to handling the increasing data volumes and demanding performance required by increasingly complex AI models. You can find examples in our documentation on how to use TensorBuffer.
Asynchronous execution allows different parts of the AI model or independent tasks to run concurrently across CPU, GPU, and NPUs allowing you to opportunistically leverage available compute cycles from different processors to improve efficiency and responsiveness. For instance:
In applications which require real-time AI interactions, a task can be initiated on one processor and continue with other operations on another. Parallel processing minimizes latency and provides a smoother, more interactive user experience. By effectively managing and overlapping computations across multiple processors, asynchronous execution maximizes system throughput and ensures that the AI application remains fluid and reactive, even under heavy computational loads.
Async execution is implemented by using OS-level mechanisms (e.g., sync fences on Android/Linux) allowing one HW accelerator to trigger upon the completion of another HW accelerator directly without involving the CPU. This reduces latency (up to 2x in our GPU async demo) and power consumption while making the pipeline more deterministic.
Here is the code snippet showing async inference with OpenGL buffer input:
// Create an input TensorBuffer based on tensor_type that wraps the given OpenGL
// Buffer. env is an LiteRT environment to use existing EGL display and context.
auto tensor_buffer_from_opengl = *litert::TensorBuffer::CreateFromGlBuffer(env,
tensor_type, opengl_buffer);
// Create an input event and attach it to the input buffer. Internally, it
// creates and inserts a fence sync object into the current EGL command queue.
auto input_event = *Event::CreateManaged(env, LiteRtEventTypeEglSyncFence);
tensor_buffer_from_opengl.SetEvent(std::move(input_event));
// Create the input and output TensorBuffers…
// Run async inference
compiled_model1.RunAsync(input_buffers, output_buffers);More code examples are available in our documentation on how to leverage async execution.
We encourage you to try out the latest acceleration capabilities and performance improvement techniques to bring your users the best possible experience while leveraging the latest AI models. To help you get started, check out our sample app with fully integrated examples of how to use all the features.
All new LiteRT features mentioned in this blog can be found at: https://github.com/google-ai-edge/LiteRT
For more Google AI Edge news, read about our updates in on-device GenAI and our new AI Edge Portal service for broad coverage on-device benchmarking and evals.
Explore this announcement and all Google I/O 2025 updates on io.google starting May 22.
Thank you to the members of the team, and collaborators for their contributions in making the advancements in this release possible: Advait Jain, Alan Kelly, Alexander Shaposhnikov, Andrei Kulik, Andrew Zhang, Akshat Sharma, Byungchul Kim, Chunlei Niu, Chuo-Ling Chang, Claudio Basile, Cormac Brick, David Massoud, Dillon Sharlet, Eamon Hugh, Ekaterina Ignasheva, Fengwu Yao, Frank Ban, Frank Barchard, Gerardo Carranza, Grant Jensen, Henry Wang, Ho Ko, Jae Yoo, Jiuqiang Tang, Juhyun Lee, Julius Kammerl, Khanh LeViet, Kris Tonthat, Lin Chen, Lu Wang, Luke Boyer, Marissa Ikonomidis, Mark Sherwood, Matt Kreileder, Matthias Grundmann, Misha Gutman, Pedro Gonnet, Ping Yu, Quentin Khan, Raman Sarokin, Sachin Kotwani, Steven Toribio, Suleman Shahid, Teng-Hui Zhu, Volodymyr Kysenko, Wai Hon Law, Weiyi Wang, Youchuan Hu, Yu-Hui Chen

On-device small language models with multimodality, RAG, and Function Calling

On-device GenAI in Chrome, Chromebook Plus, and Pixel Watch with LiteRT-LM
Unlocking Peak Performance on Qualcomm NPU with LiteRT

Announcing the Agent Development Kit for Go: Build Powerful AI Agents with Your Favorite Languages

Google AI for game developers

Announcing User Simulation in ADK Evaluation