

Gemma 설명 시리즈의 이전 게시물에서는 RecurrentGemma 아키텍처에 대해 알아봤습니다. 이 블로그 게시물에서는 PaliGemma 아키텍처를 살펴보겠습니다. 자, 출발합니다!
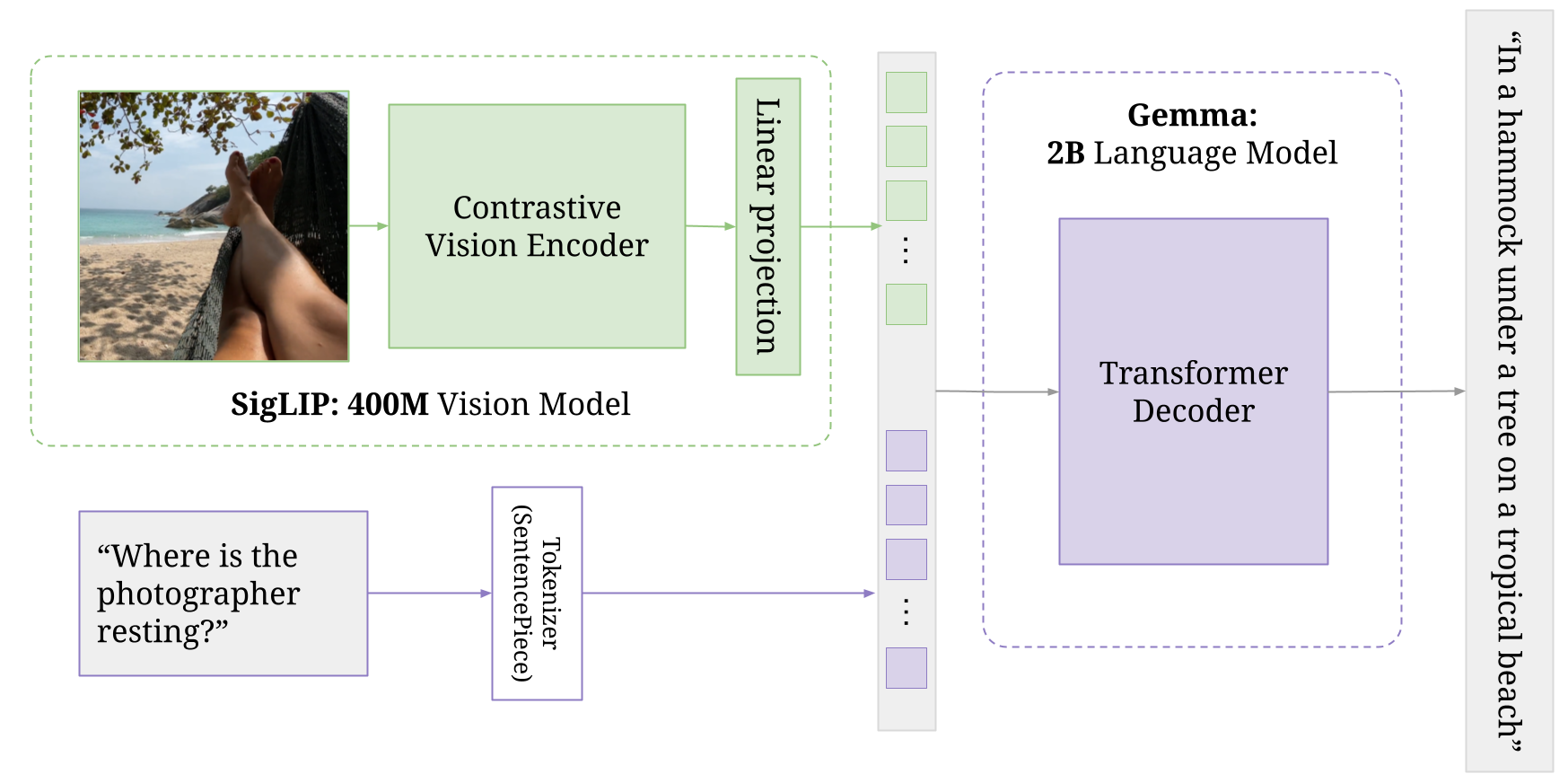
PaliGemma는 PaLI-3에서 영감을 얻은 경량의 개방형 비전 언어 모델(VLM)로, SigLIP 비전 모델 및 Gemma 언어 모델 같은 개방형 구성요소를 기반으로 합니다. Pali는 Pathway Language and Image Model의 약자입니다. 이름에서 알 수 있듯 이 모델은 이미지와 텍스트 입력을 모두 받아 텍스트 응답을 생성할 수 있습니다. 이 미세 조정 가이드에 나와있는 것처럼 말입니다.
PaliGemma는 이미지 인코더로 구성된 BaseGemma 모델에 비전 모델을 더 추가합니다. 이 인코더는 텍스트 토큰과 더불어 특수한 Gemma 2B 모델로 전달됩니다. 비전 모델과 Gemma 모델은 둘 다 다양한 단계를 거치며 독립적 학습과 병행 학습을 모두 진행하여 최종적인 공동 아키텍처를 생성합니다. 자세한 내용은 Pali-3 논문의 섹션 3.2를 참조하십시오.
PaliGemmaForConditionalGeneration(
(vision_tower): SiglipVisionModel(
(vision_model): SiglipVisionTransformer(
(embeddings): SiglipVisionEmbeddings(
(patch_embedding): Conv2d(3, 1152, kernel_size=(14, 14), stride=(14, 14), padding=valid)
(position_embedding): Embedding(256, 1152)
)
(encoder): SiglipEncoder(
(layers): ModuleList(
(0-26): 27 x SiglipEncoderLayer(
(self_attn): SiglipAttention(
(k_proj): Linear(in_features=1152, out_features=1152, bias=True)
(v_proj): Linear(in_features=1152, out_features=1152, bias=True)
(q_proj): Linear(in_features=1152, out_features=1152, bias=True)
(out_proj): Linear(in_features=1152, out_features=1152, bias=True)
)
(layer_norm1): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
(mlp): SiglipMLP(
(activation_fn): PytorchGELUTanh()
(fc1): Linear(in_features=1152, out_features=4304, bias=True)
(fc2): Linear(in_features=4304, out_features=1152, bias=True)
)
(layer_norm2): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
)
)
)
(post_layernorm): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
)
)
(multi_modal_projector): PaliGemmaMultiModalProjector(
(linear): Linear(in_features=1152, out_features=2048, bias=True)
)
(language_model): GemmaForCausalLM(
(model): GemmaModel(
(embed_tokens): Embedding(257216, 2048, padding_idx=0)
(layers): ModuleList(
(0-17): 18 x GemmaDecoderLayer(
(self_attn): GemmaSdpaAttention(
(q_proj): Linear(in_features=2048, out_features=2048, bias=False)
(k_proj): Linear(in_features=2048, out_features=256, bias=False)
(v_proj): Linear(in_features=2048, out_features=256, bias=False)
(o_proj): Linear(in_features=2048, out_features=2048, bias=False)
(rotary_emb): GemmaRotaryEmbedding()
)
(mlp): GemmaMLP(
(gate_proj): Linear(in_features=2048, out_features=16384, bias=False)
(up_proj): Linear(in_features=2048, out_features=16384, bias=False)
(down_proj): Linear(in_features=16384, out_features=2048, bias=False)
(act_fn): PytorchGELUTanh()
)
(input_layernorm): GemmaRMSNorm()
(post_attention_layernorm): GemmaRMSNorm()
)
)
(norm): GemmaRMSNorm()
)
(lm_head): Linear(in_features=2048, out_features=257216, bias=False)
)
)이 구성요소는 입력 이미지를 처리하는 역할을 합니다.
비전 작업을 위해 설계된 트랜스포머 아키텍처의 일종인 SiglipVisionTransformer를 사용합니다.
PaliGemma는 하나 이상의 이미지를 입력으로 받고 이 이미지는 SigLIP 인코더에 의해 '소프트 토큰'으로 변환됩니다.
텍스트 모델이 문장 속 단어를 처리하는 방법과 유사한 방식으로 PaliGemma는 이미지를 더 작은 패치로 분할합니다. 그런 다음 모델이 이러한 패치 간의 관계를 캡처하는 방법을 학습해서 이미지의 시각적 콘텐츠를 효과적으로 이해합니다.
다음 매개변수와 함께 컨볼루션 레이어(Conv2d)를 사용합니다.
공간 정보(즉, 원본 이미지에서 각 패치가 있는 위치)를 인코딩하기 위해 각 패치 임베딩에 위치 임베딩이 추가됩니다.
이는 각 패치의 위치(최대 256개 위치)를 입력으로 받아 (패치 임베딩 차원과 동일하게) 크기가 1152인 벡터를 출력하도록 학습된 임베딩 레이어(Embedding)를 사용하여 수행됩니다.
해당 임베딩은 일련의 SiglipEncoderLayer를 통과하는데, 각 SiglipEncoderLayer는 셀프 어텐션 및 피드 포워드 신경망으로 구성됩니다. 이는 모델이 이미지의 다양한 부분 간 관계를 포착하는 데 도움이 됩니다.
이 구성요소는 비전 타워의 출력을 멀티 모달 공간에 투영합니다. 단순한 선형 레이어를 사용하여 투영되며 이를 통해 비전과 언어 표현을 효과적으로 결합할 수 있습니다.
이 구성요소는 Gemma 2B 모델을 기반으로 하는 언어 모델입니다.
프로젝터에서 멀티 모달 표현을 입력으로 받아 텍스트 출력을 생성합니다.
텍스트 입력의 경우, 각 검사점은 다양한 시퀀스 길이로 학습되었습니다. 예를 들어, paligemma-3b-mix-224는 시퀀스 길이 256(Gemma의 토크나이저로 토큰화된 입력 텍스트 + 출력 텍스트)으로 학습되었습니다.
PaliGemma는 256,000개의 토큰을 가진 Gemma 토크나이저를 사용하지만, 정규화된 이미지 공간(<loc0000>...<loc1023>)에 좌표를 표시하는 1,024개의 항목과 경량의 참조-표현식 세분화 벡터-양자화 변형 자동 인코더(VQ-VAE)에서 사용되는 코드워드인 128개의 항목(<seg000>...<seg127>)을 사용해 어휘를 확장합니다. (256000 + 1024 + 128 = 257216)
추가 소프트 토큰은 객체 감지 및 이미지 세분화를 인코딩합니다. 다음은 paligemma-3b-mix-224의 출력 예입니다. HuggingFace 라이브 데모에서 직접 사용해 볼 수 있습니다.

'segment floor;cat;person;' 프롬프트와 함께 PaliGemma에서 출력

ML 및 컴퓨터 비전 작업에 익숙하지 않은 경우에는 모델의 출력을 직관적으로 디코딩하기 어렵습니다.
초기 4개의 위치 토큰은 0~1023 범위에서 경계 상자의 좌표를 나타냅니다. 이미지의 크기가 1024 x 1024로 조정된 것으로 가정하므로 이러한 좌표는 가로세로 비율과 무관합니다.
예를 들어, 출력은 좌표 (382, 637) 및 (696, 784) 내에 고양이의 위치를 표시합니다. 이 좌표계에서 좌측 상단 모서리는 (0,0)으로 표시되고 수직 좌표는 수평 좌표 앞에 나열됩니다.

마스크는 다음 16개의 세분화 토큰으로 인코딩됩니다. 신경망 모델(VQ-VAE)은 해당 값을 디코딩하여 양자화된 표현(코드북 인덱스)에서 마스크를 재구성할 수 있습니다. 여기에서 실제 코드를 살펴볼 수 있습니다.
모든 과정을 거치면 PaliGemma의 출력에서 이렇게 멋진 결과물을 얻을 수 있습니다.

이 기사에서는 PaliGemma에 대해 알아보았습니다.
Gemma 제품군은 핵심 아키텍처는 유사하지만 다양한 사용 사례에 맞게 설계된 개방형 가중치 모델 컬렉션을 제공함으로써 최신 대규모 언어 모델 시스템을 이해할 수 있는 특별한 기회를 제공합니다. Google이 연구원, 개발자, 최종 사용자를 위해 출시한 이들 모델은 여러 기능과 다양한 수준의 복잡성을 갖추고 있습니다.
오늘 알려 드린 개요가 Gemma 모델 제품군에 대한 간명한 이해를 돕고 광범위한 작업에서 해당 제품군이 얼마나 유용하고 적합한지 잘 소개했길 바랍니다.
Google Developer Community Discord 서버는 프로젝트를 선보이고 동료 개발자와의 관계를 구축하며 대화형 토론에 참여할 수 있는 훌륭한 플랫폼입니다. 이 서버에 가입해서 이러한 흥미로운 기회를 탐색해 보세요.
읽어주셔서 감사합니다!

Announcing the Data Commons Gemini CLI extension

EmbeddingGemma 출시: 온디바이스 임베딩을 위한 동급 최고의 개방형 모델
Coral NPU 소개: Edge AI를 위한 풀 스택 플랫폼

Gemma 3 270M 소개: 초효율적인 AI를 위한 콤팩트 모델

Building with Gemini 3 in Jules

Introducing Metrax: performant, efficient, and robust model evaluation metrics in JAX