
'Gemma 설명' 시리즈의 이전 게시물에서 Gemma 모델 제품군의 아키텍처에 대한 개요를 상세히 설명했습니다. 각 게시물로 연결되는 링크는 아래에서 확인하실 수 있습니다.
이 게시물에서는 최신 모델인 Gemma 3에 대해 자세히 알아보겠습니다.
Gemma 3와 이전 버전과의 큰 차이점은 새로운 비전 언어 기능 지원입니다. 이번 구현에 맞춰 특별히 조정되긴 했지만, PaliGemma의 아키텍처에 익숙한 분이라면 Gemma 3에 사용된 SigLIP 인코더를 알아보실 수도 있습니다.
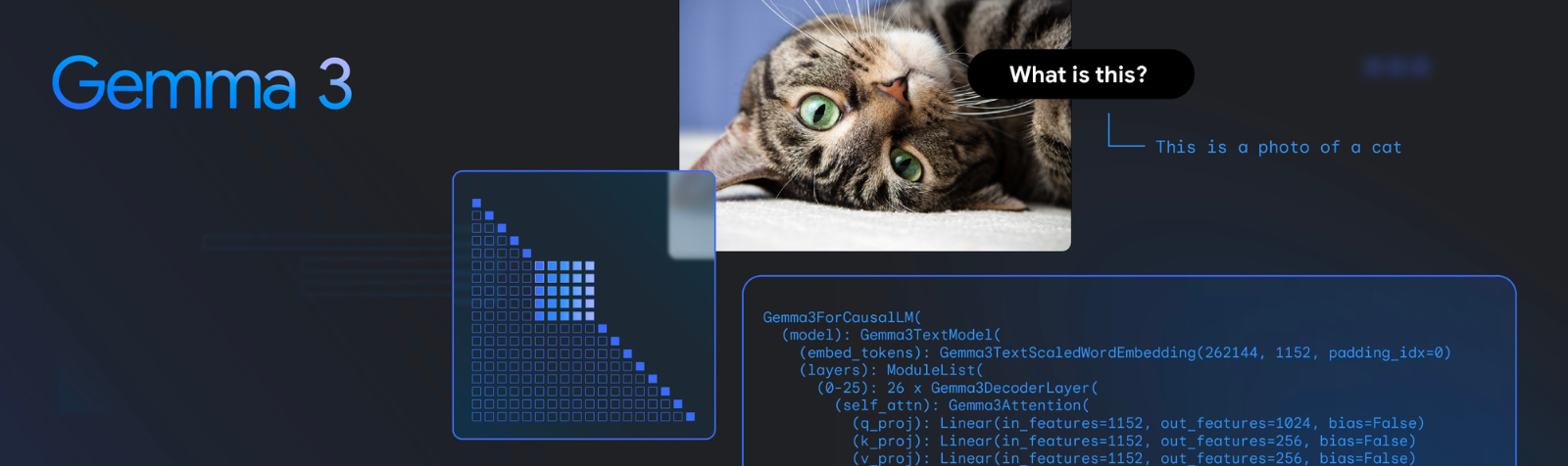
새 모델의 핵심 매개변수는 다음과 같습니다.
Gemma 3의 주요 차이점과 개선점을 살펴보겠습니다.
Gemma 3의 아키텍처는 이전 아키텍처의 여러 부분을 계승하지만 아래에 설명된 것처럼 새롭게 변경된 사항도 있습니다.
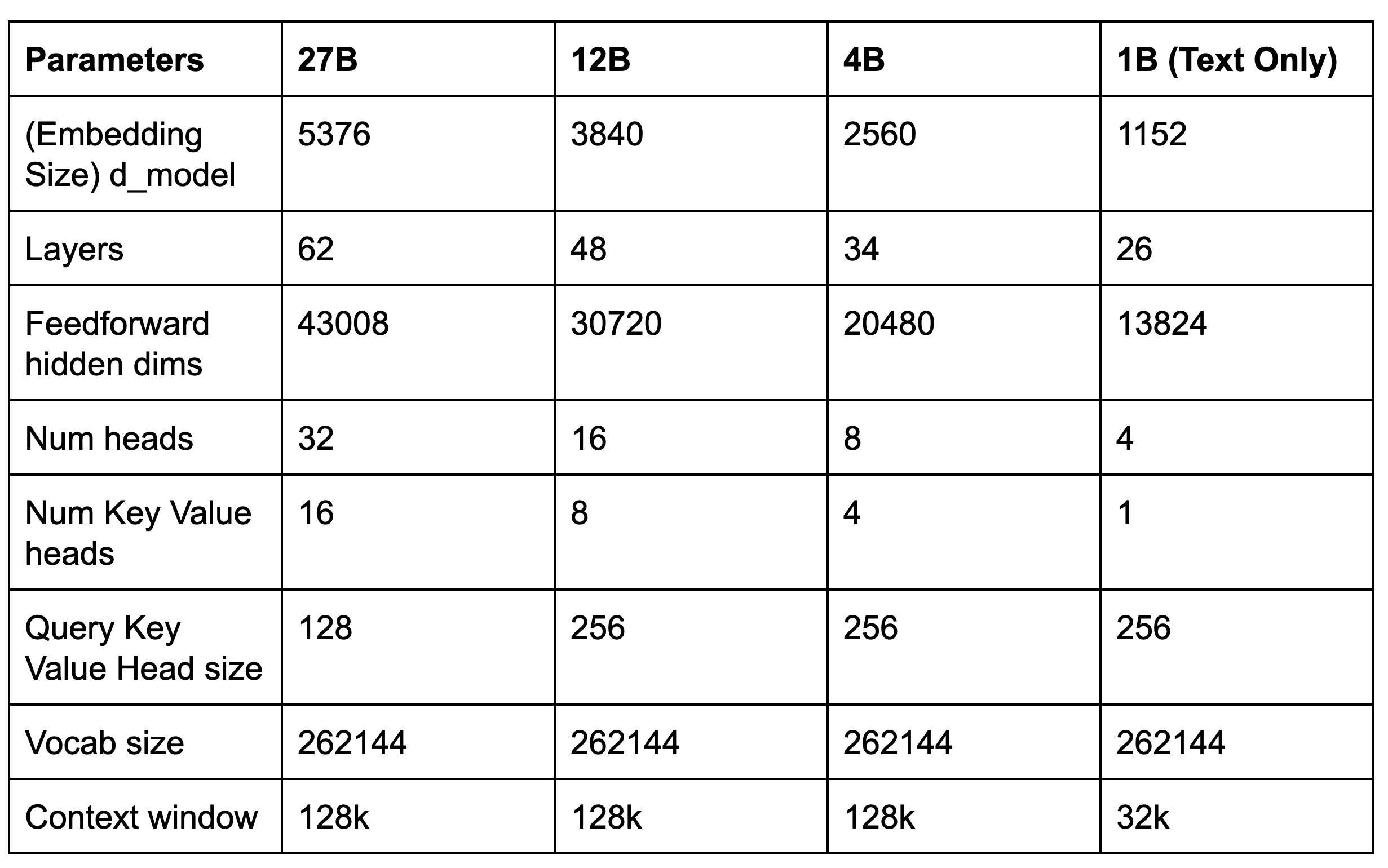
Gemma 3에서 향상된 주요 기능은 새로운 비전 언어 이해 기능입니다. 4B, 12B 및 27B 모델은 맞춤형 SigLIP 비전 인코더를 사용하여 모델이 시각적 입력을 해석할 수 있도록 합니다.
비전 인코더는 고정된 896x896 정사각형 이미지에서 작동합니다. 다양한 가로세로 비율이나 고해상도 이미지를 처리하기 위해 'Pan&Scan' 알고리즘이 사용됩니다. 여기에는 이미지를 적당히 자르고 잘린 이미지의 크기를 896x896으로 조정한 다음 인코딩하는 과정이 포함됩니다. 이 방법을 사용하면 성능은 향상되지만, 특히 상세한 정보가 중요한 경우에는 추론 중에 계산 오버헤드가 증가합니다.
또한 Gemma 3는 이미지를 MultiModalProjector에 의해 생성된 콤팩트한 '소프트 토큰'의 시퀀스로 취급합니다. 이 기법은 256개로 고정된 수의 벡터로 시각적 데이터를 표현함으로써 이미지 처리에 필요한 추론 리소스를 크게 줄입니다.
다음으로 넘어가기 전에 'Gemma 3와 PaliGemma 2는 언제 사용해야 하는가?'라는 궁금증이 생길 수 있습니다.
PaliGemma 2의 강점은 이미지 분할 및 객체 감지 등 Gemma 3에서는 볼 수 없는 기능에 있습니다. 그러나 Gemma 3는 PaliGemma의 기술을 통합 및 확장하여 다양한 비전 작업을 직접 처리할 수 있는 멀티 턴 채팅과 강력한 제로 샷 성능을 제공합니다.
무엇을 사용할지 최종 결정을 할 때에는 사용 가능한 컴퓨팅 리소스와 Gemma 3가 눈에 띄게 개선한 긴 컨텍스트 또는 다국어 지원과 같은 고급 기능의 중요성도 고려해야 합니다.
긴 컨텍스트에서 함께 증가하는 경향이 있는 KV 캐시 메모리 사용량을 줄이도록 아키텍처를 수정했습니다.
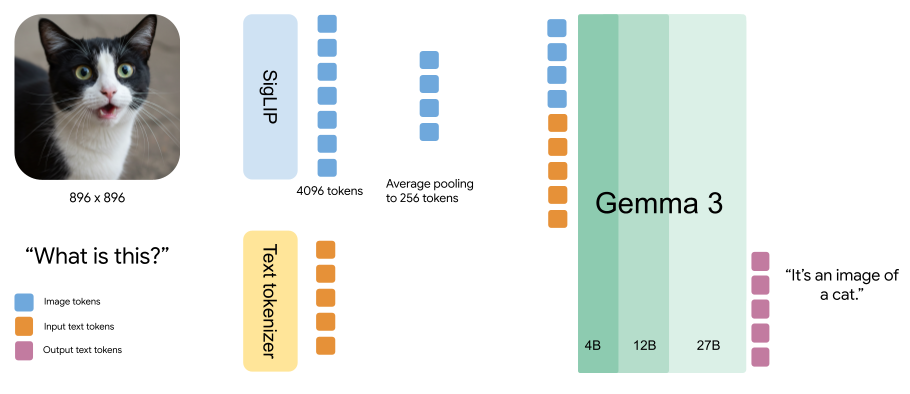
업데이트된 모델 아키텍처는 반복되는 인터리빙 블록으로 구성되며, 각 블록에는 슬라이딩 윈도우가 1024인 5개의 로컬 어텐션 레이어와 1개의 전역 어텐션 레이어가 포함됩니다. 이렇게 디자인된 모델은 단거리 및 장거리 종속성을 모두 캡처하여 보다 정확하고 상황에 맞는 응답을 내놓을 수 있습니다.
참고: Gemma 1은 전역 어텐션에만 의존했지만 Gemma 2는 로컬 어텐션 레이어와 전역 어텐션 레이어를 번갈아 가며 사용하는 하이브리드 방식을 도입했습니다. Gemma 3는 전용 로컬 어텐션 레이어 5개를 통합하여 보다 정확하고 상황에 맞는 응답을 제공합니다.
Gemma 2와 Gemma 3는 모두 RMSNorm을 적용한 사후 정규화 및 사전 정규화와 함께 GQA(Grouped-Query Attention)를 활용합니다. 그러나 Gemma 3는 Gemma 2의 소프트 캡핑 메커니즘 대신 QK 정규화를 채택하여 향상된 정확도와 더욱 빨라진 처리 속도를 모두 달성합니다.
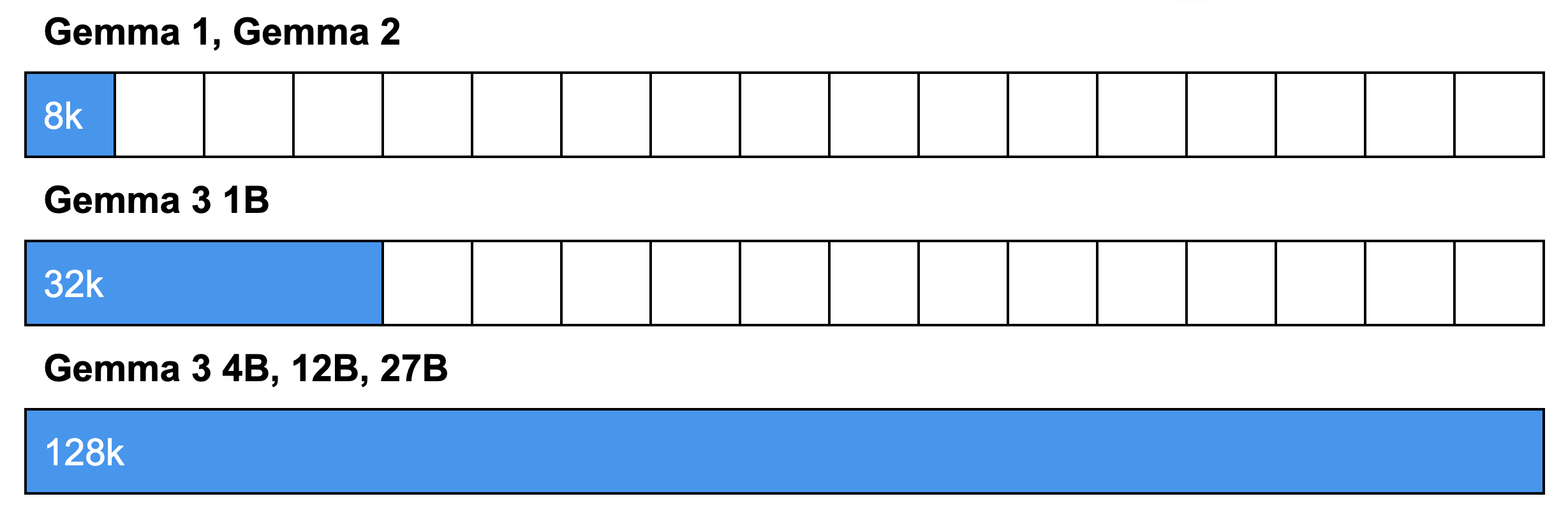
위에서 설명한 아키텍처 변경의 결과, Gemma 3는 메모리 요구 사항을 줄이기 위해 인터리빙된 어텐션을 활용하고 이를 통해 길어진 컨텍스트를 지원할 수 있습니다. 덕분에 맥락을 잃지 않고 더 긴 문서와 대화를 분석할 수 있습니다. 특히 1B 모델의 경우 32k개의 토큰을 처리하고 더 큰 모델의 경우 128k개의 토큰을 처리할 수 있습니다.
참고: 128k 토큰 컨텍스트 윈도우를 사용하면 모델이 일반적인 소설(약 80,000단어)에 해당할 정도로 많은 양의 텍스트를 처리할 수 있습니다. 이 윈도우 크기는 약 96,000단어, 198페이지, 500개 이미지 또는 프레임 속도 1fps로 촬영한 동영상 8분 정도의 분량입니다.
Gemma 3는 이미지 입력에 양방향 어텐션만 사용합니다.
정상 어텐션(일명 단방향 어텐션)은 마치 독서와 같습니다. 책을 읽는다고 상상해 보세요. 앞에 나온 단어를 생각하면서 다음에 나오는 단어를 이해합니다. 이것이 바로 언어 모델에서 일반적인 어텐션이 작동하는 방식입니다. 즉, 순차적이며 지나간 내용을 복기하며 컨텍스트를 구축합니다.
반면에 양방향 어텐션은 퍼즐을 보는 것과 같습니다. 이미지를 그림 맞추기 퍼즐이라고 생각해 보세요. '이미지 토큰'은 개별 퍼즐 조각과 같습니다. 즉, 각각의 조각이 위치에 관계없이 이미지의 다른 모든 조각을 '보고' 각 조각과 연결됩니다. 시퀀스뿐 아니라 전체 그림을 한 번에 고려합니다. 모든 부분이 다른 모든 부분과 관련되어 있으므로 이런 방식으로 전체를 이해하게 됩니다.
그렇다면 항상 양방향 어텐션을 사용하는 게 낫지 않냐고 물으실 수 있습니다. 양방향 어텐션(전체 맥락을 보는 것)이 더 나은 것처럼 들리지만 항상 텍스트에 사용되는 것은 아닙니다. 결국 모든 건 어떤 작업이냐에 달렸습니다.
주요 차이점은 모델이 시퀀스를 생성하지 않을 때는 양방향 방식이 사용된다는 점입니다.
아래는 Gemma 3의 어텐션 메커니즘을 시각화한 것입니다.
코드:
from transformers.utils.attention_visualizer import AttentionMaskVisualizer
visualizer = AttentionMaskVisualizer("google/gemma-3-4b-it")
visualizer("<start_of_turn>user\n<img>What is this?<end_of_turn>\n<start_of_turn>model\nIt's an image of a cat.<end_of_turn>")출력:

또한 이 어텐션 메커니즘이 PaliGemma의 어텐션 메커니즘과 어떻게 다른지 알 수 있습니다. 이러한 비교를 위한 컨텍스트를 제공하기 위해, PaliGemma는 텍스트 기반 작업 설명(프롬프트 또는 접두사)과 함께 하나 이상의 이미지를 수신함으로써 작동하고, 그 이후에는 자동 회귀 방식으로 예측 결과를 텍스트 문자열(답변 또는 접미사)로 생성합니다.
코드:
visualizer = AttentionMaskVisualizer("google/paligemma2-3b-mix-224")
visualizer("<img> caption en", suffix="a cat standing on a beach.")출력

Gemma 3는 다국어 데이터(단일 언어 데이터와 병렬 데이터 모두 포함)의 비중을 높인 수정된 데이터 혼합 덕분에 다국어 기능이 향상되었습니다.
또한 Gemma 3에서는 토크나이저가 개선되었습니다. 어휘 규모가 262k로 바뀌었지만 동일한 SentencePiece 토크나이저를 사용합니다. 오류를 방지하려면 Gemma 3에서 새 토크나이저를 사용하세요. 영어 이외의 언어에 대해 더욱 균형 잡힌 Gemini와 동일한 토크나이저입니다.
Gemma3ForConditionalGeneration(
(vision_tower): SiglipVisionModel(
(vision_model): SiglipVisionTransformer(
(embeddings): SiglipVisionEmbeddings(
(patch_embedding): Conv2d(3, 1152, kernel_size=(14, 14), stride=(14, 14), padding=valid)
(position_embedding): Embedding(4096, 1152)
)
(encoder): SiglipEncoder(
(layers): ModuleList(
(0-26): 27 x SiglipEncoderLayer(
(self_attn): SiglipSdpaAttention(
(k_proj): Linear(in_features=1152, out_features=1152, bias=True)
(v_proj): Linear(in_features=1152, out_features=1152, bias=True)
(q_proj): Linear(in_features=1152, out_features=1152, bias=True)
(out_proj): Linear(in_features=1152, out_features=1152, bias=True)
)
(layer_norm1): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
(mlp): SiglipMLP(
(activation_fn): PytorchGELUTanh()
(fc1): Linear(in_features=1152, out_features=4304, bias=True)
(fc2): Linear(in_features=4304, out_features=1152, bias=True)
)
(layer_norm2): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
)
)
)
(post_layernorm): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
)
)
(multi_modal_projector): Gemma3MultiModalProjector(
(mm_soft_emb_norm): Gemma3RMSNorm((1152,), eps=1e-06)
(avg_pool): AvgPool2d(kernel_size=4, stride=4, padding=0)
)
(language_model): Gemma3ForCausalLM(
(model): Gemma3TextModel(
(embed_tokens): Gemma3TextScaledWordEmbedding(262208, 5376, padding_idx=0)
(layers): ModuleList(
(0-61): 62 x Gemma3DecoderLayer(
(self_attn): Gemma3Attention(
(q_proj): Linear(in_features=5376, out_features=4096, bias=False)
(k_proj): Linear(in_features=5376, out_features=2048, bias=False)
(v_proj): Linear(in_features=5376, out_features=2048, bias=False)
(o_proj): Linear(in_features=4096, out_features=5376, bias=False)
(q_norm): Gemma3RMSNorm((128,), eps=1e-06)
(k_norm): Gemma3RMSNorm((128,), eps=1e-06)
)
(mlp): Gemma3MLP(
(gate_proj): Linear(in_features=5376, out_features=21504, bias=False)
(up_proj): Linear(in_features=5376, out_features=21504, bias=False)
(down_proj): Linear(in_features=21504, out_features=5376, bias=False)
(act_fn): PytorchGELUTanh()
)
(input_layernorm): Gemma3RMSNorm((5376,), eps=1e-06)
(post_attention_layernorm): Gemma3RMSNorm((5376,), eps=1e-06)
(pre_feedforward_layernorm): Gemma3RMSNorm((5376,), eps=1e-06)
(post_feedforward_layernorm): Gemma3RMSNorm((5376,), eps=1e-06)
)
)
(norm): Gemma3RMSNorm((5376,), eps=1e-06)
(rotary_emb): Gemma3RotaryEmbedding()
(rotary_emb_local): Gemma3RotaryEmbedding()
)
(lm_head): Linear(in_features=5376, out_features=262208, bias=False)
)
)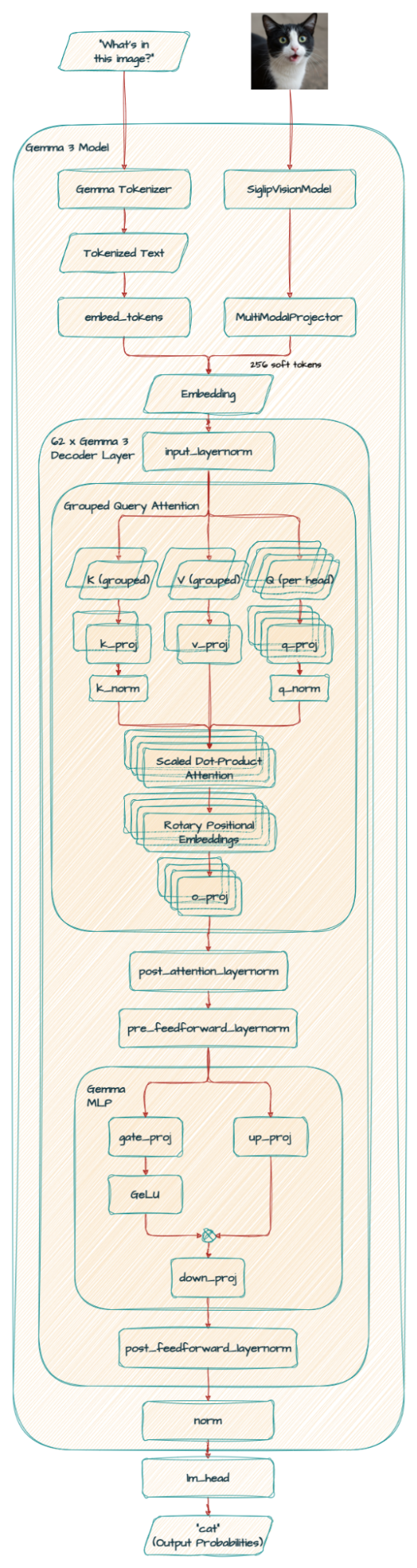
참고: 기술적으로 RoPE(Rotary Positional Embedding)는 SDPA(Scaled Dot-Product Attention) 내부에 있지만, 이 다이어그램에서는 단순하게 표현했습니다. 정확한 아키텍처 세부 사항은 코드 를 확인하세요.
Gemma3ForCausalLM(
(model): Gemma3TextModel(
(embed_tokens): Gemma3TextScaledWordEmbedding(262144, 1152, padding_idx=0)
(layers): ModuleList(
(0-25): 26 x Gemma3DecoderLayer(
(self_attn): Gemma3Attention(
(q_proj): Linear(in_features=1152, out_features=1024, bias=False)
(k_proj): Linear(in_features=1152, out_features=256, bias=False)
(v_proj): Linear(in_features=1152, out_features=256, bias=False)
(o_proj): Linear(in_features=1024, out_features=1152, bias=False)
(q_norm): Gemma3RMSNorm((256,), eps=1e-06)
(k_norm): Gemma3RMSNorm((256,), eps=1e-06)
)
(mlp): Gemma3MLP(
(gate_proj): Linear(in_features=1152, out_features=6912, bias=False)
(up_proj): Linear(in_features=1152, out_features=6912, bias=False)
(down_proj): Linear(in_features=6912, out_features=1152, bias=False)
(act_fn): PytorchGELUTanh()
)
(input_layernorm): Gemma3RMSNorm((1152,), eps=1e-06)
(post_attention_layernorm): Gemma3RMSNorm((1152,), eps=1e-06)
(pre_feedforward_layernorm): Gemma3RMSNorm((1152,), eps=1e-06)
(post_feedforward_layernorm): Gemma3RMSNorm((1152,), eps=1e-06)
)
)
(norm): Gemma3RMSNorm((1152,), eps=1e-06)
(rotary_emb): Gemma3RotaryEmbedding()
(rotary_emb_local): Gemma3RotaryEmbedding()
)
(lm_head): Linear(in_features=1152, out_features=262144, bias=False)
)이 텍스트 전용 1B 모델은 특별히 온디바이스용으로 최적화되어 모바일 시스템과 임베디드 시스템에서 고급 AI에 액세스할 수 있게 해줍니다. AI 기반 애플리케이션은 네트워크 연결이 제한적이거나 아예 없어도 효율적으로 작동할 수 있으므로 이는 접근성과 개인정보 보호 및 성능에 큰 영향을 미칩니다.
Google의 기술 보고서에 세부 내용을 심층적으로 설명했지만 Gemma 3의 주요 결과를 간략히 요약하면 다음과 같습니다.
Gemma 3의 아키텍처를 살펴보고 이전 버전과 차별화되는 새로운 기능에 대해 다루었습니다. 이러한 아키텍처를 선택하면 Gemma 3가 향상된 다국어 기능 및 이미지 상호 작용 등 더 광범위한 여러 작업에서 더 뛰어난 성능을 발휘할 수 있으며, 표준 하드웨어에 적합한, 더 유능하고 리소스 친화적인 미래의 멀티모달 언어 모델을 위한 토대를 마련할 수 있습니다.
Gemma 3의 혁신을 통해 연구자와 개발자가 효율적이고 강력한 차세대 멀티모달 언어 모델을 만들 수 있을 것으로 믿습니다.
읽어주셔서 감사합니다!

Announcing the Data Commons Gemini CLI extension

EmbeddingGemma 출시: 온디바이스 임베딩을 위한 동급 최고의 개방형 모델
Coral NPU 소개: Edge AI를 위한 풀 스택 플랫폼

Gemma 3 270M 소개: 초효율적인 AI를 위한 콤팩트 모델

Building with Gemini 3 in Jules

Introducing Metrax: performant, efficient, and robust model evaluation metrics in JAX