

Gemma 徹底解説の前回の投稿では、RecurrentGemma のアーキテクチャについて確認しました。今回のブログ投稿では、PaliGemma のアーキテクチャについて説明します。さっそく始めましょう!
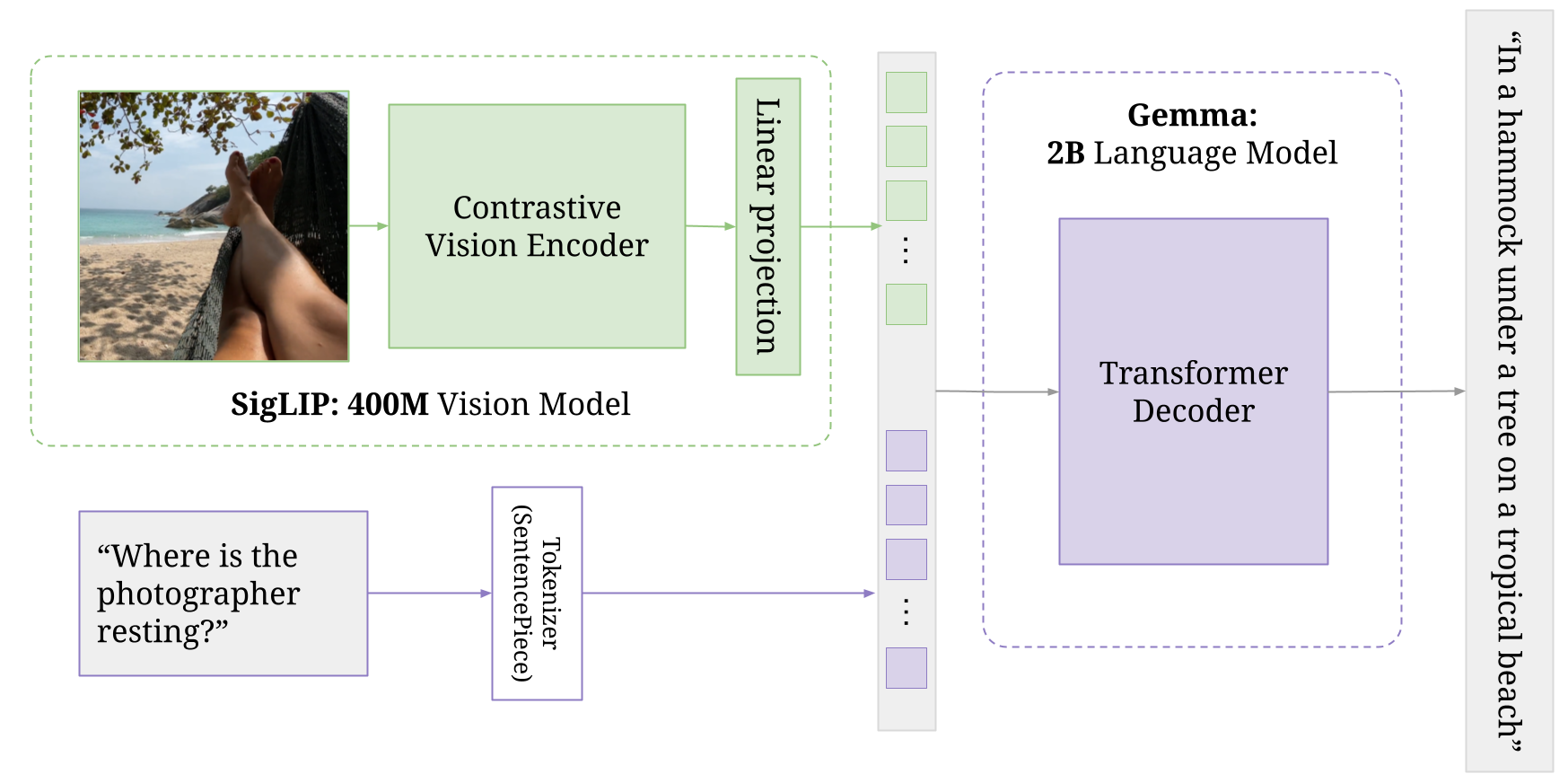
PaliGemma は、PaLI-3 に触発された軽量オープン視覚言語モデル(VLM)で、SigLIP 視覚モデルや Gemma 言語モデルなどのオープン コンポーネントがベースになっています。Pali は、Pathway Language and Image Model の略です。名前からわかるように、このモデルは、画像とテキストの両方の入力を受け取り、テキストの応答を生成できます。詳しくは、こちらのファイン チューニング ガイドをご覧ください。
PaliGemma は、画像エンコーダで構成される視覚モデルを BaseGemma モデルに追加します。このエンコーダとテキスト トークンが、専用の Gemma 2B モデルに渡されます。視覚モデルと Gemma モデルは、どちらもさまざまなステージで独立してトレーニングされており、この 2 つを組み合わせることで、最終的な統合アーキテクチャができあがります。詳しい説明は、Pali-3 の論文の 3.2 節をご覧ください。
PaliGemmaForConditionalGeneration(
(vision_tower): SiglipVisionModel(
(vision_model): SiglipVisionTransformer(
(embeddings): SiglipVisionEmbeddings(
(patch_embedding): Conv2d(3, 1152, kernel_size=(14, 14), stride=(14, 14), padding=valid)
(position_embedding): Embedding(256, 1152)
)
(encoder): SiglipEncoder(
(layers): ModuleList(
(0-26): 27 x SiglipEncoderLayer(
(self_attn): SiglipAttention(
(k_proj): Linear(in_features=1152, out_features=1152, bias=True)
(v_proj): Linear(in_features=1152, out_features=1152, bias=True)
(q_proj): Linear(in_features=1152, out_features=1152, bias=True)
(out_proj): Linear(in_features=1152, out_features=1152, bias=True)
)
(layer_norm1): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
(mlp): SiglipMLP(
(activation_fn): PytorchGELUTanh()
(fc1): Linear(in_features=1152, out_features=4304, bias=True)
(fc2): Linear(in_features=4304, out_features=1152, bias=True)
)
(layer_norm2): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
)
)
)
(post_layernorm): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
)
)
(multi_modal_projector): PaliGemmaMultiModalProjector(
(linear): Linear(in_features=1152, out_features=2048, bias=True)
)
(language_model): GemmaForCausalLM(
(model): GemmaModel(
(embed_tokens): Embedding(257216, 2048, padding_idx=0)
(layers): ModuleList(
(0-17): 18 x GemmaDecoderLayer(
(self_attn): GemmaSdpaAttention(
(q_proj): Linear(in_features=2048, out_features=2048, bias=False)
(k_proj): Linear(in_features=2048, out_features=256, bias=False)
(v_proj): Linear(in_features=2048, out_features=256, bias=False)
(o_proj): Linear(in_features=2048, out_features=2048, bias=False)
(rotary_emb): GemmaRotaryEmbedding()
)
(mlp): GemmaMLP(
(gate_proj): Linear(in_features=2048, out_features=16384, bias=False)
(up_proj): Linear(in_features=2048, out_features=16384, bias=False)
(down_proj): Linear(in_features=16384, out_features=2048, bias=False)
(act_fn): PytorchGELUTanh()
)
(input_layernorm): GemmaRMSNorm()
(post_attention_layernorm): GemmaRMSNorm()
)
)
(norm): GemmaRMSNorm()
)
(lm_head): Linear(in_features=2048, out_features=257216, bias=False)
)
)このコンポーネントは、入力画像の処理を担当します。
ここでは、視覚タスク向けに設計されたトランスフォーマー アーキテクチャの一種である SiglipVisionTransformer が使われています。
PaliGemma が受け取る入力は、1 つ以上の画像です。この画像は、SigLIP エンコーダによって「ソフトトークン」に変換されます。
画像は小さなパッチに分割されます。これは、テキストモデルが文の中の単語を処理するのに似ています。次に、モデルはパッチ間の関係をキャプチャして学習し、画像の視覚コンテンツを効果的に理解します。
以下のパラメータを持つ畳み込みレイヤ(Conv2d)を使います。
各パッチの埋め込みに位置埋め込みを追加し、空間情報(各パッチの元の画像内の位置)をエンコードします。
これは、学習済みの埋め込みレイヤ(Embedding)を使って行います。このレイヤは、各パッチの位置(最大 256 か所)を入力として受け取り、サイズ 1152 (パッチ埋め込みの次元と同じ)のベクトルを出力します。
埋め込みは、一連の SiglipEncoderLayer を通過します。各レイヤは、セルフアテンションとフィード フォワード ニューラルネットワークで構成されています。これにより、モデルが画像の異なる部分間の関係をキャプチャできます。
このコンポーネントは、vision_tower の出力をマルチモーダル空間に射影します。単純な線形レイヤを使い、視覚表現と言語表現を効果的に組み合わせます。
このコンポーネントは、Gemma 2B モデルをベースとした言語モデルです。
射影結果のマルチモーダル表現を入力として受け取り、テキスト出力を生成します。
テキスト入力は、各チェックポイントをさまざまなシーケンス長でトレーニングしました。たとえば、paligemma-3b-mix-224 は、シーケンス長 256(入力テキスト+出力テキスト、Gemma のトークナイザーでトークン化したもの)でトレーニングしています。
PaliGemma は、256000 トークンの Gemma トークナイザーを使いますが、語彙は拡張されており、正規化した画像空間の座標用に 1024 エントリ(<loc0000>...<loc1023>)が、軽量参照表現のセグメンテーション手法であるベクトル量子化変分オートエンコーダ(VQ-VAE)に使うコードワードとしてさらに 128 エントリ(<seg000>...<seg127>)が追加されています(256000 + 1024 + 128 = 257216)。
追加のソフトトークンで、オブジェクト検出と画像セグメンテーションをエンコードします。次に示すのは、paligemma-3b-mix-224 の出力例です。HuggingFace のライブデモで実際にお試しいただけます。

PaliGemma にプロンプト “segment floor;cat;person;” を与えたときの出力

ML やコンピュータ ビジョンのタスクに不慣れな方は、モデルからの出力を直感的に読み解けないかもしれません。
最初の 4 つの位置トークンは、境界ボックスの座標を示します。これは 0 から 1023 までの範囲になります。画像のサイズを 1024 x 1024 とみなすので、座標はアスペクト比と無関係です。
たとえば、座標 (382, 637) と (696, 784) にある猫の位置が出力に表示されます。この座標系では、左上隅が (0,0) となり、垂直座標が水平座標の前に来ます。

マスクは、次の 16 個のセグメンテーション トークンでエンコードされます。ニューラル ネットワーク モデル(VQ-VAE)は、この値をデコードすることで、量子化表現(コードブック インデックス)からマスクを復元できます。実際のコードはこちらから確認できます。
最終的に、PaliGemma の出力から、このようなすばらしい結果を得ることができます。

今回の記事では、PaliGemma について学びました。
Gemma ファミリーには、類似したコア アーキテクチャを持ちながらも、異なるユースケース向けに設計されたオープンな重みのモデルがそろっており、最新の大規模言語モデルシステムを理解するうえで、他にはない機会を提供しています。これらのモデルには、さまざまな機能と複雑さのものがあり、いずれも Google が研究者やデベロッパー、エンドユーザーに向けて公開しています。
今回の説明を通して、Gemma モデル ファミリーの概要を理解していただき、その汎用性や適合性のおかげで幅広いタスクに利用できることを覚えておいていただければ何よりです。
Google デベロッパー コミュニティ Discord サーバーは、プロジェクトを紹介したり、仲間のデベロッパーとつながったり、インタラクティブなディスカッションに合流したりできる絶好のプラットフォームです。ぜひ参加して、このエキサイティングなチャンスを活用しましょう。
お読みいただき、ありがとうございました!

EmbeddingGemma の概要: オンデバイス埋め込み処理向けの最高水準オープンモデル

Building with Gemini 3 in Jules
Coral NPU のご紹介: エッジ AI 向けフルスタック プラットフォーム

Gemma 3 270M の概要: 超高効率 AI のためのコンパクト モデル

Announcing the Data Commons Gemini CLI extension

Introducing Metrax: performant, efficient, and robust model evaluation metrics in JAX