
Google은 AI가 모든 사람에게 도움이 되어야 한다고 생각합니다. 그러나 수많은 주요 대형 언어 모델(LLM)이 전 세계에서 사용되는 수천 가지 언어 중 극히 일부만 이해한다면 AI가 포용성을 갖기란 참 어렵습니다. 이로 인해 많은 모델이 의도치 않게 각 사회를 고유하게 만드는 문화적, 언어적 차이를 간과하게 되고, LLM이 잠재적으로 수십억 명의 사람들에게 제공할 수 있는 엄청난 혜택도 제한됩니다.
이제 가볍고 효율적인 공개 모델 제품군인 Gemma 덕분에 전 세계의 개발자와 연구자들은 이처럼 특정한 문화적 차이를 다루는 LLM 개발을 위한 도구를 갖게 되었습니다. Gemini를 만드는 데 사용된 것과 동일한 연구와 기술을 활용하는 Gemma는 여러 언어의 텍스트를 효율적으로 이해하여 다국어 성능을 향상시키고 비용을 절감하며 진정으로 포용적인 AI를 만드는 데 더 큰 유연성을 제공합니다.
INSAIT, AI Singapore 등의 팀은 이미 Gemma 변형 모델을 사용하여 새로운 가능성을 창출하기 위한 역량을 갖추어 왔습니다. INSAIT가 gemma-2-27b를 기반으로 최근에 출시한 최첨단 불가리아어 모델인 BgGPT와 AI Singapore가 gemma-2-9b를 기반으로 개발한 획기적이고 새로운 동남아시아 언어용 모델인 SEA-LIONv3는 두 팀이 문화적 지식과 AI 전문 기술을 결합하여 각 지역사회의 고유한 니즈를 충족하는 새로운 LLM을 만든 방법을 보여줍니다.
여러분도 영감을 받으셨나요? 1월 14일까지 열리는 Kaggle 기반의 Unlock Global Communication with Gemma 경연대회에 참가하여 AI의 포용성과 혁신의 한계를 넘어서는 데 기여할 수 있습니다.
동남아시아(SEA)의 다양한 언어와 문화가 기존 LLM에서 과소 대표된다는 점을 알게 된 AI Singapore 개발자들은 이 지역 특유의 뉘앙스, 맥락, 문화적 다양성을 더 잘 반영하는 SEA-LION을 만들었습니다. 이 모델 제품군은 이미 현지의 SEA 지역사회에 막대한 영향을 미쳐 왔습니다. 예를 들어, Gemma를 기반으로 한 최신 SEA-LION 모델은 Sahabat-AI의 토대가 되었습니다. Sahabat-AI는 GoPay 앱과 Gojek 앱에서 AI 음성 비서를 구동하기 위해 GoTo가 개발한 인도네시아의 LLM입니다. 이를 통해 수백만의 인도네시아인이 현지 언어와 방언으로 이러한 앱 서비스를 보다 익숙하게 사용할 수 있습니다.
SEA 언어를 위한 선도적인 LLM을 개발하는 데 있어 가장 큰 난관은 고품질의 다양한 학습 데이터를 찾는 것이었습니다. 그래서 AI Singapore 팀은 Google DeepMind 및 Google 연구팀과 협력해서 동남아시아 전역에서 사용되는 여러 언어로 대규모 언어 모델(LLM)을 학습, 미세 조정, 평가하는 데 사용될 수 있는 데이터 세트를 향상시키기 위한 Project SEALD을 추진했습니다. AI Singapore 팀은 또한 사용된 데이터가 관련성이 있는지 확인해야 했습니다. 이는 곧 해당 지역의 실제 언어 및 문화적 유산을 반영하지 않는 도박 콘텐츠나 광고를 걸러내는 일이었습니다. 이 문제를 해결하기 위해 각 모델의 번역이 정확하고 다양한 배경을 가진 사용자에게 자연스럽게 느껴질 수 있도록 원어민과 언어 전문가로 구성된 실무 그룹을 편성했습니다.
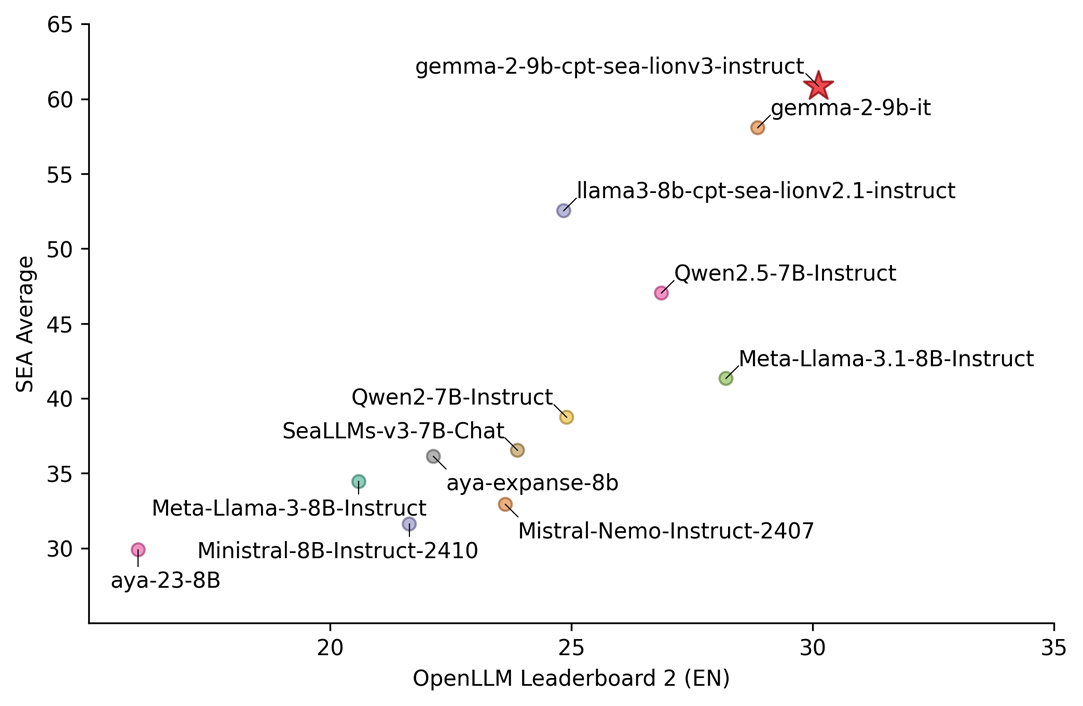
SEA-LION의 최신 V3 반복 버전이 AI Singapore 팀의 가장 앞선 버전입니다. Gemma 2-9B에서 지속적으로 사전 학습된 이 버전은 다국어 구사 능력과 작업 성능을 크게 향상시켜 지금까지 중 가장 우수한 성능을 자랑하는 모델입니다. 이 버전은 또한 11가지 동남아시아 언어는 물론이고 자바어, 순다어 등 주요 방언도 지원하는 동시에 영어에서도 강력한 성능을 유지합니다.
AI Singapore 팀의 기초 모델 응용 연구 책임자 William Tjhi에 따르면, 팀은 더욱 우수한 접근성을 보장하기 위해 더 큰 기본 모델보다는 매개변수 90억 개 규모의 모델을 선택했다고 합니다. "많은 SEA 사용자가 ‘처리량에 제약’을 겪습니다. 또한 더 큰 모델을 사용해 대규모로 추론을 실행하는 데 필요한 계산 리소스를 보유하지 못할 수도 있습니다."
INSAIT(Institute for Computer Science, Artificial Intelligence, and Technology)의 연구자들은 불가리아어용으로 세 가지 새로운 LLM을 만들어 AI 언어 포용성에 있어 놀라운 이점을 창출했습니다. INSAIT의 최신 모델은 Gemma 2 제품군을 기반으로 개발되었으며 영어 및 수학 숙련도 같은 기본 Gemma 2 모델의 기술을 중요하게 유지하면서도 훨씬 더 큰 불가리아어 모델의 성능을 능가합니다.
INSAIT의 새로운 LLM은 개방형 AI 개발이 다양한 언어적 맥락에서 어떻게 혁신을 주도할 수 있는지 그 힘을 강조합니다. INSAIT 팀의 성공은 협업하는 openLLM이 더 큰 독점 모델의 기능과 어떻게 경쟁하는지 (때로는 능가하는지) 잘 보여줍니다.
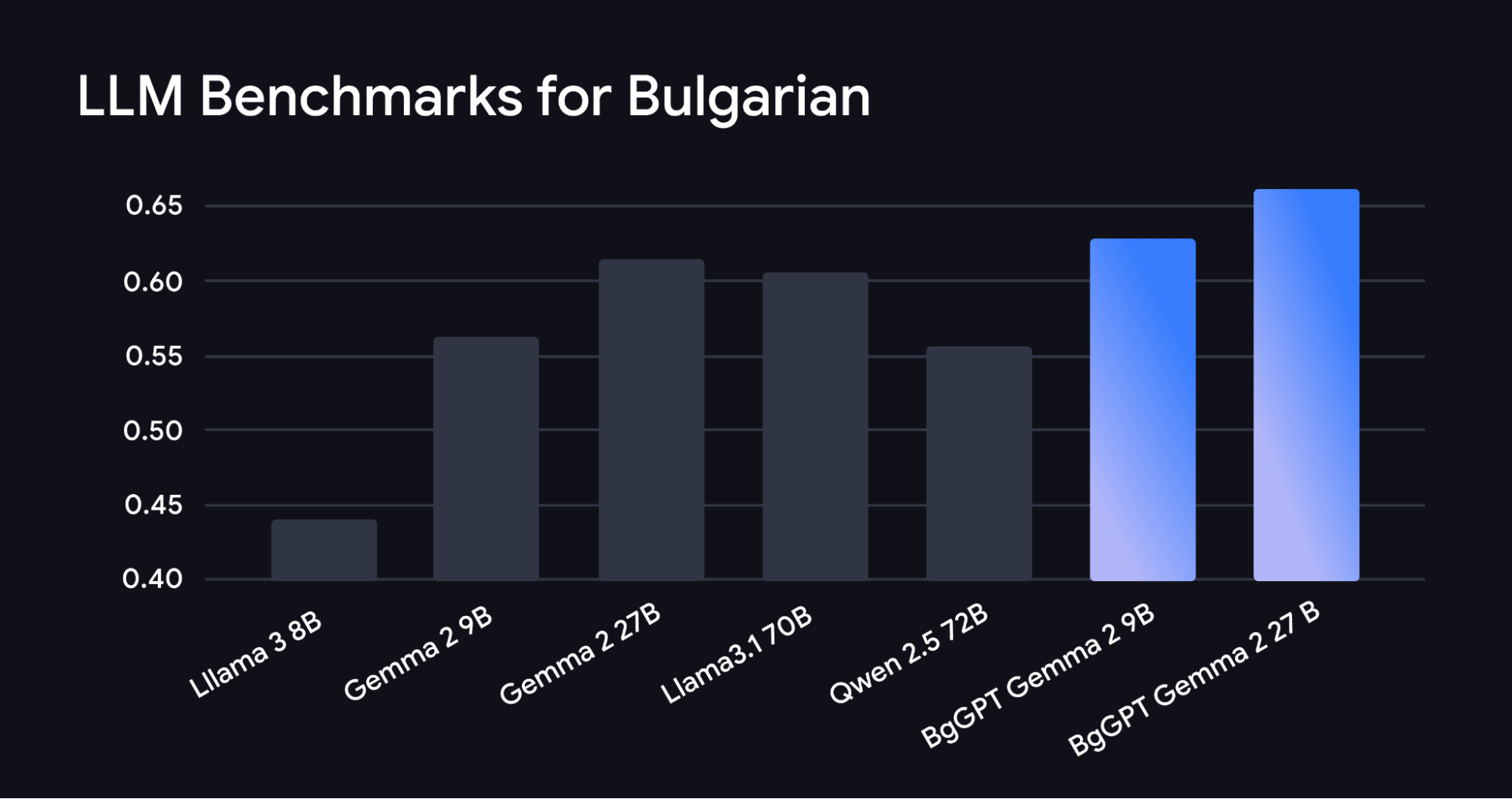
INSAIT의 최첨단 불가리아어 모델은 다른 언어용으로 확장 가능한 접근 방식을 보여줍니다. INSAIT 연구진은 불가리아어로 약 850억 개의 토큰에 대한 지속적인 사전 학습을 포함하여 기본 Gemma 2 모델에 많은 개선 사항을 추가했습니다. 또한 자연어 처리를 논의하는 인기 콘퍼런스인 EMNLP 2024의 새로운 연구를 기반으로 한 새로운 연속 사전 학습, 지시문 미세 조정, 모델 병합 체계도 포함했습니다. 이 연구는 '파괴적 망각'을 완화하기 위한 새로운 방법도 도입합니다. '파괴적 망각'은 AI 모델이 새로운 기술(불가리아어)에 대해 학습된 후 이전에 학습된 기술(영어, 수학)을 잊어버리는 현상을 말합니다.
"INSAIT가 보여준 결과는 불가리아 크기의 국가라도 개방형 모델, 고급 AI 연구, 특수 데이터 수집 및 훈련 기술을 사용하여 자체 최첨단 AI 모델을 구축할 수 있음을 가시적으로 보여주었다는 점에서 의미가 있습니다. ETH Zurich의 정교수이자 INSAIT의 과학 이사인 Martin Vechev는 "우리 모델은 불가리아어를 대상으로 하지만 EMNLP 2024에서 도입한 분기 및 병합 방법은 재앙을 완화합니다. 망각은 새로운 언어를 습득하는 데에도 적용됩니다.”
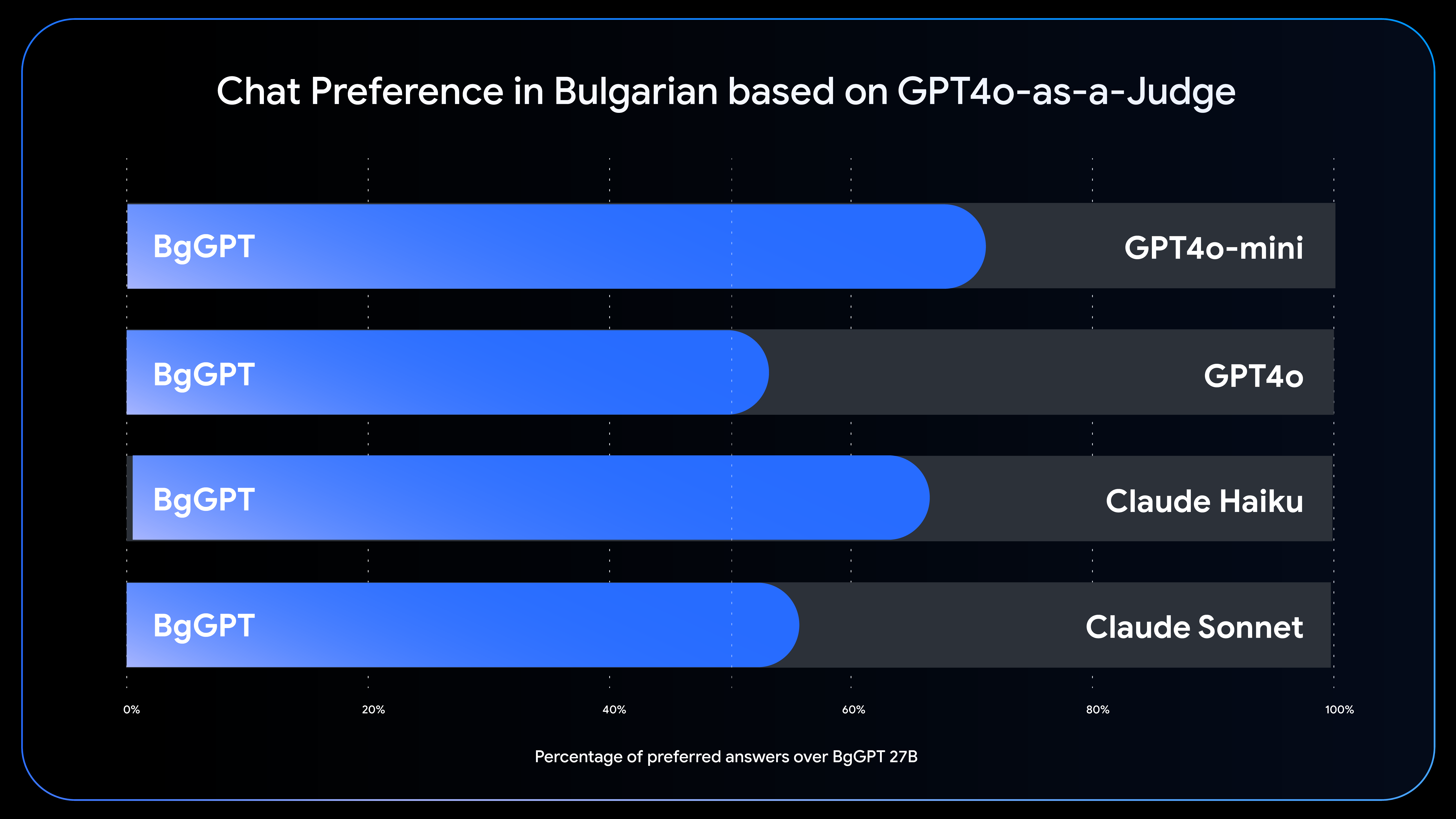
오늘날 INSAIT의 개방형 모델은 고성능 불가리아어 언어 모델에 대한 무료 액세스를 제공합니다. 이를 통해 불가리아 내에서 자연어 처리 성능이 발전하고 현지화된 AI 솔루션 개발에 관심이 있는 다른 사람들도 더 많은 기회를 얻을 수 있습니다. INSAIT는 BgGPT-Gemma 모델 변형을 기반으로 하는 전국적인 공개 채팅 시스템을 출시하기도 했습니다. 유럽의 정부 기관이 일반인이 이용 가능한 무료 공개 생성형 AI 모델을 기반으로 한 전국적인 채팅 시스템을 출시한 것은 이번이 처음입니다.
AI Singapore와 INSAIT의 이러한 개방형 모델 출시는 AI 접근의 대중화와 지역사회의 역량 강화로 나아가는 중요한 진일보를 의미합니다. 두 팀 모두 AI 솔루션 개발에서 언어적 다양성의 중요성을 강조하고 Gemma와 같은 개방형 모델 솔루션을 통해 이를 쉽게 달성할 수 있음을 보여주었습니다.
현지화된 LLM의 가능성은 방대합니다. 지역사회를 위한 새로운 기회를 창출하기 위해 최신 AI 기술을 사용하는 야심 찬 개발자들이 정말 자랑스럽습니다. 그래서 저희는 이러한 스토리에서 영감을 받은 분들에게 Kaggle 대회에 참여하도록 권하고 있습니다. 이 대회는 해당되는 73개 언어에 대해 Gemma 2 개방형 모델 제품군을 적용하는 데 중점을 두고 있습니다.
저희는 이처럼 다양한 언어를 통해 개발자가 전 세계 모든 지역사회를 위해 더 향상되고 더 포용적인 LLM을 만드는 데 도움이 될 리소스와 권장사항의 기초를 마련하고 있습니다. 오늘 바로 대회에 참여해 보세요. 최종 제출 마감일은 2025년 1월 14일입니다!

Gemini로 다중 스펙트럼 데이터 활용

Announcing the Data Commons Gemini CLI extension

Grain 및 ArrayRecord를 사용하여 고성능 데이터 파이프라인 구축

EmbeddingGemma 출시: 온디바이스 임베딩을 위한 동급 최고의 개방형 모델

Gemma 3 270M 소개: 초효율적인 AI를 위한 콤팩트 모델

Building with Gemini 3 in Jules