
At Google, we believe AI should be helpful for everyone. But it’s hard for AI to be inclusive when so many prominent large language models (LLM) only understand a small fraction of the thousands of languages spoken around the world. This leads many models to unintentionally overlook the cultural and linguistic differences that make each society unique, limiting the immense benefits that LLMs can offer to potentially billions of people.
With Gemma, our family of lightweight and efficient open models, developers and researchers across the globe now have the tools to build LLMs that address these specific cultural differences. Leveraging the same research and technology used to create Gemini, Gemma efficiently understands text across languages, leading to improved multilingual performance, reduced costs, and greater flexibility for creating truly inclusive AI.
Teams like those at INSAIT and AI Singapore have already been empowered to create new possibilities using Gemma variants. INSAIT’s recent release of BgGPT, a state-of the-art Bulgarian model based on gemma-2-27b and AI Singapore’s SEA-LIONv3, a groundbreaking new model for Southeast Asian languages based on gemma-2-9b show how through blending their cultural knowledge and AI expertise, both teams have managed to create new LLMs that meet the unique needs of their communities.
Inspired? You can contribute to pushing the boundaries of inclusivity and innovation in AI by joining the Unlock Global Communication with Gemma competition on Kaggle, open till January 14.
Recognizing that Southeast Asia’s (SEA) diverse languages and cultures were underrepresented in existing LLMs, AI Singapore developers created SEA-LION to better reflect the region’s nuances, contexts, and cultural diversity. This family of models has already had an immense impact on local SEA communities. For example, the latest SEA-LION’s model based on Gemma has become the foundation for Sahabat-AI, an Indonesian LLM built by GoTo to power the AI voice assistant on their GoPay app and Gojek app. This allows millions of Indonesians to more naturally use these app services in their local languages and dialects.
The biggest challenge in building a leading LLM for SEA languages was finding high-quality diverse training data. This is why the team collaborated with Google DeepMind & Google Research on Project SEALD, an effort to enhance datasets that can be used to train, fine-tune, and evaluate large language models (LLMs) in languages spoken across Southeast Asia. The team also had to ensure the data they used was relevant, which meant filtering out gambling content or ads that didn’t reflect the region’s true linguistic and cultural heritage. To solve this, they built a working group of native speakers and linguists to ensure each model’s translation was accurate and felt natural for users of different backgrounds.
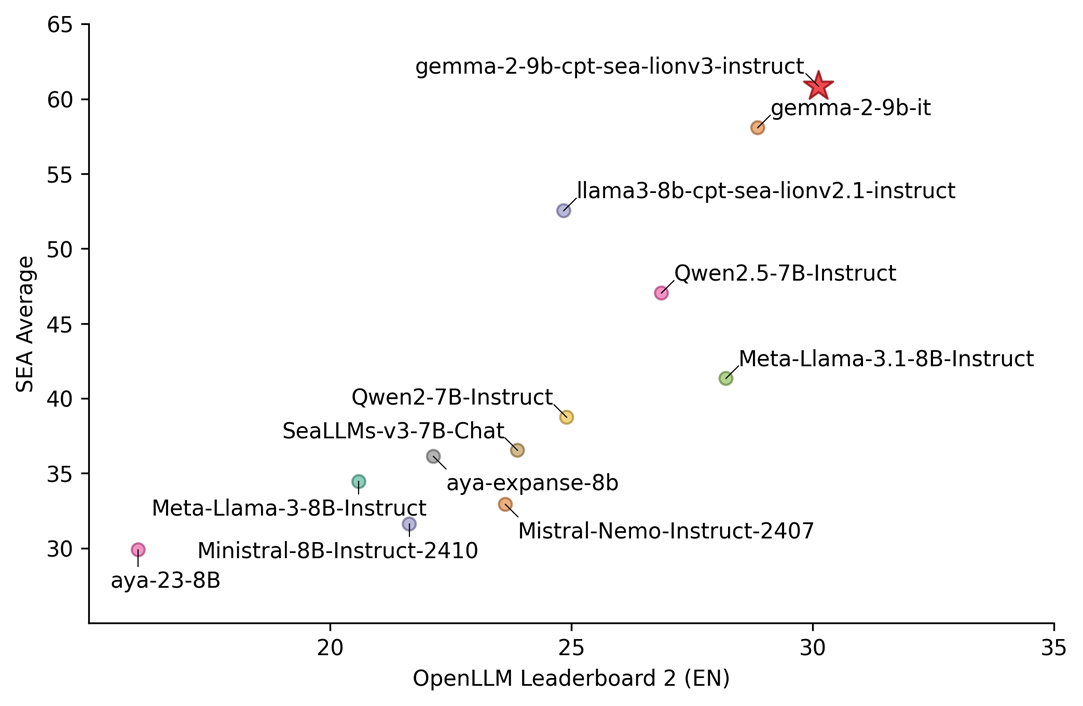
SEA-LION’s latest V3 iteration is the team’s most advanced yet. Continuously pre-trained on Gemma 2-9B, this version significantly improves multilingual proficiency and task performance, making it their best-performing model to date. This version also supports 11 Southeast Asian languages, as well as major dialects such as Javanese and Sundanese, while maintaining strong performance in English.
According to William Tjhi, head of applied research for foundation models at AI Singapore, the team chose the 9 billion parameter model over the larger base model to ensure greater accessibility: “Many SEA users are ‘throughput constrained’ and may not have the computational resources required to run inferences at scale with larger models.”
Researchers at the Institute for Computer Science, Artificial Intelligence, and Technology (INSAIT) have also made incredible gains in AI language inclusivity by creating three new LLMs for the Bulgarian language. INSAIT’s latest models are built on top of the Gemma 2 family and outperform much larger Bulgarian models while importantly maintaining the skills of the base Gemma 2 model, like English and mathematical proficiency.
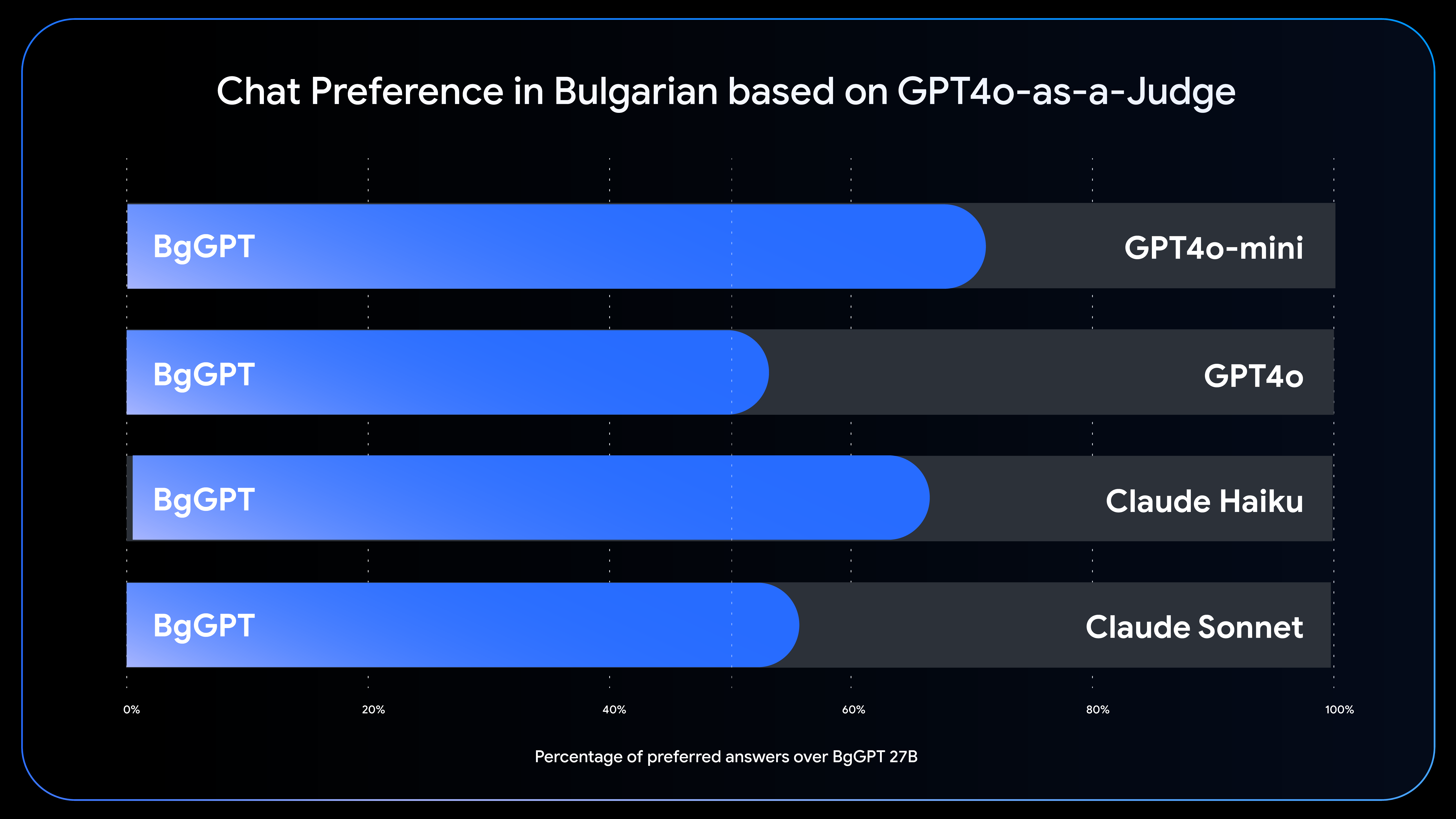
INSAIT’s new LLMs underscore the power of how open AI development can drive innovation in diverse linguistic contexts. The team's success highlights how collaborative, openLLMs can rival—and often exceed—the capabilities of larger proprietary models.
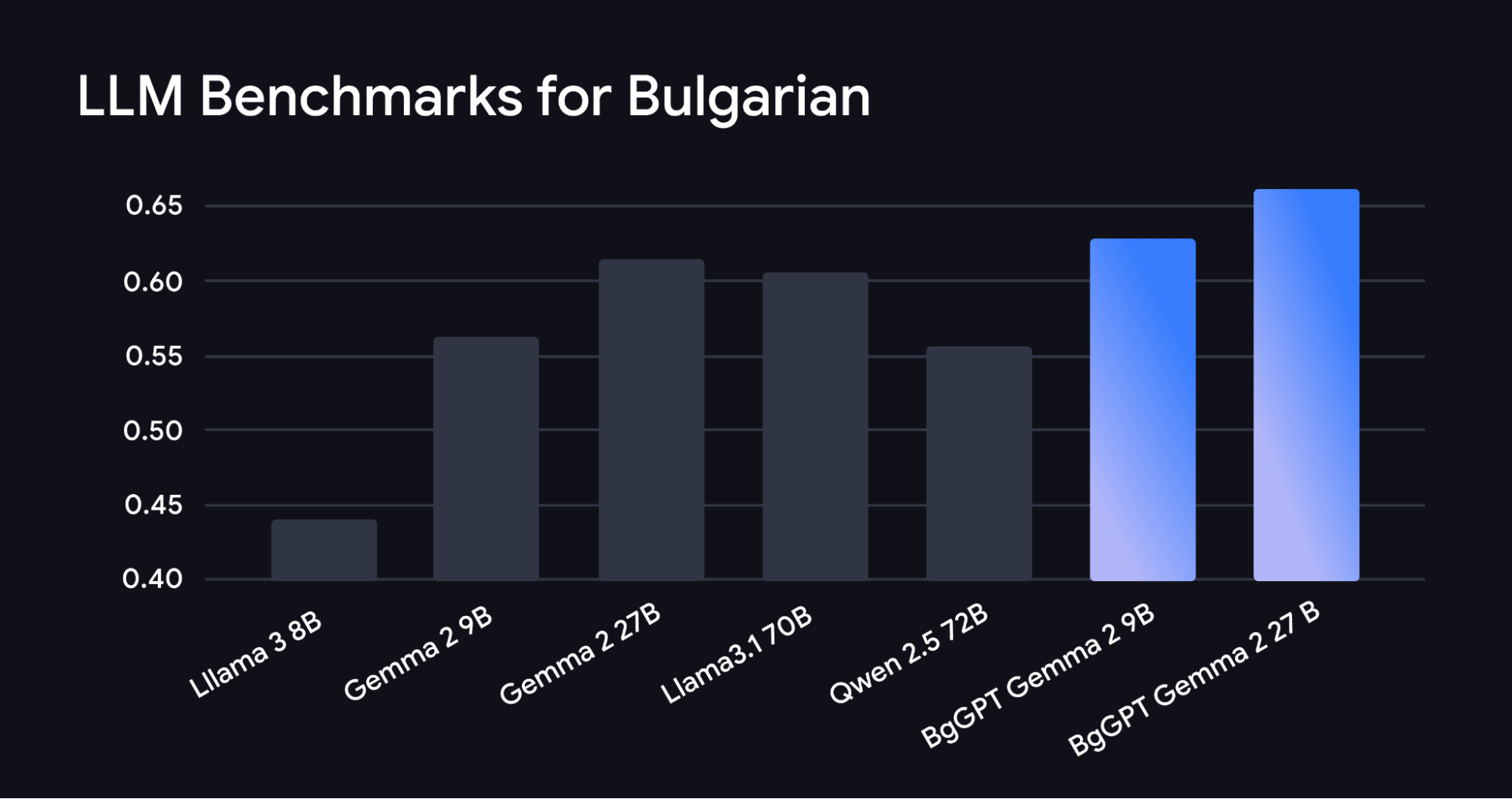
INSAIT’s state-of-the-art Bulgarian language models demonstrate a scalable approach for other languages. Its researchers added many improvements to the base Gemma 2 model, including continuous pre-training on around 85 billion tokens in Bulgarian. They also included novel continuous pre-training, instruction-fine tuning, and a model merging scheme based on new research from EMNLP 2024, a popular conference for natural language processing. The research introduces a new method for mitigating “catastrophic forgetting,” a phenomenon where AI models forget previously learned skills (English, math) after being trained on new ones (Bulgarian).
"The result shown by INSAIT is significant because it visibly demonstrates that even a country the size of Bulgaria can build its own state-of-the-art AI models by relying on open models, advanced AI research, and special data acquisition and training techniques,” said Martin Vechev, a full professor at ETH Zurich and scientific director of INSAIT. "While our models target Bulgarian, the branch-and-merge method we introduced in EMNLP 2024 to mitigate catastrophic forgetting applies to acquiring new languages.”
Today, INSAIT’s open models provide free access to high-performing Bulgarian language models, advancing natural language processing within Bulgaria and offering greater opportunities for others interested in developing localized AI solutions. INSAIT has even launched a nationwide public chat system based on its BgGPT-Gemma model variants. This is the first time a European government institution has launched a nationwide chat system based on its own publicly available, free, and open generative AI models.
The release of these open models from AI Singapore and INSAIT represents a significant step towards democratizing AI access and empowering local communities. Both teams highlight the importance of linguistic diversity in developing AI solutions and have shown that it is easily achievable through open-model solutions like Gemma.
The possibilities with localized LLMs are vast, and we’re proud to see ambitious developers using the latest AI technologies to create new opportunities for their communities. That’s why we invite anyone inspired by these stories to join our Kaggle competition focused on adapting the Gemma 2 open model family for 73 eligible languages.
With this diverse selection of languages, we are compiling a foundation of resources and best practices to help developers create better and more inclusive LLMs for communities all over the world. Join the competition today; the final submission deadline is January 14, 2025!

An important update: Transitioning Gemini CLI to Antigravity CLI

Google Tensor SDK Beta with LiteRT

Introducing EmbeddingGemma: The Best-in-Class Open Model for On-Device Embeddings

Introducing Gemma 3 270M: The compact model for hyper-efficient AI

Building real-world on-device AI with LiteRT and NPU

Supercharging LLM inference on Google TPUs: Achieving 3X speedups with diffusion-style speculative decoding