
Google は、すべての人に役立つ AI を目指しています。しかし、多くの有名な大規模言語モデル(LLM)が、世界で使われている数千の言語のほんの一部しか理解しないなら、AI がインクルーシブなものになるのは難しいでしょう。その場合、多くのモデルで、それぞれの社会を唯一無二なものにしている文化や言語の違いが意図せずに見落とされることになり、何十億という人々に可能性をもたらすことができる LLM の大きなメリットが制限されてしまいます。
Gemma は、私たちの軽量で効率的なオープンモデル ファミリーです。これにより、世界中のデベロッパーや研究者は、そのような細かい文化的違いに対処する LLM を開発するツールを利用できるようになっています。Gemma には Gemini と同じ研究技術が活用されています。異なる言語のテキストの効率的な理解、高い多言語能力の発揮、コストの削減、高い柔軟性といった特徴を備えているので、真にインクルーシブな AI を実現できます。
INSAIT や AI Singapore といったチームは、すでに Gemma のバリアントを使って新たな可能性を創造しています。INSAIT が最近公開した gemma-2-27b ベースの最先端ブルガリア語モデルである BgGPT、そして AI Singapore の gemma-2-9b をベースとした革新的な東南アジア言語モデル SEA-LIONv3 は、文化的知識と AI の専門知識を融合させることで、コミュニティ独自のニーズを満たす新しい LLM を作成できることを実証したものです。
これに触発された方は、Gemma でグローバル コミュニケーションを実現するための Kaggle コンペティションに参加し、AI の包括性とイノベーションの限界を広げることに挑戦しましょう。開催期間は 1 月 14 日までです。
既存の LLM では東南アジアの多様な言語や文化が過小評価されていることに AI Singapore のデベロッパーは気付き、この地域の細かな文化的差異、背景、多様性を反映するために、SEA-LION を作成しました。このモデル ファミリーは、すでに現地の東南アジア コミュニティに大きな影響を与えています。たとえば、Gemma ベースの最新の SEA-LION モデルは、GoTo が開発したインドネシア語 LLM である Sahabat-AI の基盤になり、GoPay アプリや Gojek アプリの AI 音声アシスタントに活用されています。そのおかげで、たくさんのインドネシア人が、こういったアプリのサービスを現地の言語や方言で自然に利用できるようになっています。
東南アジア言語向けの強力な LLM を作るうえで最大の課題となったのは、多様で質の高いトレーニング データを見つけることでした。そこで、Google DeepMind や Google Research と協力し、Project SEALD を実施しました。これは、大規模言語モデル(LLM)を東南アジア言語でトレーニング、ファインチューニング、評価するためのデータセットを増強する取り組みです。また、間違いなく適切なデータを使う必要もありました。これは、ギャンブル関係のコンテンツや、地域の言語的および文化的な遺産を真の意味で反映していない広告を除外することを意味します。これを実現するため、ネイティブ スピーカーと言語の専門家によるワーキング グループを作り、モデルの翻訳が正確で、さまざまな背景のユーザーにとって自然に感じられるようにしました。
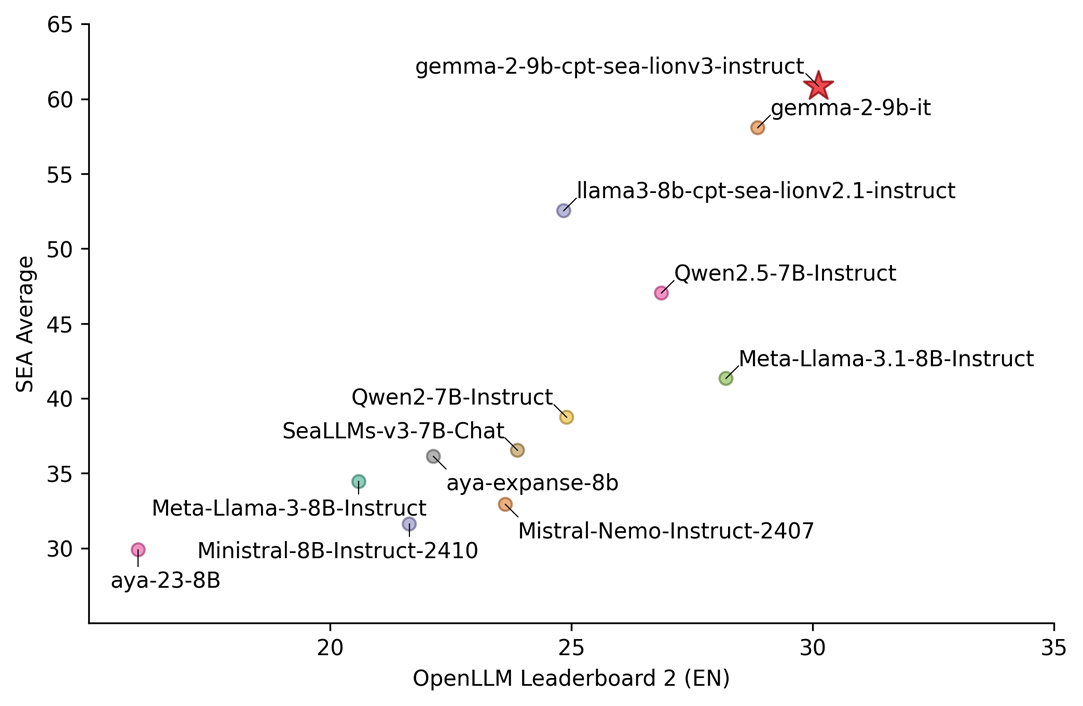
SEA-LION の最新版である V3 は、このチームの最新鋭のモデルです。このバージョンは、Gemma 2-9B をベースに継続的な事前トレーニングを行うことで、多言語対応能力やタスクのパフォーマンスが大幅に向上しており、これまでで最高のパフォーマンスを発揮するモデルになりました。英語での強力なパフォーマンスを維持しながら、東南アジアの 11 の言語、そしてジャワ語やスンダ語などの主要な方言に対応しています。
AI Singapore の基盤モデル応用研究責任者である William Tjhi 氏によると、このチームがさらに大きなモデルではなく 90 億パラメータ モデルを選んだのは、広く利用できるようにするためです。「多くの東南アジアのユーザーは、『スループットが制約されている』ため、大きなモデルで大規模な推論を行うために必要な計算リソースがない可能性があります」
Institute for Computer Science, Artificial Intelligence, and Technology(INSAIT)の研究者たちも、3 つの新しいブルガリア語 LLM を作成することを通して、AI の言語包括性を大きく進展させました。INSAIT の最新モデルは、Gemma 2 ファミリーをベースに開発されており、高度な英語や数学の能力など、基本的な Gemma 2 モデルのスキルを維持しながら、はるかに大きなモデルをしのぐブルガリア語の能力を実現しています。
INSAIT の新しい LLM は、オープンな AI 開発が多言語領域でのイノベーションの原動力となっていることを示しています。このチームの成功は、オープンな LLM のコラボレーションによって、大規模な専用モデルの機能に匹敵する、またはそれを上回るモデルを作ることができることを実証しています。
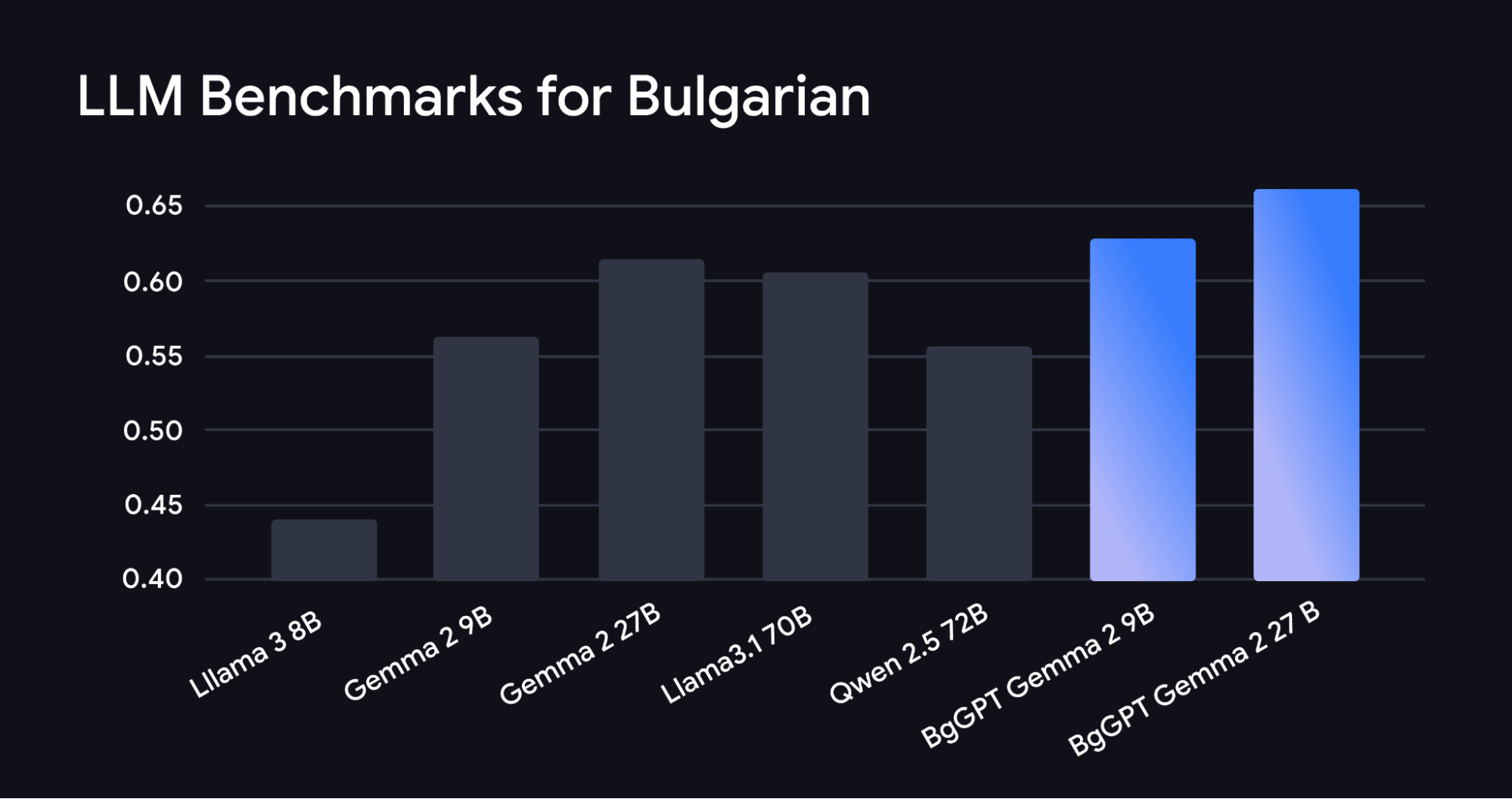
INSAIT の最新ブルガリア語モデルが示しているのは、他の言語にもスケーラブルなアプローチができることです。研究者たちは、約 850 億のトークンのブルガリア語による継続的な事前トレーニングなど、ベースとなる Gemma 2 モデルに多くの改善を加えました。また、自然言語処理を扱う有名な会議 EMNLP 2024 での新しい研究に基づき、新たな連続事前トレーニング、インストラクション ファインチューニング、モデル マージ スキームも導入しました。この研究では、AI モデルを新しいもの(ブルガリア語)でトレーニングすると、以前に学習したスキル(英語、数学)を忘れてしまう「壊滅的な忘却」を軽減するための新たな方法を利用しています。
「INSAITが示した結果は、ブルガリアほどの大きさの国でも、オープンモデル、高度なAI研究、特別なデータ取得とトレーニング技術に依存することで、独自の最先端のAIモデルを構築できることを目に見えて示しているため、重要です」チューリヒ工科大学の正教授であり、INSAIT の科学ディレクターである Martin Vechev 氏は次のように述べています。「私たちのモデルはブルガリア語をターゲットとしていますが、EMNLP 2024 で導入した分岐とマージの手法は、それを緩和するために行われています。壊滅的な忘却は新しい言語の習得にも当てはまります。」
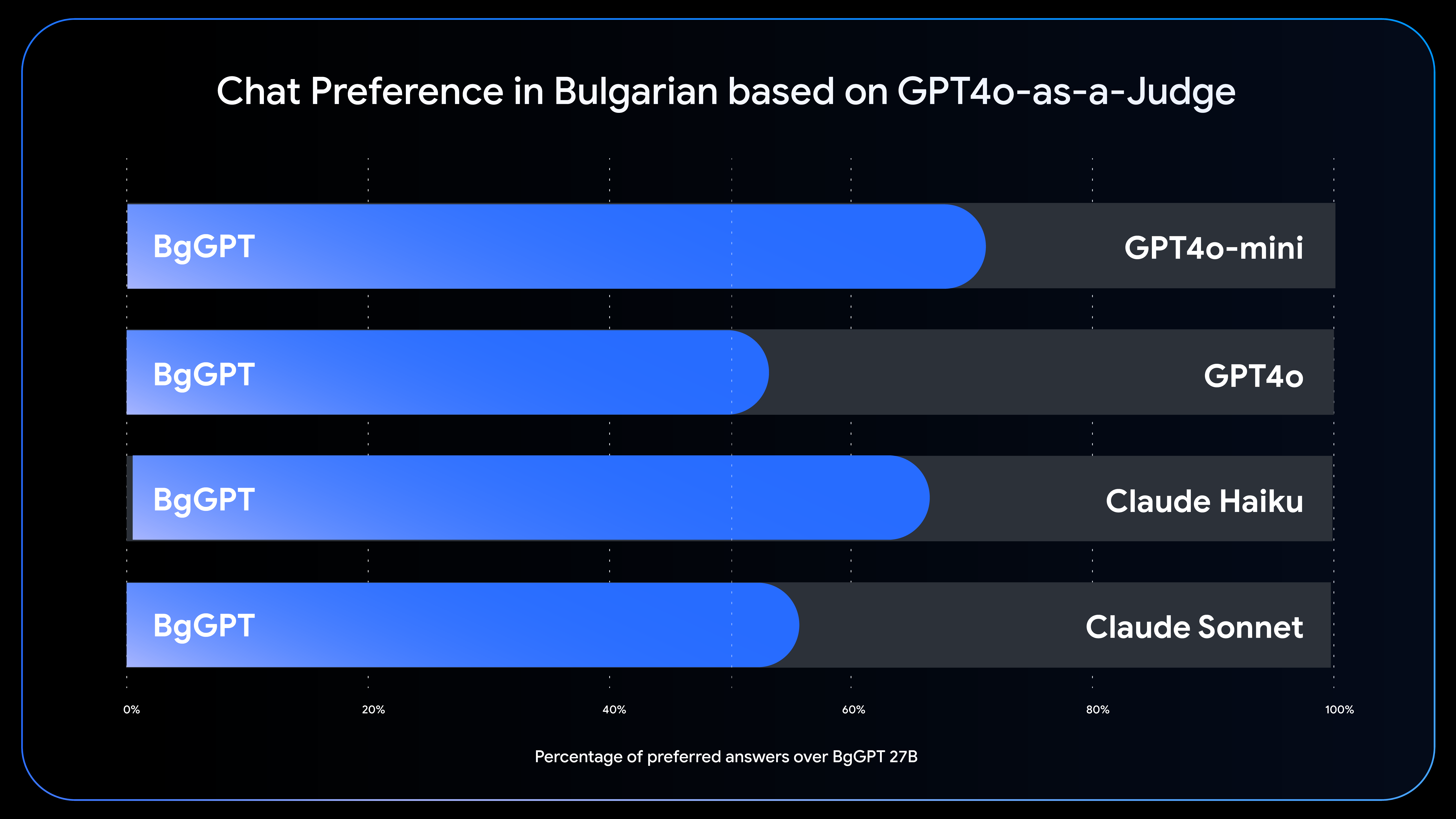
現在、INSAIT は高性能なブルガリア語モデルをオープンモデルとして公開し、無料でアクセスできるようにしています。それによって、ブルガリア国内の自然言語処理が進展し、AI ソリューションのローカライズに関心のある人々にチャンスが生まれています。また、INSAIT は、BgGPT-Gemma モデルのバリアントをベースとした全国パブリック チャット システムを立ち上げました。欧州の政府機関が、公的に利用できる無料のオープンな生成 AI モデルを使って全国規模のチャット システムを立ち上げたのは、これが初めてです。
AI Singapore と INSAIT がリリースしたオープンモデルは、すべての人が AI を利用できるようにして地域社会の可能性を広げることに向けた重要な一歩です。どちらのチームの事例も、多様な言語による AI ソリューションの開発が重要であること、そして Gemma のようなオープンモデル ソリューションを使えばそれを容易に実現できることを示すものです。
LLM をローカライズすることで生まれる可能性は計り知れません。うれしいことに、野心的なデベロッパーの皆さんは最新の AI 技術を使ってコミュニティに新しい機会を創出しています。そこで、このストーリーに触発された方々に Kaggle コンペティションへの参加を呼びかけています。このコンペティションで求められるのは、Gemma 2 オープンモデル ファミリーを 73 の対象言語に適応させることです。
言語にはたくさんの選択肢があるので、デベロッパーの皆さんが世界中のコミュニティのためにインクルーシブで優れた LLM を作成できるように、基本的なリソースやベスト プラクティスをまとめています。今すぐコンペティションに参加しましょう。最終提出期限は 2025 年 1 月 14 日です!

Gemini でマルチスペクトル データの可能性を引き出す

EmbeddingGemma の概要: オンデバイス埋め込み処理向けの最高水準オープンモデル

Building with Gemini 3 in Jules

Grain と ArrayRecord を使用した高性能データ パイプラインの構築

Gemma 3 270M の概要: 超高効率 AI のためのコンパクト モデル

Announcing the Data Commons Gemini CLI extension