

本日、Gemini 2.5 Flash の初期プレビュー版をロールアウトします。Google AI Studio の Gemini API と、Vertex AI から利用できます。この新しいバージョンは、人気の 2.0 Flash をベースとして開発されており、速度とコストを優先しながら、推論機能が大幅に向上しています。Gemini 2.5 Flash は、初めての完全なハイブリッド推論モデルであり、デベロッパーが思考のオン / オフを切り替えることができます。さらに、「思考予算」を設定して、品質、費用、レイテンシの間で適切なトレードオフを見つけることもできます。思考がオフの状態でも、2.0 Flash の高速性はそのままに、パフォーマンスが向上しています。
Gemini 2.5 モデルは思考モデルであり、応答する前に論理的に思考することができます。すぐに出力を生成するのではなく、「思考」プロセスを実行することで、プロンプトを深く理解し、複雑なタスクを分解して、応答の計画を立てることができます。複数の推論ステップを必要とする複雑なタスク(数学の問題を解く、研究の疑問点を分析するなど)で思考プロセスを使うと、正確で包括的な答えに到達できます。実際、Gemini 2.5 Flash は、LMArena の Hard Prompts で 2.5 Pro に次ぐ 2 位という高いパフォーマンスを発揮しています。
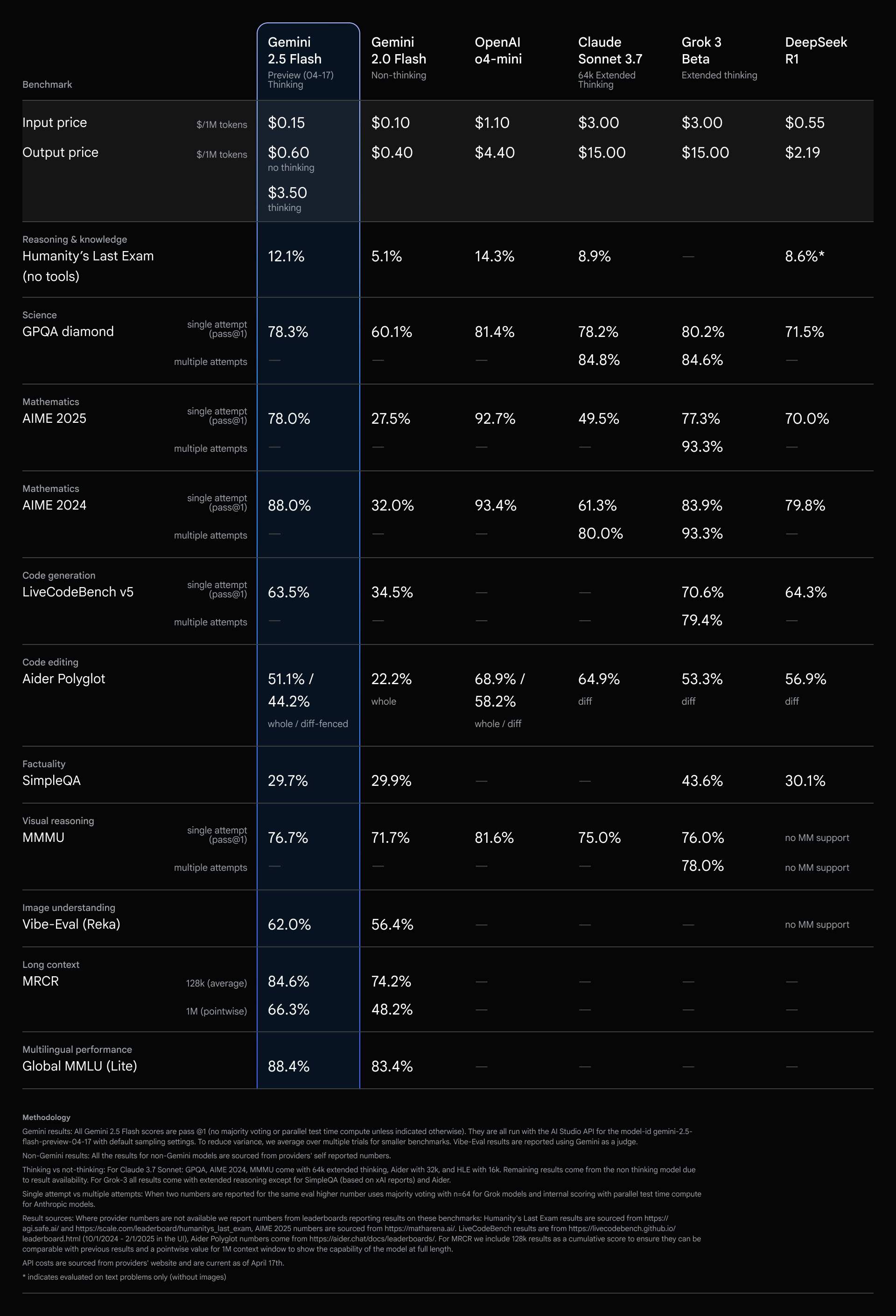
2.5 Flash は、最高の価格性能比を持つモデルであり続けています。
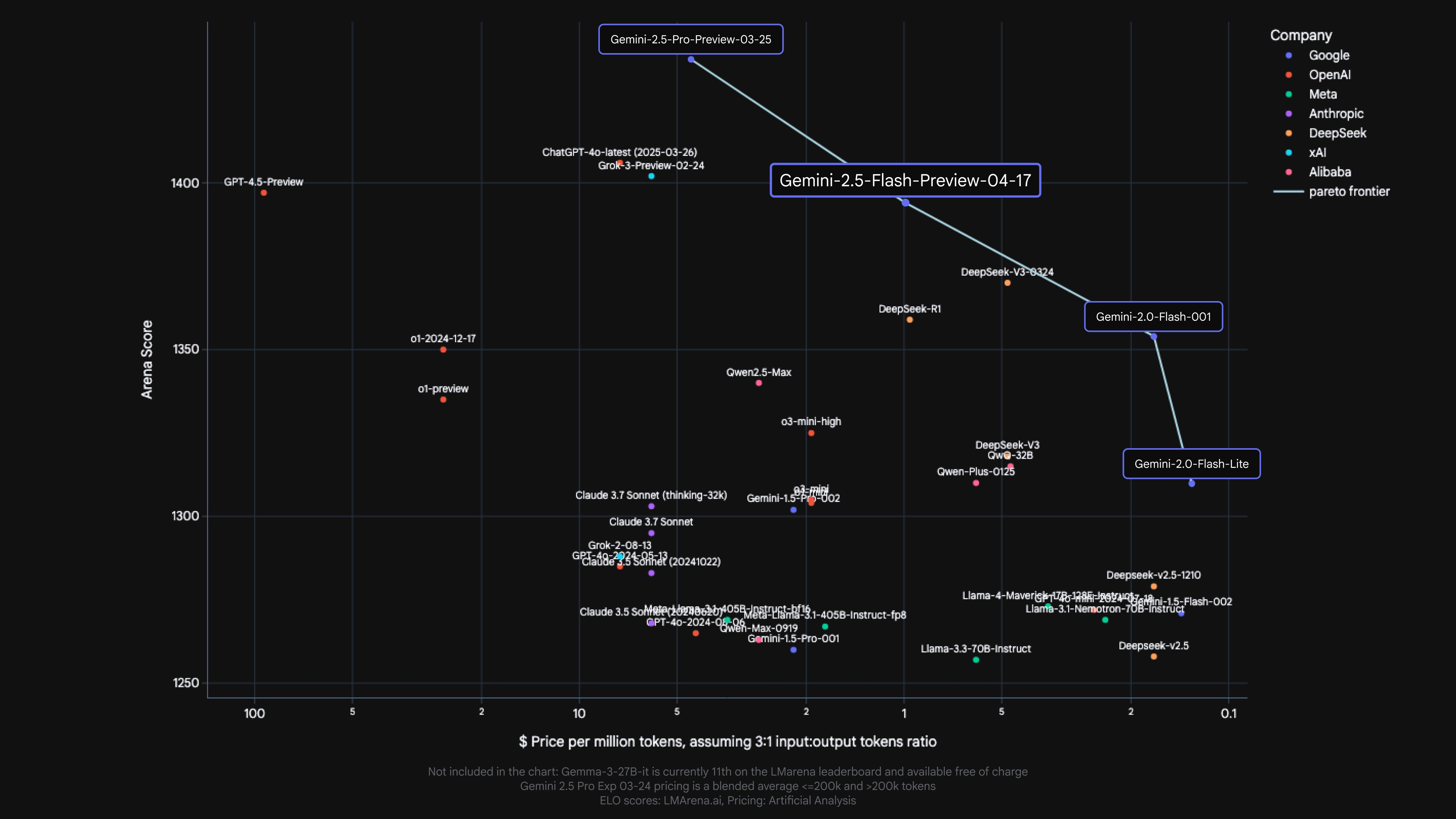
ご存じのように、品質、費用、レイテンシのトレードオフはユースケースによって異なります。そこで、デベロッパーに柔軟性を提供するため、思考予算を設定し、モデルが思考中に生成できるトークンの最大数を細かく制御できるようにしました。予算を増やせば、モデルは多くの推論を行って品質を上げることができます。ただし、重要な点は、予算により 2.5 Flash の思考量の上限が決まりますが、そこまでの思考が必要ないプロンプトの場合、モデルは予算を使い切らないことです。
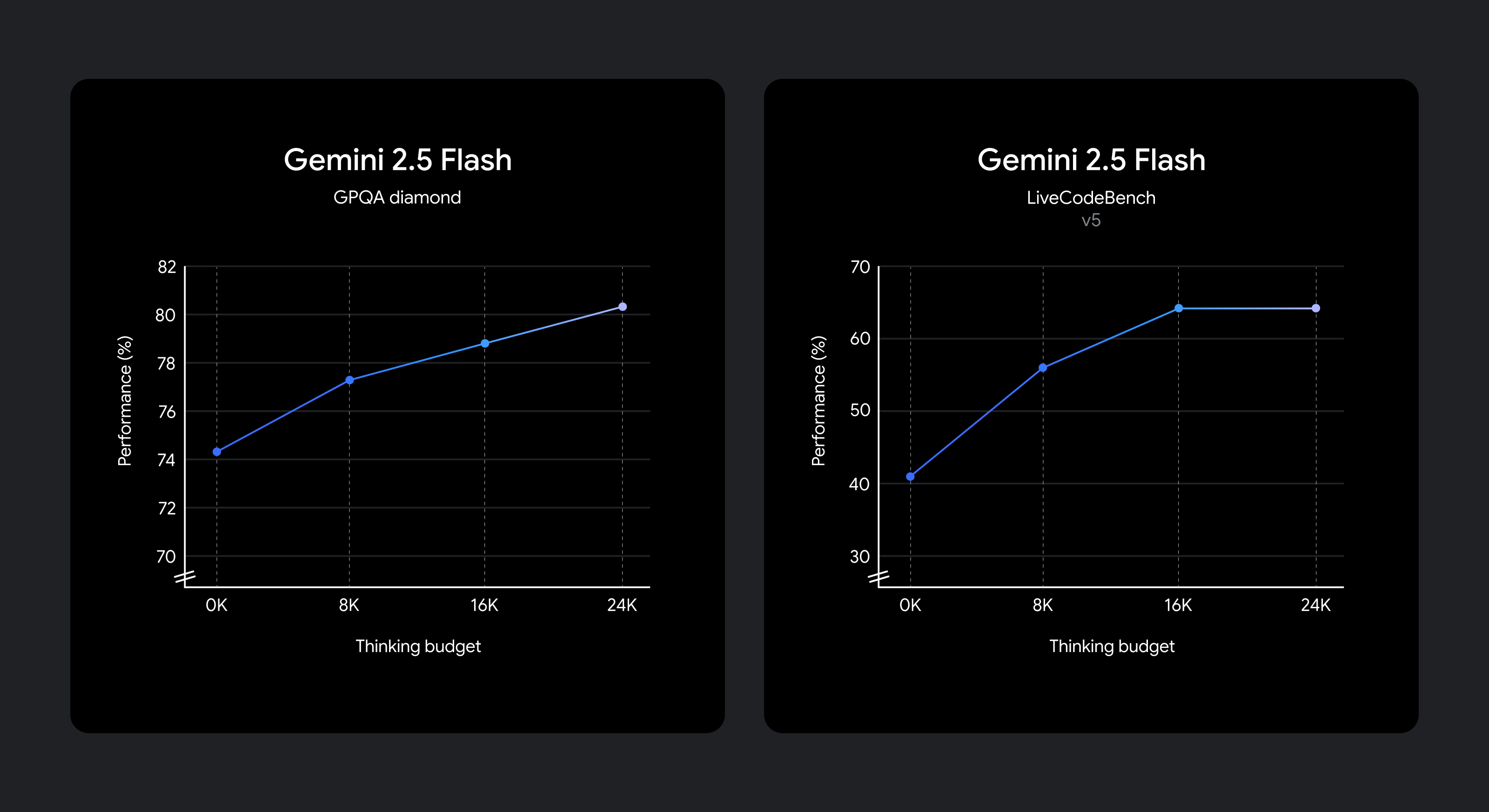
モデルは、与えられたプロンプトに対して、どれくらいの時間思考するかを判断できるようにトレーニングされているため、タスクの複雑さを認識し、それに基づいて思考する量を自動的に決定します。
2.0 Flash よりもパフォーマンスを向上させながら、費用とレイテンシを最小限に抑えたい場合は、思考予算を 0 に設定します。思考フェーズのトークン予算を細かく設定するには、API のパラメータか、Google AI Studio や Vertex AI のスライダーを使います。予算は、2.5 Flash のトークン数で、0~24576 の範囲で設定できます。
次のプロンプトは、2.5 Flash のデフォルト モードで、どれくらいの推論が行われるかを示しています。
例 1: スペイン語で「ありがとう」
例 2: カナダにはいくつの州がありますか?
例 1: サイコロを 2 つ振ります。合計すると 7 になる確率は?
例 2: 私のジムでは、バスケットボールのピックアップ時間が月水金は午前 9 時から午後 3 時、火曜日と土曜日は午後 2 時から 8 時です。週 5 日、午前 9 時から午後 6 時まで働き、平日に 5 時間バスケットボールをしたいのですが、すべてうまくいくようなスケジュールを作ってください。
例 1: 長さ L=3m の片持ち梁は、スチール(E=200 GPa)製で、断面が長方形(幅 b=0.1m、高さ h=0.2m)になっています。すべての部分に w=5 kN/m の均一な荷重がかかり、自由端には P=10 kN の点荷重がかかります。最大曲げ応力(σ_max)を計算してください。
例 2: スプレッドシートのセルの値を計算する関数 evaluate_cells(cells: Dict[str, str]) -> Dict[str, float] を書いてください。
各セルには以下が含まれています。
「3」)"=A1 + B1 * 2" のように、+、-、*、/ と他のセルが使われている式。要件:
+- よりも */ が優先)。ValueError("Cycle detected at <cell>") を発生させてください。eval() は使わず、組み込みライブラリのみを使ってください。思考機能を搭載した Gemini 2.5 Flash は、プレビュー版として、Google AI Studio の Gemini API か Vertex AI、または Gemini アプリの専用ドロップダウンから利用できます。thinking_budget パラメータを試し、推論の制御が複雑な問題の解決に役立つことを確認してみてください。
from google import genai
client = genai.Client(api_key="GEMINI_API_KEY")
response = client.models.generate_content(
model="gemini-2.5-flash-preview-04-17",
contents="You roll two dice. What’s the probability they add up to 7?",
config=genai.types.GenerateContentConfig(
thinking_config=genai.types.ThinkingConfig(
thinking_budget=1024
)
)
)
print(response.text)デベロッパー ドキュメントには、詳しい API リファレンスと思考ガイドが記載されています。Gemini クックブックのコードサンプルから始めることもできます。
Gemini 2.5 Flash の改善は今後も続きます。本番環境向けに一般公開する前に、さらなる改良版を近日中にお届けする予定です。
*モデルの価格は、Artificial Analysis と各社のドキュメントに基づいています。



