

오늘 Google AI Studio 및 Vertex AI에서 Gemini API를 통해 Gemini 2.5 Flash의 초기 버전을 미리보기로 선보입니다. 많은 인기를 끈 2.0 Flash의 기본 구조를 토대로 하는 이 새로운 버전은 속도와 비용을 우선시하면서도 추론 기능을 크게 업그레이드했습니다. Gemini 2.5 Flash는 개발자가 사고 기능을 설정하거나 해제할 수 있는 최초의 완전 하이브리드 추론 모델입니다. 또한 개발자는 이 모델을 통해 품질, 비용, 지연 시간 사이의 적절한 균형을 찾기 위해 사고 예산을 설정할 수 있습니다. 개발자가 사고 기능을 해제하더라도 2.0 Flash의 빠른 속도를 유지하고 성능을 향상시킬 수 있습니다.
Gemini 2.5 모델은 사고 모델로서, 응답하기 전에 생각을 통해 추론을 할 수 있습니다. 이 모델은 출력 결과를 즉시 생성하는 대신 프롬프트를 더 잘 이해하고 복잡한 작업을 세분화하며 응답을 계획하는 '사고' 과정을 수행할 수 있습니다. 여러 단계의 추론이 필요한 복잡한 과제(예: 수학 문제 풀기 또는 연구 질문 분석)에서 사고 과정을 통해 보다 정확하고 종합적인 답변에 도달할 수 있습니다. 실제로 Gemini 2.5 Flash는 LMArena의 하드 프롬프트에서 2.5 Pro에 이어 두 번째로 뛰어난 성능을 보여줍니다.
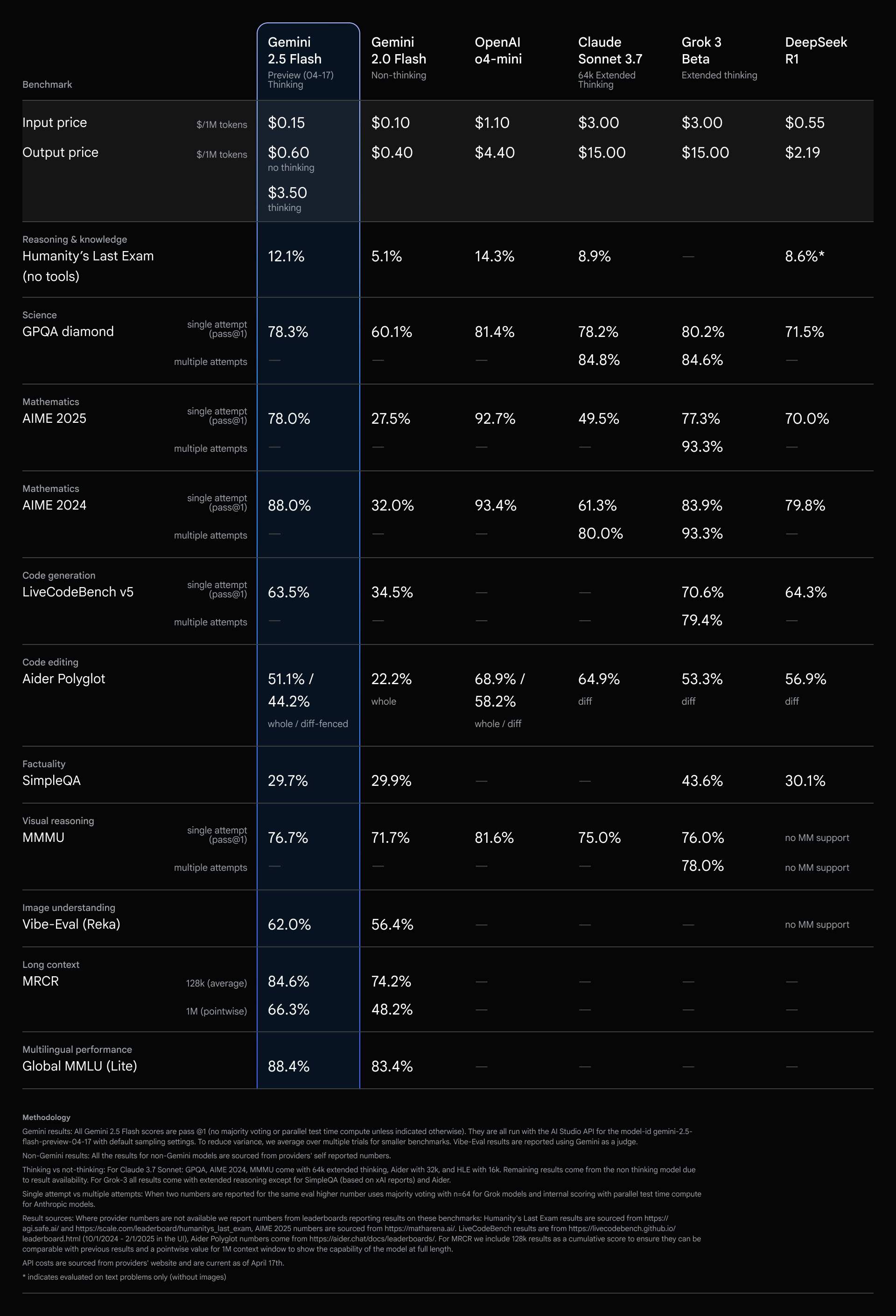
2.5 Flash는 가성비가 가장 좋은 모델로서 계속해서 선두를 달리고 있습니다.
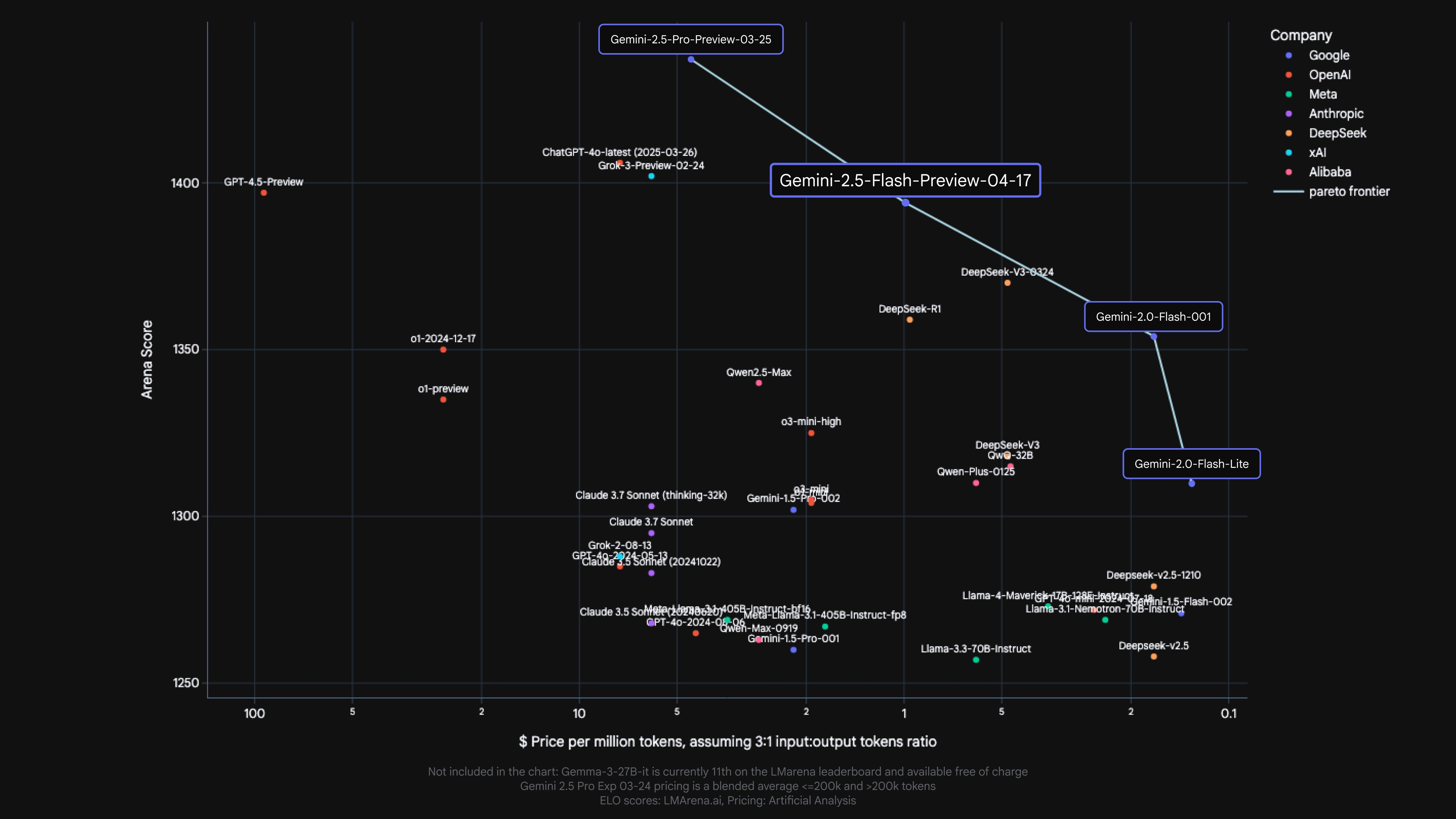
저희는 사용 사례마다 품질, 비용, 지연 시간에서 절충점이 다 다르다는 점을 알고 있습니다. 개발자에게 유연성을 제공하기 위해 사고 예산을 설정하여 모델이 사고하는 동안 생성할 수 있는 최대 토큰 수를 정밀하게 제어할 수 있도록 했습니다. 예산이 높을수록 모델은 품질을 개선하기 위해 더 많은 추론을 할 수 있습니다. 그러나 중요한 점은 예산에 따라 2.5 Flash가 생각할 수 있는 양이 제한되기는 하지만, 프롬프트가 필요로 하지 않을 경우 모델은 전체 예산을 사용하지는 않는다는 것입니다.
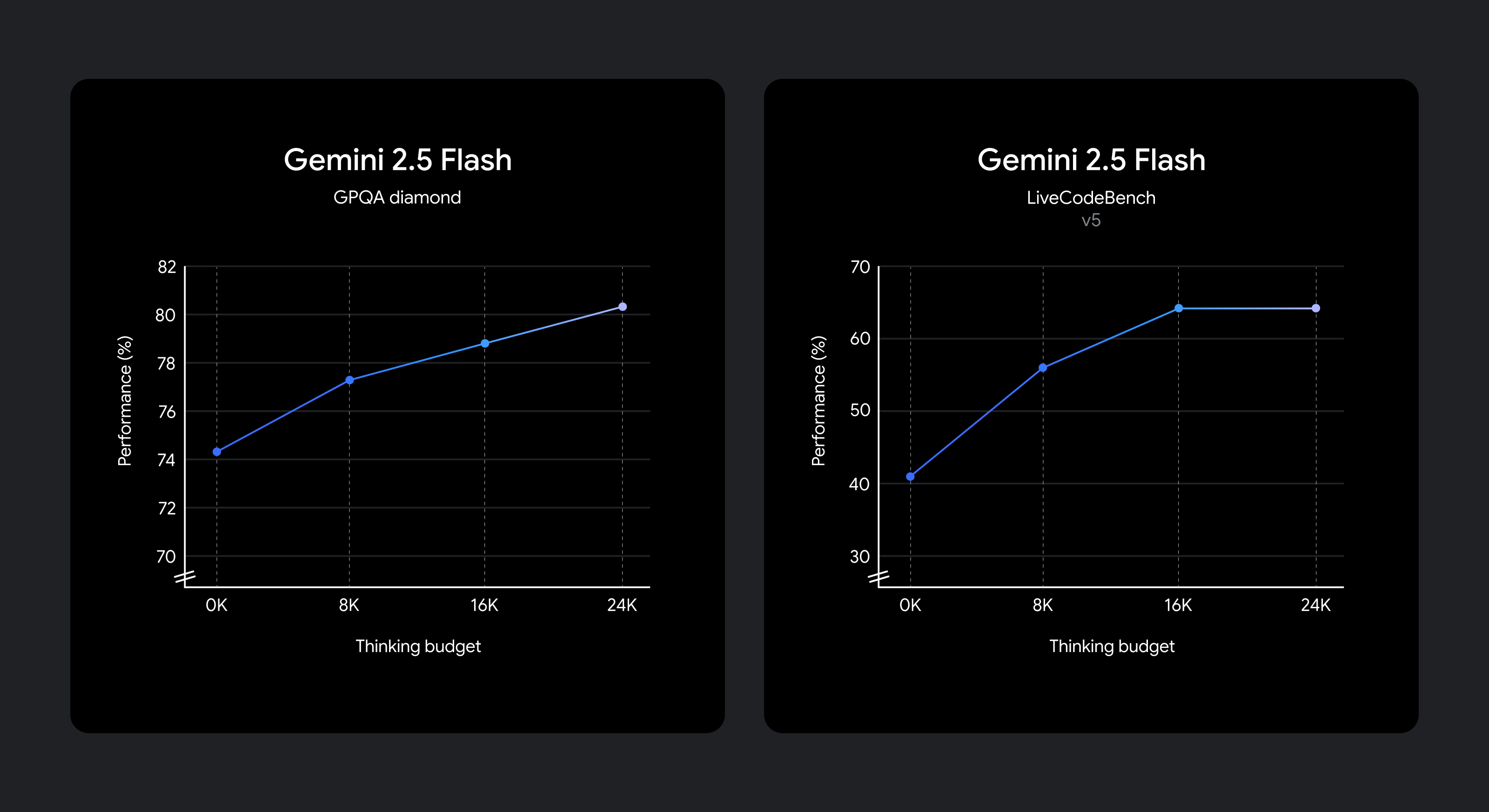
이 모델은 주어진 프롬프트에 대해 얼마나 오래 생각해야 하는지를 알 수 있도록 학습되므로, 인식된 작업의 복잡성에 따라 얼마나 많이 생각해야 할지 자동으로 결정합니다.
2.0 Flash보다 성능을 향상시키면서 비용과 지연 시간을 최소화하기 위해서는 사고 예산을 0으로 설정하세요. Google AI Studio와 Vertex AI의 API 또는 슬라이더에서 매개변수를 사용하여 사고 단계에 대한 특정 토큰 예산을 설정하도록 선택할 수도 있습니다. 2.5 Flash의 경우 예산 범위는 토큰 0에서 24,576개 사이입니다.
다음 프롬프트는 2.5 Flash의 기본 모드에서 얼마만큼의 추론이 사용 가능한지 보여줍니다.
예 1: '감사합니다'를 스페인어로
예 2: 캐나다에는 주가 몇 개나 있어?
예 1: 주사위 두 개를 굴릴 때 합이 7이 될 확률은 얼마야?
예 2: 내가 다니는 체육관에서는 즉석 농구 게임을 할 수 있는 시간이 월, 수, 금 오전 9시~오후 3시, 화요일과 토요일에는 오후 2시~오후 8시로 정해져 있어. 한 주에 5일간 오전 9시~오후 6시까지는 직장에서 일하면서 평일에 5시간 농구를 하고 싶은데 모든 것이 순조롭게 이루어지도록 일정을 짜 줘.
예 1: 길이 L=3m인 캔틸레버 기둥의 단면은 직사각형(너비 b = 0.1m, 높이 h = 0.2m)이고 재질은 강철(E = 200GPa)이야. 기둥의 전체 길이를 따라 w=5kN/m의 하중이 균일하게 분포되고 자유단에서 P=10kN의 점하중이 작용해. 이때 최대 굽힘 응력(σ_max)을 계산해 줘.
예 2: 스프레드시트 셀의 값을 계산하는 evaluate_cells(cells: Dict[str, str]) -> Dict[str, float] 함수를 작성해 줘.
각 셀에는 다음 내용이 포함돼.
'3')+, -, *,/ 및 기타 셀을 사용하는 "=A1 + B1 * 2"와 같은 수식.요구 사항:
*/ 연산 다음에 +- 연산).ValueError("Cycle detected at <cell>")를 발생시킬 것.eval() 사용 금지. 기본 제공 라이브러리만 사용할 것.사고 기능을 갖춘 Gemini 2.5 Flash는 이제 Google AI Studio와 Vertex AI의 Gemini API 및 Gemini 앱의 전용 드롭다운에서 미리보기로 제공됩니다. thinking_budget 매개변수를 실험해 보고 제어 가능한 추론이 더 복잡한 문제를 해결하는 데 어떤 도움을 줄 수 있는지 알아보세요.
from google import genai
client = genai.Client(api_key="GEMINI_API_KEY")
response = client.models.generate_content(
model="gemini-2.5-flash-preview-04-17",
contents="You roll two dice. What’s the probability they add up to 7?",
config=genai.types.GenerateContentConfig(
thinking_config=genai.types.ThinkingConfig(
thinking_budget=1024
)
)
)
print(response.text)개발자 문서에서 자세한 API 참조 자료와 사고 가이드를 찾아보거나 Gemini Cookbook의 코드 예제로 시작해 보세요.
Gemini 2.5 Flash는 완전히 프로덕션용으로 정식 출시되기 전에 지속적인 개선을 통해 더 많은 기능을 추가할 것입니다.
*모델 가격 출처: Artificial Analysis & Company Documentation



