

大変うれしいお知らせです。デベロッパーの皆さんが、新しいオンデバイス生成 AI モデルをエッジデバイスにシームレスに導入できるようになります。このニーズを満たすためにお知らせするのが、AI Edge Torch Generative API です。この API を使うと、PyTorch で高パフォーマンス LLM をオーサリングし、TensorFlow Lite(TFLite)ランタイムで利用できるようにするためにデプロイできます。本記事は、Google AI Edge のデベロッパー リリースを紹介するシリーズの 2 つ目のブログ投稿です。シリーズの最初の投稿では、Google AI Edge Torch を紹介しました。Google AI Edge Torch は、モバイル デバイスで TFLite ランタイムを使った PyTorch モデルの高パフォーマンス推論を実現する仕組みでした。
デベロッパーが AI Edge Torch Generative API を使うと、要約やコンテンツ生成などの強力な新しい機能をオンデバイスで実現できます。私たちは、すでに MediaPipe LLM Inference API によって人気の高い LLM をデバイスに導入できるようにしています。デベロッパーの皆さんは、さまざまな対応モデルをオンデバイスに導入し、高パフォーマンスで動作させることができるようになります。AI Edge Torch Generative API の初期バージョンでは、次の機能を提供します。
このブログ投稿では、パフォーマンス、移植性、オーサリングのデベロッパー エクスペリエンス、エンドツーエンドの推論パイプライン、デバッグ ツールチェーンについて詳しく説明します。詳しいドキュメントやサンプルは、こちらをご覧ください。
私たちのチームは、特に人気の高い LLM を MediaPipe LLM Inference API でシームレスに動作させる作業を行っています。その一環として、デバイスのパフォーマンスを向上させる最新技術を駆使しながら、完全に手書きのトランスフォーマーをいくつかオーサリングしました(MediaPipe LLM Inference API ブログ)。この作業を通して、いくつかのテーマが明らかになりました。具体的に挙げると、アテンションを効率的に表現する方法、量子化の利用、優れた KV キャッシュ表現の重要性です。Generative API を使えば、これらを簡単に表現できます(次のセクションで説明します)。同時に、手書きバージョンの 90% 以上に相当するパフォーマンスを実現できるので、デベロッパーの作業ははるかに速くなります。
次の表は、3 つのモデル例の主要ベンチマークを示しています。
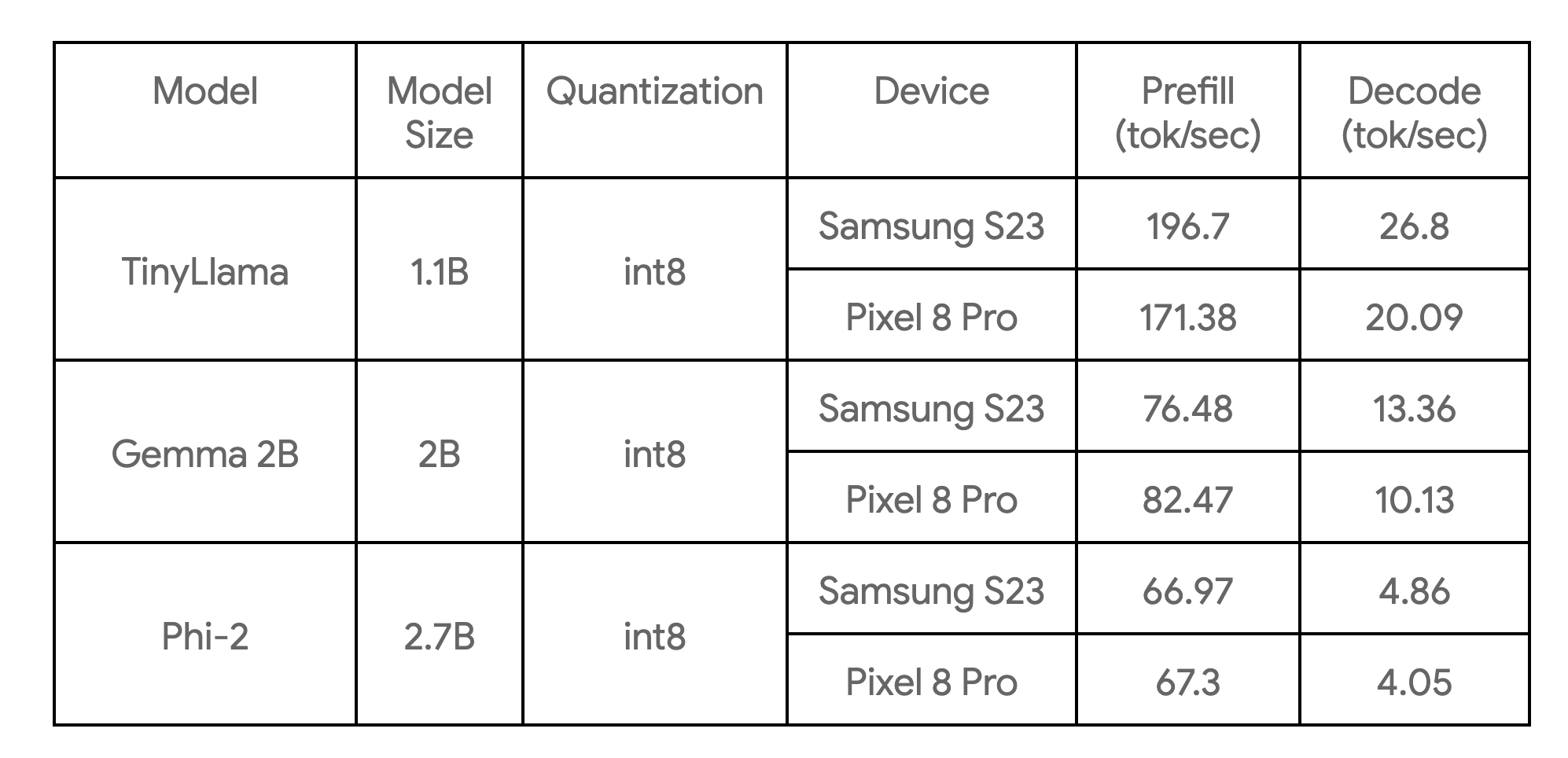
このベンチマークは、4 つの CPU スレッドがある大型コアで実行したものです。私たちが知る限り、記載されているデバイスにおける各モデルの最も高速な CPU 実装となっています。
コア オーサリング ライブラリは、一般的なトランスフォーマー モデル(エンコーダのみ、デコーダのみ、エンコーダ - デコーダ スタイルなど)の基本的な構成要素を提供します。モデルをゼロからオーサリングすることも、既存のモデルを再オーサリングしてパフォーマンスを向上させることもできます。ほとんどのユーザーには、再オーサリングをお勧めしています。この方法だと、トレーニングやファイン チューニングの手順が不要になるからです。Generative API オーサリングの主な利点は次のとおりです。
例として、新しい Generative API と 50 行ほどの Python を使って TinyLLama (1.1B)のコア機能を再オーサリングする方法を紹介します。
ステップ 1: モデルの構造を定義する
import torch
import torch.nn as nn
from ai_edge_torch.generative.layers.attention import TransformerBlock
import ai_edge_torch.generative.layers.attention_utils as attn_utils
import ai_edge_torch.generative.layers.builder as builder
import ai_edge_torch.generative.layers.model_config as cfg
class TinyLLamma(nn.Module):
def __init__(self, config: cfg.ModelConfig):
super().__init__()
self.config = config
# モデルのレイヤーを組み立てる。
self.lm_head = nn.Linear(
config.embedding_dim, config.vocab_size, bias=config.lm_head_use_bias
)
self.tok_embedding = nn.Embedding(
config.vocab_size, config.embedding_dim, padding_idx=0
)
self.transformer_blocks = nn.ModuleList(
TransformerBlock(config) for _ in range(config.num_layers)
)
self.final_norm = builder.build_norm(
config.embedding_dim,
config.final_norm_config,
)
self.rope_cache = attn_utils.build_rope_cache(
size=config.kv_cache_max,
dim=int(config.attn_config.rotary_percentage * config.head_dim),
base=10_000,
condense_ratio=1,
dtype=torch.float32,
device=torch.device("cpu"),
)
self.mask_cache = attn_utils.build_causal_mask_cache(
size=config.kv_cache_max, dtype=torch.float32, device=torch.device("cpu")
)
self.config = configステップ 2: モデルの forward 関数を定義する
@torch.inference_mode
def forward(self, idx: torch.Tensor, input_pos: torch.Tensor) -> torch.Tensor:
B, T = idx.size()
cos, sin = self.rope_cache
cos = cos.index_select(0, input_pos)
sin = sin.index_select(0, input_pos)
mask = self.mask_cache.index_select(2, input_pos)
mask = mask[:, :, :, : self.config.kv_cache_max]
# モデル自体を順伝搬する
x = self.tok_embedding(idx) # トークン エンベディングの形状は (b, t, n_embd)
for i, block in enumerate(self.transformer_blocks):
x = block(x, (cos, sin), mask, input_pos)
x = self.final_norm(x)
res = self.lm_head(x) # (b, t, vocab_size)
return resステップ 3: 旧モデルの重みをマッピングする
このライブラリでは、ModelLoader API を使って簡単に重みをマッピングできます。たとえば、次のようにします。
import ai_edge_torch.generative.utilities.loader as loading_utils
# このマッピングで、古いテンソル名と新しいモデルを関連付ける。
TENSOR_NAMES = loading_utils.ModelLoader.TensorNames(
ff_up_proj="model.layers.{}.mlp.up_proj",
ff_down_proj="model.layers.{}.mlp.down_proj",
ff_gate_proj="model.layers.{}.mlp.gate_proj",
attn_query_proj="model.layers.{}.self_attn.q_proj",
attn_key_proj="model.layers.{}.self_attn.k_proj",
attn_value_proj="model.layers.{}.self_attn.v_proj",
attn_output_proj="model.layers.{}.self_attn.o_proj",
pre_attn_norm="model.layers.{}.input_layernorm",
pre_ff_norm="model.layers.{}.post_attention_layernorm",
embedding="model.embed_tokens",
final_norm="model.norm",
lm_head="lm_head",
)以上のステップを終えると、いくつかのサンプルを入力して、再オーサリングしたモデルが数値的にどの程度正確かを検証できるようになります(リンクを参照)。数値チェックに問題がなければ、変換と量子化のステップに進むことができます。
ai_edge_torch の変換 API では、同じ API を使ってトランスフォーマー モデルを高度に最適化された TensorFlow Lite モデルに変換(再オーサリング)できます。変換プロセスの主な手順は次のとおりです。
1) StableHLO にエクスポートします。PyTorch モデルは、torch の dynamo コンパイラによってトレースされ、Aten オペレーションを含む FX グラフにコンパイルされます。その後、ai_edge_torch によって軽量化され、StableHLO グラフになります。
2) ai_edge_torch により、StableHLO に対して他のコンパイラパスがさらに実行されます。これには、オペレーションの融合や折り畳みなどが含まれます。その結果、高パフォーマンスな TFLite フラットバッファが生成されます(SDPA、KVCache 用の融合オペレーションが含まれます)。
コア Generative API ライブラリでは、一連の量子化 API も提供されており、これによって一般的な LLM 量子化レシピに対応しています。レシピは ai_edge_torch コンバータ API に追加パラメータとして渡され、API が自動的に量子化を行います。今後のリリースで、利用できる量子化モードを拡大する予定です。
私たちが突き止めたのは、実際の推論シナリオで LLM モデルが最高のパフォーマンスを発揮するには、明確に分離(分解)された推論関数(プレフィル、デコード)が必要なことでした。これが明らかになった一因は、プレフィルやデコードで異なる形状のテンソルを受け取る可能性があり、プレフィルは計算バウンドであるにもかかわらず、デコードはメモリバウンドであることがわかったことにあります。大規模な LLM では、プレフィルとデコードでモデルの重みが重複しないようにすることが重要です。これは、TFLite と ai_edge_torch の既存のマルチシグネチャ機能を使用して実現します。マルチシグネチャ機能とは、モデルの複数のエントリ ポイントを簡単に定義する機能です。次の例をご覧ください。
def convert_tiny_llama_to_tflite(
prefill_seq_len: int = 512,
kv_cache_max_len: int = 1024,
quantize: bool = True,
):
pytorch_model = tiny_llama.build_model(kv_cache_max_len=kv_cache_max_len)
# 変換時にモデルのグラフのトレースに使うテンソル。
prefill_tokens = torch.full((1, prefill_seq_len), 0, dtype=torch.long)
prefill_input_pos = torch.arange(0, prefill_seq_len)
decode_token = torch.tensor([[0]], dtype=torch.long)
decode_input_pos = torch.tensor([0], dtype=torch.int64)
# モデルの量子化を設定する。
quant_config = quant_recipes.full_linear_int8_dynamic_recipe() if quantize else None
edge_model = (
ai_edge_torch.signature(
'prefill', pytorch_model, (prefill_tokens, prefill_input_pos)
)
.signature('decode', pytorch_model, (decode_token, decode_input_pos))
.convert(quant_config=quant_config)
)
edge_model.export(f'/tmp/tiny_llama_seq{prefill_seq_len}_kv{kv_cache_max_len}.tflite')パフォーマンス調査フェーズでは、LLM のパフォーマンスを向上させる上で重要になるいくつかの点が見つかりました。
1) 高パフォーマンスな SDPA と KVCache: これらの機能の精細なオペレーションを考慮したところ、コンパイラによる最適化や融合が十分でない場合、変換後の TFLite モデルが優れたパフォーマンスを発揮しないことがわかりました。この点に対処するため、高レベルな機能境界と StableHLO コンポジット オペレーションを導入しました。
2) TFLite の XNNPack デリゲートを活用した SDPA のさらなる高速化: 重い MatMul/Matrix ベクトル演算を確実に最適化することが不可欠です。XNNPack ライブラリでは、これらのプリミティブがさまざまなモバイル CPU で優れたパフォーマンスを発揮できるようになっています。
3) 無駄な計算の回避: 静的形状モデルでは、プレフィル ステージで長いサイズの固定メッセージを入力したり、デコード ステージで大きい固定シーケンス長を処理したりする場合、計算量が最低限必要とされる量よりも多くなる場合があります。
4) 実行時のメモリ使用量: TFLite の XNNPack デリゲートに重みのキャッシュと事前パッキングのメカニズムを導入し、ピークメモリ使用量を大幅に削減しました。
通常、LLM 推論には、多くの前処理および後処理の手順、高度なオーケストレーションが含まれます。たとえば、トークン化やサンプリング、自己回帰復号ロジックなどがこれに当たります。そこで、MediaPipe ベースのソリューションと純粋な C++ 推論の例の両方を提供します。
MediaPipe LLM Inference API は、プロンプトイン / プロンプトアウト インターフェースによる LLM 推論をサポートする高レベル API です。複雑な LLM パイプライン実装のすべてに対処してくれるので、デプロイははるかに簡単かつスムーズになります。MP LLM Inference API を使ってデプロイを行うには、期待されるプレフィルとデコード シグネチャを使ってモデルを変換し、バンドルを作成します。次のコードで例を示します。
def bundle_tinyllama_q8():
output_file = "PATH/tinyllama_q8_seq1024_kv1280.task"
tflite_model = "PATH/tinyllama_prefill_decode_hlfb_quant.tflite"
tokenizer_model = "PATH/tokenizer.model"
config = llm_bundler.BundleConfig(
tflite_model=tflite_model,
tokenizer_model=tokenizer_model,
start_token="<s>",
stop_tokens=["</s>"],
output_filename=output_file,
enable_bytes_to_unicode_mapping=False,
)
llm_bundler.create_bundle(config)エンドツーエンドでテキスト生成を行う例として、使いやすい C++ の例(MediaPipe への依存関係はありません)も提供しています。この例を参考に、エクスポートしたモデルを専用の本番環境パイプラインや要件に組み込むことで、カスタマイズ性と柔軟性を向上させることができます。
コア推論ランタイムは TFLite の中に存在するため、一切変更を行うことなく、パイプライン全体を Android(Google Play の一部)アプリにも iOS アプリにも簡単に組み込むことができます。そのため、新しい Generative API で変換したモデルは、いくつかのカスタム オペレーションへの依存関係を追加するだけで、すぐにデプロイできます。今後のリリースでは、Android と iOS、ターゲット ML アクセラレータ(TPU、NPU)の両方で、GPU をサポートする予定です。
最近発表したモデル エクスプローラは、Gemma 2B などの大型モデルを視覚化できる便利なツールです。階層表示や並べて比較する機能を使うと、オリジナル、再オーサリング後、変換後のバージョンのモデルを簡単に視覚化できます。これに関する詳しい情報や、パフォーマンス チューニング用にベンチマーク情報を視覚化する方法については、こちらのブログ投稿をご覧ください。
次に示すのは、これを使って PyTorch TinyLlama モデルをオーサリングする例です。PyTorch export() モデルと TFLite モデルが表示されています。モデル エクスプローラを使うと、各レイヤー(RMSNorms、SelfAttention など)の表現を簡単に比較できます。
AI Edge Torch Generative API は、Mediapipe LLM Inference API で利用できる最適化済みの既成モデルの強力なコンパニオンです。オンデバイスで独自の生成 AI モデルを利用したいデベロッパーは、これを利用することができます。今後数か月で、ウェブのサポート、量子化の改善、CPU 以外のさまざまなコンピューティングのサポートなど、新しいアップデートを予定しています。また、より良い形でフレームワークと連携させたいとも考えています。
これは、ライブラリの早期プレビュー版で、デベロッパー コミュニティとの交流のきっかけにするための試験運用の段階にあります。API は今後変更される可能性があるほか、まだ荒削りな部分があり、量子化やモデルのサポートが限定的であることをご了承ください。しかし、GitHub リポジトリには、使い始める上で参考となるものがたくさんあります。PR、問題、機能リクエストは遠慮なくお寄せください。
このシリーズのパート 3 では、モデルの視覚化、デバッグ、探索を行えるモデル エクスプローラ視覚化ツールについて詳しく見ていきます。
この作業は、Google のさまざまな部門のチームが力を合わせた成果です。この作業に貢献してくださったチームメンバー全員、Aaron Karp、Advait Jain、Akshat Sharma、Alan Kelly、Andrei Kulik、Arian Afaian、Chun-nien Chan、Chuo-Ling Chang、Cormac Brick、Eric Yang、Frank Barchard、Gunhyun Park、Han Qi、Haoliang Zhang、Ho Ko、Jing Jin、Joe Zoe、Juhyun Lee、Kevin Gleason、Khanh LeViet、Kris Tonthat、Kristen Wright、Lin Chen、Linkun Chen、Lu Wang、Majid Dadashi、Manfei Bai、Mark Sherwood、Matthew Soulanille、Matthias Grundmann、Maxime Brénon、Michael Levesque-Dion、Mig Gerard、Milen Ferev、Mohammadreza Heydary、Na Li、Paul Ruiz、Pauline Sho、Pei Zhang、Ping Yu、Pulkit Bhuwalka、Quentin Khan、Ram Iyengar、Renjie Wu、Rocky Rhodes、Sachin Kotwani、Sandeep Dasgupta、Sebastian Schmidt、Siyuan Liu、Steven Toribio、Suleman Shahid、Tenghui Zhu、T.J. Alumbaugh、Tyler Mullen、Weiyi Wang、Wonjoo Lee、Yi-Chun Kuo、Yishuang Pang、Yu-hui Chen、Zoe Wang、Zichuan Wei に感謝を捧げます。

Google AI Edge Gallery: 音声サポートが追加され Google Play で利用可能に

Announcing User Simulation in ADK Evaluation

マルチモダリティ、RAG、および関数呼び出しに対応したオンデバイス小型言語モデル

LiteRT: シンプルさとパフォーマンスが向上

LiteRT-LM を活用した Chrome、Chromebook Plus、Google Pixel Watch でのオンデバイス生成 AI

Announcing the Agent Development Kit for Go: Build Powerful AI Agents with Your Favorite Languages