

Today we announced exciting updates that make Gemini 2.0 available to more developers and production use. The following models are now available in the Gemini API via Google AI Studio and in Vertex AI:
Together with the recently-launched Gemini 2.0 Flash Thinking Experimental, our Flash variant that reasons before answering, these releases make Gemini 2.0 capabilities available to a broad range of use cases and applications.
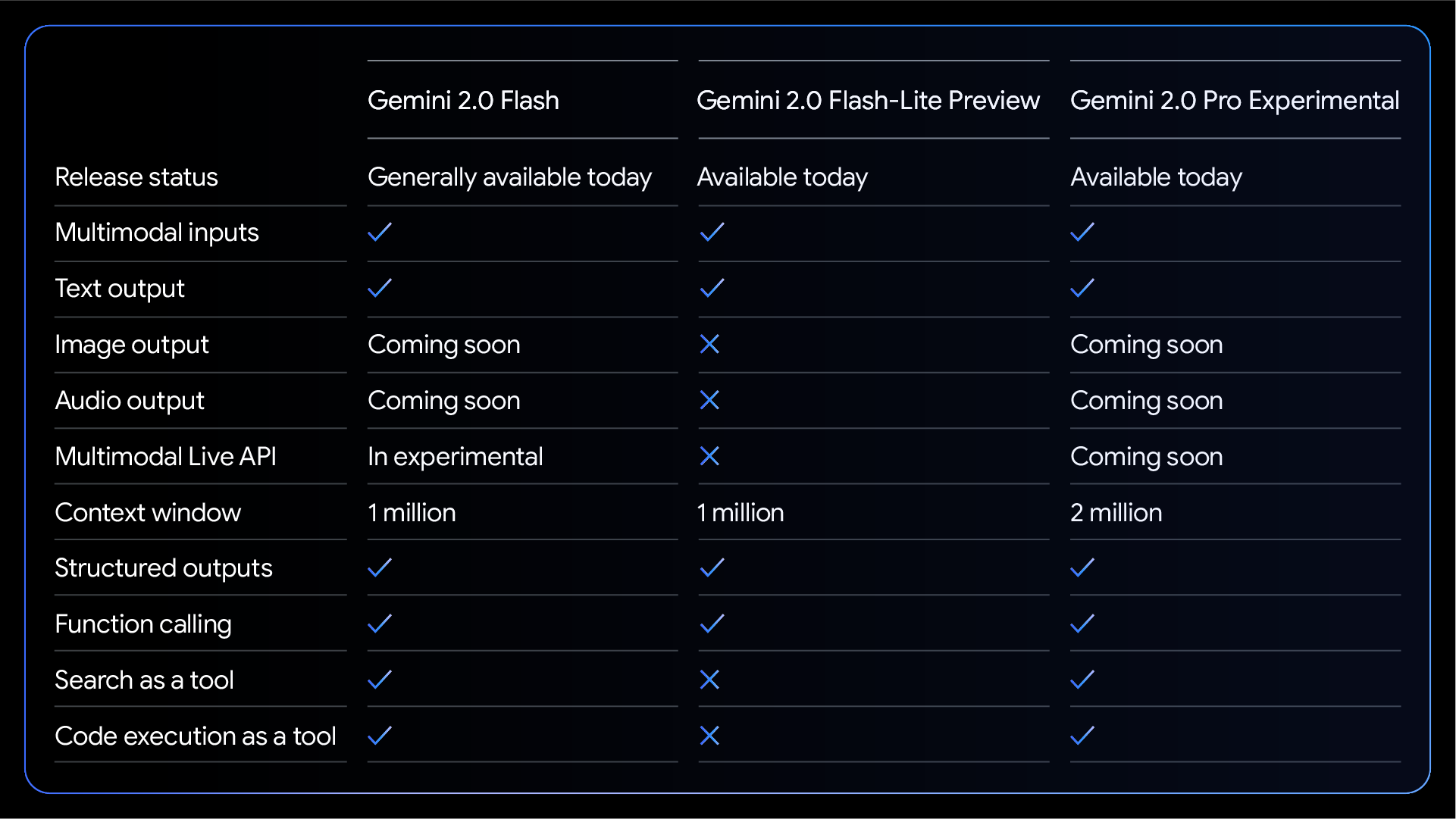
Gemini 2.0 Flash offers a comprehensive suite of features, including native tool use, a 1 million token context window, and multimodal input. It currently supports text output, with image and audio output capabilities and the Multimodal Live API planned for general availability in the coming months. Gemini 2.0 Flash-Lite is cost-optimized for large scale text output use cases.
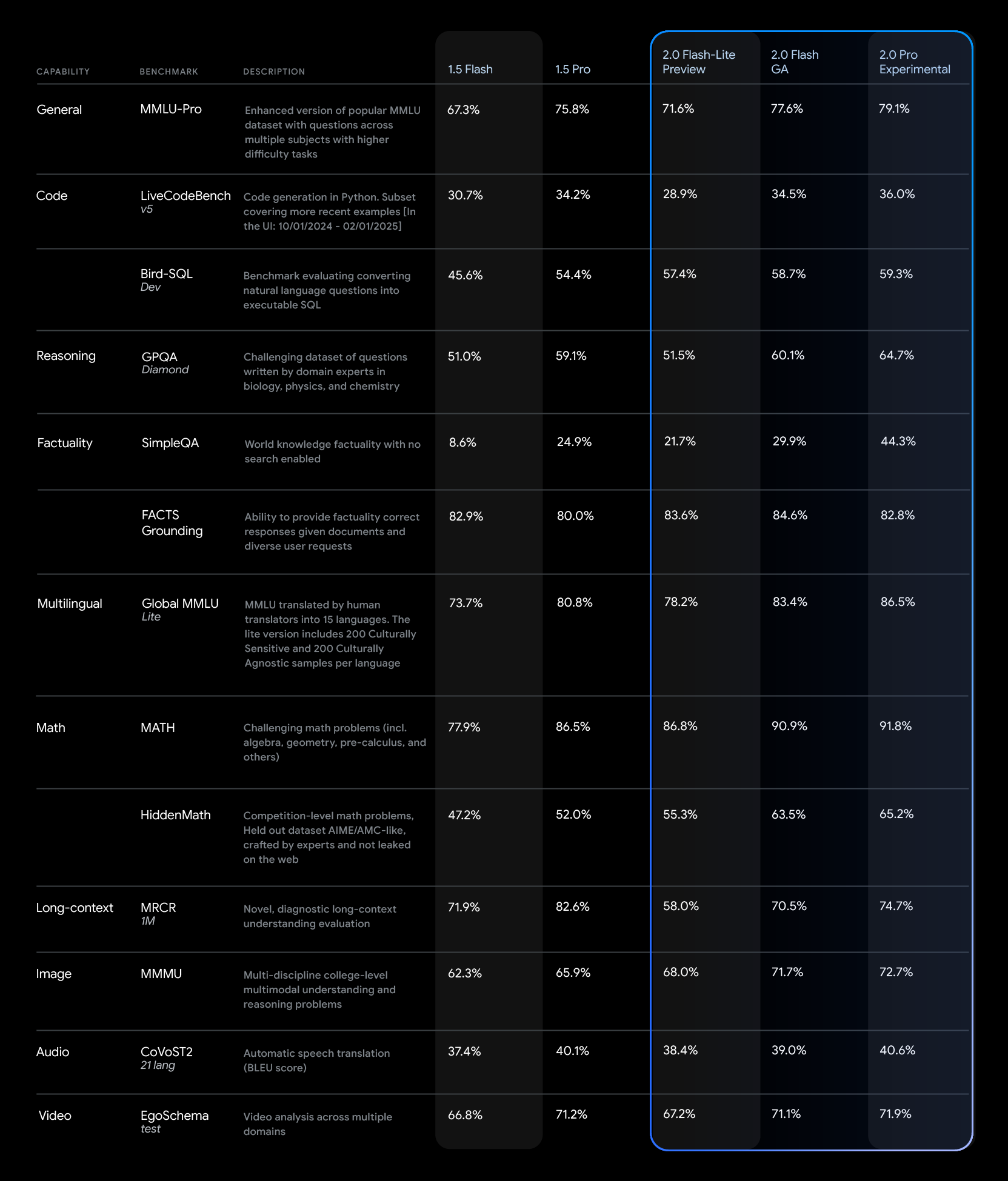
The Gemini 2.0 models deliver significant performance improvements over Gemini 1.5 across a range of benchmarks.
As with prior models, Gemini 2.0 Flash defaults to a concise style that makes it easier to use and reduces cost. It can also be prompted to use a more verbose style that produces better results in chat-oriented use cases.
We continue to reduce costs with Gemini 2.0 Flash and 2.0 Flash-Lite. Both have a single price per input type, removing the Gemini 1.5 Flash distinction between short and long context requests. This means the cost of both 2.0 Flash and Flash-Lite can be lower than Gemini 1.5 Flash with mixed-context workloads, despite the performance improvements that both deliver.

Follow these links to learn more about token counting for different modalities, about Gemini Developer API pricing, and about Vertex AI pricing.
You can start building with the latest Gemini models in four lines of code, with an industry leading free tier and rate limits to scale to production. We’re inspired by your progress thus far and can’t wait to see how you will use these latest Gemini models. Happy building!

Scaling Agentic RL: High-Throughput Agentic Training with Tunix

Run Ray on TPU, Part 1: The foundations
Run Ray on TPU, Part 2: Ray AI libraries

Turn creative prompts into interactive XR experiences with Gemini

How we built the Google I/O 2026 Save the Date experience